







摘要
本文全面解析生成模型的核心分支及其技术特性。首先划分 显式密度模型 与 隐式密度模型,随后深入剖析 自回归模型(PixelRNN/CNN)的逐像素生成机制、变分自动编码器(VAE) 的概率图模型原理,对比二者与 GAN 在建模方式、应用场景的差异。
关键词:生成模型 自回归模型 VAE GAN 显式密度估计 隐式密度估计
一、生成模型的分类框架:显式与隐式密度估计
生成模型 的核心目标是学习数据的概率分布 ( p d a t a ( x ) p_{data}(x) pdata(x)),根据建模方式可分为两大类:
- 显式密度模型:直接估计数据的概率密度函数 p ( x ) p(x) p(x),适用于数据分布可解析表达的场景。
- 隐式密度模型:通过生成器网络隐式建模分布,无需显式计算 p ( x ) p(x) p(x),适合高维复杂数据。
| 模型类型 | 代表算法 | 核心特点 |
|---|---|---|
| 显式密度模型 | PixelRNN/CNN、VAE | 需显式计算概率密度,可用于密度估计、异常检测 |
| 隐式密度模型 | GAN及其变体 | 通过对抗生成隐式建模分布,擅长生成高保真样本但难以进行似然估计 |
二、自回归模型:逐像素建模的生成逻辑
自回归模型(Autoregressive Models)通过 链式法则 将高维数据的联合概率分解为条件概率的乘积,适用于序列数据(如图像像素、语音信号)。
1. 核心原理:从像素到序列的递归生成
对于图像数据 ( x = ( x 1 , x 2 , … , x n ) x = (x_1, x_2, \dots, x_n) x=(x1,x2,…,xn)),其概率分布可分解为:
p d a t a ( x ) = ∏ i = 1 n p ( x i ∣ x 1 , x 2 , … , x i − 1 ) p_{data}(x) = \prod_{i=1}^n p(x_i \mid x_1, x_2, \dots, x_{i-1}) pdata(x)=i=1∏np(xi∣x1,x2,…,xi−1)
-
PixelRNN:使用循环神经网络(RNN)建模条件概率 ( p ( x i ∣ x < i ) p(x_i \mid x_{<i}) p(xi∣x<i)),按行或列顺序逐像素生成图像。
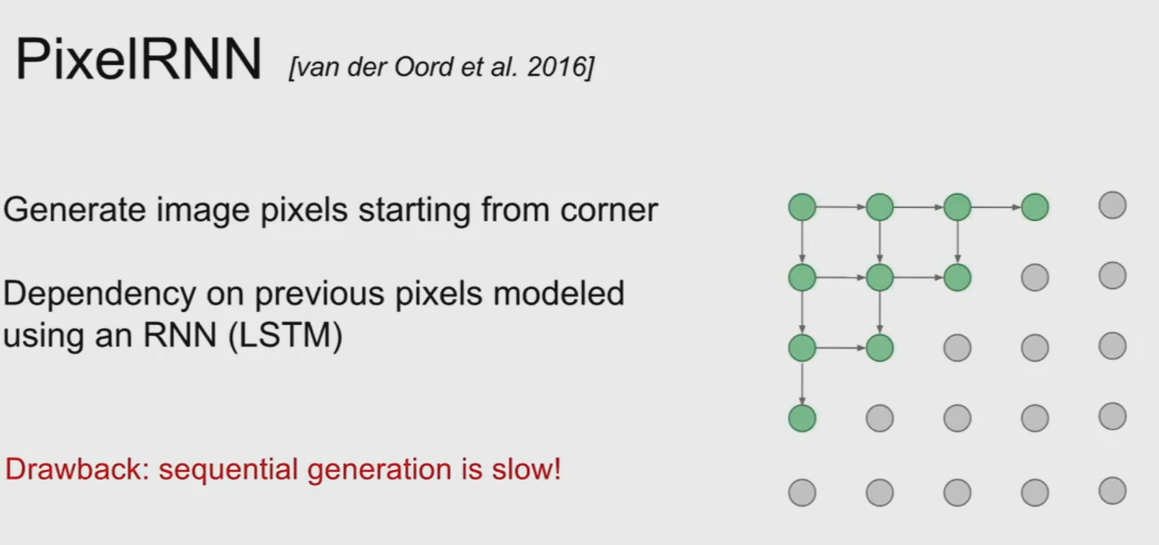
-
PixelCNN:采用卷积神经网络(CNN)替代RNN,通过 掩码卷积(Masked Convolution) 保证因果关系(当前像素仅依赖已生成的左侧/上侧像素)。
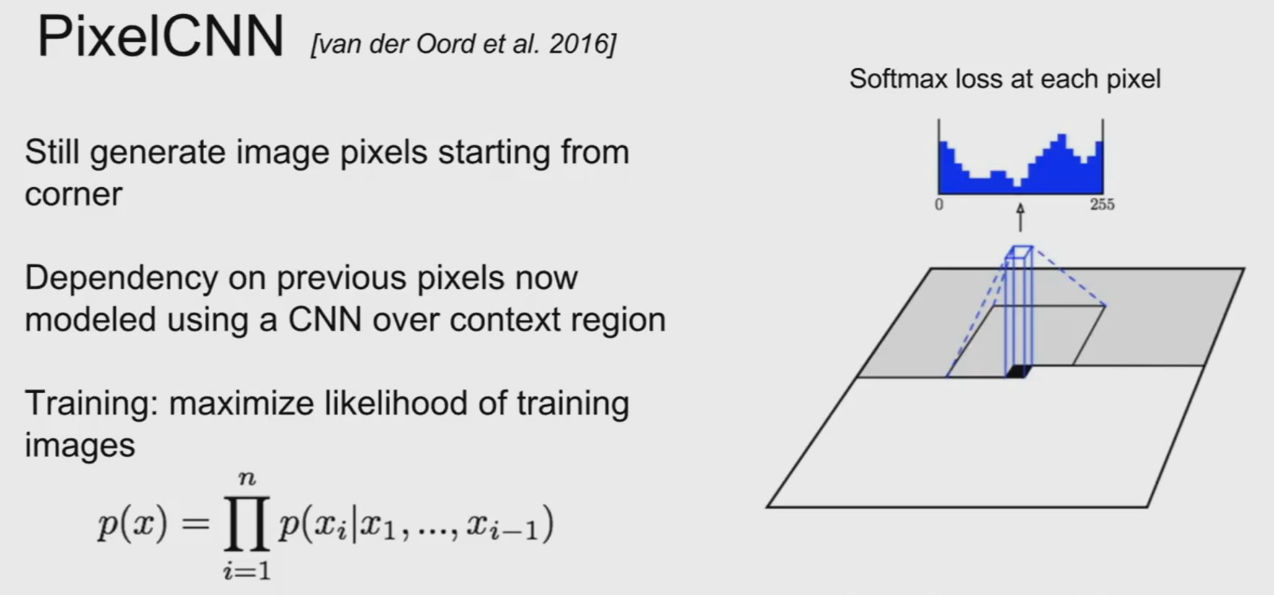
2. 架构与性能特征
- 优点:
- 严格遵循概率 链式法则,理论上可逼近任意复杂分布。
