






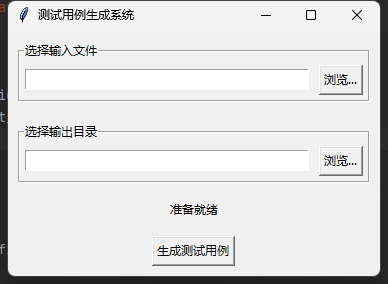
先展示整体结构跟效果!

这里xlsx中的数据是可以自行定义的,让大模型返回什么,写出对应的提示词即可
以下是我的提示词文件内容
from langchain_openai import ChatOpenAI
from config import OPENAI_API_KEY, MODEL_NAME, BASE_URL
def analyze_document(content):
try:
prompt = f"""请从以下产品需求文档中分析测试要点:{content}
请严格按以下结构返回JSON格式:
1. 功能点:["...","..."]
2. 业务规则(列出关键判断逻辑):["...","..."]
3. 测试步骤(可以分成2-8步分情况而定):["1、... 2、....","3、...","1、... 2、....","3、..."]
测试步骤的value中要标明1、2、3....的步骤顺序
括号里的内容只是表示要求的内容,返回时不需要返回
以上的功能的、业务规则、测试步骤的json的value列表中的数量要一致,一个功能点对应一个业务规则对应一套测试步骤
"""
llm = ChatOpenAI(
api_key=OPENAI_API_KEY, # 如果您没有配置环境变量,请用百炼API Key将本行替换为:api_key="sk-xxx"
base_url=BASE_URL, # 填写DashScope base_url
model=MODEL_NAME
)
messages = [
{"role": "system", "content": prompt},
{"role": "user", "content": content},
]
response = llm.invoke(messages)
return response.content
except Exception as e:
raise ValueError(f"AI分析失败: {str(e)}")使用tk包生成可视化的程序展示,方便使用
import tkinter as tk
from tkinter import filedialog, messagebox
import os
import threading
from main import cli_main
class TestCaseGeneratorGUI:
def __init__(self, root):
self.root = root
self.root.title("测试用例生成系统")
# 文件选择区域
self.file_frame = tk.LabelFrame(root, text="选择输入文件")
self.file_frame.pack(padx=10, pady=10, fill="x")
self.file_entry = tk.Entry(self.file_frame, width=40)
self.file_entry.pack(side="left", padx=5, pady=5)
self.browse_btn = tk.Button(self.file_frame, text="浏览...", command=self.browse_file)
self.browse_btn.pack(side="left", padx=5, pady=5)
# 输出目录区域
self.output_frame = tk.LabelFrame(root, text="选择输出目录")
self.output_frame.pack(padx=10, pady=10, fill="x")
self.output_entry = tk.Entry(self.output_frame, width=40)
self.output_entry.pack(side="left", padx=5, pady=5)
self.output_browse_btn = tk.Button(self.output_frame, text="浏览...", command=self.browse_output)
self.output_browse_btn.pack(side="left", padx=5, pady=5)
# 进度条
self.progress = tk.Label(root, text="准备就绪")
self.progress.pack(padx=10, pady=5)
# 生成按钮
self.generate_btn = tk.Button(root, text="生成测试用例", command=self.generate_testcases)
self.generate_btn.pack(padx=10, pady=10)
def browse_file(self):
file_path = filedialog.askopenfilename(
title="选择输入文件",
filetypes=[("支持的文件", "*.pdf;*.docx;*.md")]
)
if file_path:
self.file_entry.delete(0, tk.END)
self.file_entry.insert(0, file_path)
def browse_output(self):
dir_path = filedialog.askdirectory(title="选择输出目录")
if dir_path:
self.output_entry.delete(0, tk.END)
self.output_entry.insert(0, dir_path)
def generate_testcases(self):
input_file = self.file_entry.get()
output_dir = self.output_entry.get() or "."
if not input_file:
messagebox.showerror("错误", "请选择输入文件")
return
if not os.path.exists(input_file):
messagebox.showerror("错误", "输入文件不存在")
return
self.progress.config(text="正在生成测试用例...")
self.generate_btn.config(state="disabled")
# 在新线程中运行生成过程
thread = threading.Thread(
target=self.run_generation,
args=(input_file, output_dir),
daemon=True
)
thread.start()
def run_generation(self, input_file, output_dir):
try:
# 调用命令行主函数
cli_main(input_file, output_dir=output_dir)
self.root.after(0, self.on_generation_success)
except Exception as e:
self.root.after(0, self.on_generation_error, str(e))
def on_generation_success(self):
self.progress.config(text="测试用例生成完成")
self.generate_btn.config(state="normal")
messagebox.showinfo("成功", "测试用例已成功生成")
def on_generation_error(self, error):
self.progress.config(text="生成失败")
self.generate_btn.config(state="normal")
messagebox.showerror("错误", f"生成失败: {error}")
def main():
root = tk.Tk()
app = TestCaseGeneratorGUI(root)
root.mainloop()
if __name__ == "__main__":
main()main文件生成用例xlsx文件的全流程
from file_processor import extract_text
from ai_analyzer import analyze_document
from testcase_generator import generate_testcases
import os
def cli_main(input_file, output_dir='.'):
try:
# 读取文件内容
print(f"正在读取文件: {input_file}")
content = extract_text(input_file)
# AI分析
print("正在进行需求分析...")
analysis_result = analyze_document(content)