- 支持密度估计,可计算数据的对数似然(Log-Likelihood)用于模型比较。
- 缺点:
- 生成速度慢(需逐个像素生成),分辨率越高计算成本呈指数增长。
- 难以并行化,训练与推理效率低于 GAN。
3. 典型应用:语音合成与图像生成
- WaveNet:基于 PixelRNN 的语音生成模型,通过建模音频信号的时序依赖关系,生成高保真语音。
- ImageGPT:结合 Transformer 架构的 自回归模型,可生成具有长程依赖的复杂场景图像。
三、变分自动编码器(VAE):概率图模型的生成范式
VAE 是基于 变分推断 的 生成模型,通过编码器 - 解码器架构学习数据的隐变量分布,其核心思想是在隐空间中建模潜在语义,再通过解码器重构数据。
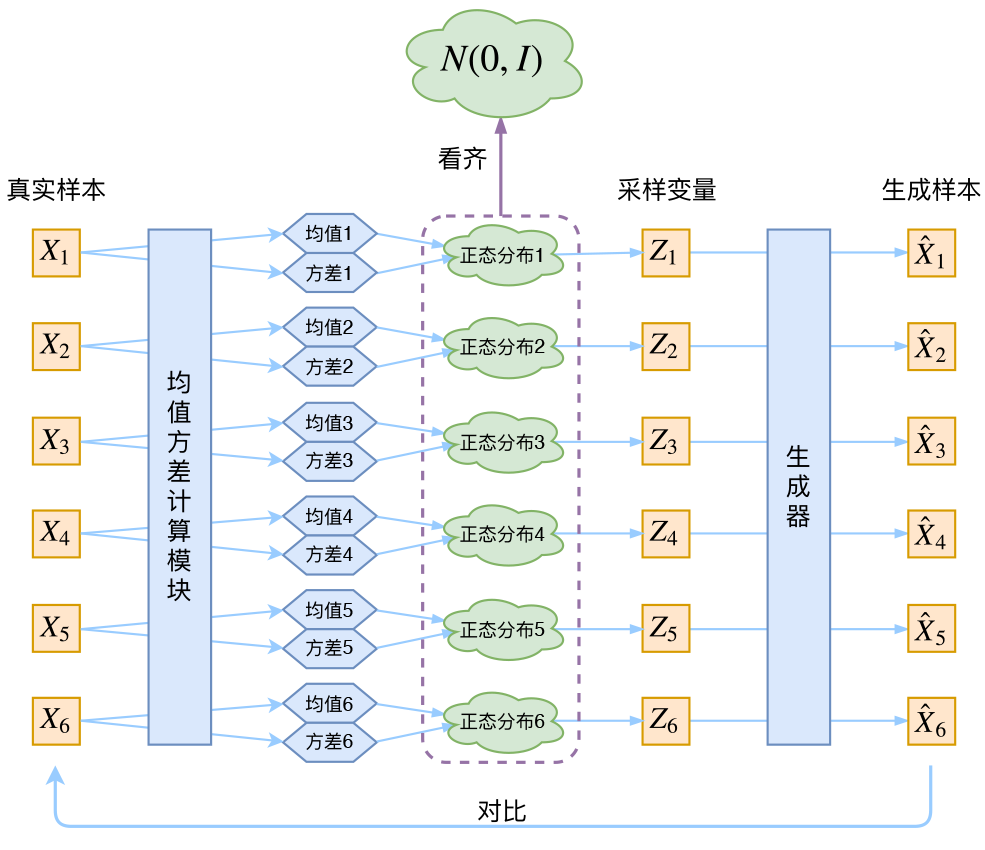
1. 模型架构与数学推导
VAE 的核心组件包括:
- 编码器(Encoder):将输入数据 x x x 映射到隐变量 z z z 的概率分布 ( q ϕ ( z ∣ x ) q_\phi(z \mid x) qϕ(z∣x)),通常假设为高斯分布 ( N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2))。
- 解码器(Decoder):根据隐变量 z z z 生成重构数据 ( x ^ \hat{x} x^),即建模条件概率 ( p θ ( x ∣ z ) p_\theta(x \mid z) pθ(x∣z))。
目标函数(证据下界,ELBO):
L VAE = E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] − KL ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \mathcal{L}_{\text{VAE}} = \mathbb{E}_{q_\phi(z \mid x)} [\log p_\theta(x \mid z)] - \text{KL}(q_\phi(z \mid x) \parallel p(z)) LVAE=Eqϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∥p(z))
- 第一项为重构损失,衡量生成样本与原始数据的相似性(如均方误差)。
- 第二项为 KL散度 正则项,强制隐变量分布 ( q ϕ ( z ∣ x ) q_\phi(z \mid x) qϕ(z∣x)) 逼近先验分布 ( p ( z ) p(z) p(z))(通常为标准正态分布)。
2. 与GAN的对比分析
| 维度 | VAE | GAN |
|---|---|---|