# 生成测试用例
print("正在生成测试用例...")
wb, timestamp = generate_testcases(analysis_result)
# 保存结果
output_path = os.path.join(output_dir, f'testcase_{timestamp}.xlsx')
wb.save(output_path)
print(f"测试用例已生成至: {os.path.abspath(output_path)}")
except Exception as e:
print(f"\033[31m错误发生: {str(e)}\033[0m")
读取上传文档中的内容,获取之后传给大模型
import PyPDF2
from docx import Document
import os
def read_pdf(file_path):
try:
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
return '\n'.join([page.extract_text() for page in reader.pages])
except Exception as e:
raise ValueError(f"PDF读取失败: {str(e)}")
def read_docx(file_path):
try:
doc = Document(file_path)
return '\n'.join([para.text for para in doc.paragraphs])
except Exception as e:
raise ValueError(f"Word文档读取失败: {str(e)}")
def read_markdown(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
except Exception as e:
raise ValueError(f"Markdown读取失败: {str(e)}")
def extract_text(file_path):
ext = os.path.splitext(file_path)[1].lower()
if ext == '.pdf':
return read_pdf(file_path)
elif ext == '.docx':
return read_docx(file_path)
elif ext in ('.md', '.markdown'):
return read_markdown(file_path)
else:
raise ValueError("不支持的文件格式,仅支持PDF/DOCX/Markdown")将上传的文档中的内容传给大模型,获取返回的json内容后,处理大模型返回内容,生成xlsx并将返回内容放入xlsx文件中(ps:这里一开始一直有问题,找了半天原因最后发现是大模型返回的内容只会是string类型的,并且会在string的开头标明返回的类型是什么,这里做了切片并且转换成了json类型的数据)
import json
import openpyxl
from datetime import datetime
def generate_testcases(analysis_result):
try:
print(f"原始分析结果: {analysis_result}") # 调试输出
# 如果输入已经是字典,直接使用
if isinstance(analysis_result, dict):
data = analysis_result
else:
# 检查输入是否为字符串且非空
if not isinstance(analysis_result, str) or not analysis_result.strip():
raise ValueError("输入必须是有效的JSON字符串或字典")
# 尝试解析JSON前先去除可能的空白字符
analysis_result = analysis_result.strip()
# 预处理:删除前四个字符
if len(analysis_result) > 7:
analysis_result = analysis_result[7:-3]
analysis_result = analysis_result.strip()
# print(f"处理后结果: {analysis_result}")
# 检查字符串是否以{开头和}结尾,确保是完整JSON对象
if not (analysis_result.startswith('{') and analysis_result.endswith('}')):
raise ValueError("输入的JSON字符串格式不正确,必须以'{'开头和'}'结尾")
# 验证JSON格式有效性
try:
data = json.loads(analysis_result)
except json.JSONDecodeError as e:
print(f"JSON解析错误位置: 行{e.lineno} 列{e.colno}")
print(f"错误上下文: {analysis_result[max(0, e.pos-20):e.pos+20]}")
print(f"完整JSON内容: {analysis_result}")
raise
# 验证JSON格式有效性
try:
data = json.loads(analysis_result)
except json.JSONDecodeError as e:
print(f"JSON解析错误位置: 行{e.lineno} 列{e.colno}")
print(f"错误上下文: {analysis_result[max(0, e.pos-20):e.pos+20]}")
print(f"完整JSON内容: {analysis_result}")
raise
# 创建Excel工作簿
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "测试用例"
# 设置表头并调整列宽
ws.append(["功能点", "业务规则", "测试步骤"])
ws.column_dimensions['A'].width = 30
ws.column_dimensions['B'].width = 40
ws.column_dimensions['C'].width = 60
# 设置单元格样式
header_font = openpyxl.styles.Font(bold=True)
feature_font = openpyxl.styles.Font(bold=True)
scenario_font = openpyxl.styles.Font(bold=True)
# 应用表头样式
for cell in ws[1]:
cell.font = header_font
# 处理功能点、业务规则和测试步骤
features = data.get('功能点', [])
scenarios = data.get('业务规则', [])
test_steps = data.get('测试步骤', [])
if not features and not scenarios and not test_steps:
raise ValueError("输入数据为空,请检查分析结果")
# 填充功能点、业务规则和测试步骤
for i, feature in enumerate(features):
scenario = scenarios[i] if i < len(scenarios) else ""
test_step = test_steps[i] if i < len(test_steps) else ""
ws.append([feature, scenario, test_step])
# 设置单元格样式
ws.cell(row=ws.max_row, column=1).font = feature_font
ws.cell(row=ws.max_row, column=2).font = scenario_font
ws.cell(row=ws.max_row, column=3).font = scenario_font
# 生成时间戳文件名
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
return wb, timestamp
except json.JSONDecodeError as e:
raise ValueError(f"JSON解析失败: {str(e)}\n原始内容: {analysis_result}")
except Exception as e:
raise ValueError(f"测试用例生成失败: {str(e)}")都搞好之后用pyinstaller打包文件就可以生成exe文件直接使用了!
ps:菜鸡随便自己记录一下



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