| 建模方式 | 显式优化隐变量分布,生成样本为解码器输出 | 隐式通过对抗博弈生成样本,无显式密度函数 |
| 样本质量 | 倾向生成模糊但全局一致的样本 | 可生成高保真样本,但可能出现模式崩塌 |
| 理论基础 | 变分推断 与概率图模型 | 极小极大博弈与纳什均衡 |
| 应用场景 | 数据压缩、半监督学习 | 图像生成、风格迁移 |
3. 架构改进:从VAE到CVAE
-
条件VAE(CVAE):在编码器与解码器中引入条件变量 y y y(如类别标签),实现可控生成:
q ϕ ( z ∣ x , y ) , p θ ( x ∣ z , y ) q_\phi(z \mid x, y), \quad p_\theta(x \mid z, y) qϕ(z∣x,y),pθ(x∣z,y)
-
对抗VAE(AVAE):结合 GAN 的对抗机制,通过判别器提升生成样本的真实性,缓解 VAE 的模糊性问题。
四、显式与隐式模型的技术演进路径
1. 自回归模型的优化方向
- 并行化改进:如 PixelCNN++ 通过 非因果卷积(Non - Causal Convolution) 与层次化生成,提升高分辨率图像的生成速度。
- 多模态建模:结合 混合密度网络(Mixture Density Network),建模像素的多模态分布(如RGB值的多峰分布)。
2. VAE的扩展应用
- 无监督表示学习:隐变量 z z z 可作为数据的紧凑特征表示,用于下游分类、聚类任务。
- 异常检测:通过计算数据的对数似然,检测低概率样本(如工业缺陷检测)。
3. 模型融合趋势
- VAE+GAN:如 InfoGAN 通过 VAE 的隐变量解耦,结合 GAN 的对抗训练,实现可控生成与语义编辑。
- 自回归模型+GAN:如 Autoregressive GAN 利用 自回归模型 的长程依赖建模能力,提升 GAN 在序列数据(如文本、语音)中的生成稳定性。
五、实践选择指南:如何挑选合适的生成模型?
- 任务需求导向:
- 若需生成高保真图像或视频,优先选择 GAN 及其变体(如 StyleGAN、Diffusion Models)。
- 若需密度估计或数据压缩,VAE 或 自回归模型 更合适。
- 若处理时序数据(语音、文本),自回归模型(如 Transformer)仍是主流选择。
- 计算资源限制:
- 自回归模型 生成速度慢,需提前评估实时性要求。
- GAN 训练需要对抗优化技巧,对算力与调参经验要求较高。
- 可解释性需求:
- 显式密度模型(如 VAE)的隐变量具有概率意义,适合需要可解释性的场景(如医疗诊断)。
生成模型 的发展呈现出“理论驱动创新,应用反哺理论”的特点。自回归模型 的概率严谨性、VAE 的表示学习能力与 GAN 的生成逼真度,分别从不同维度推动了数据生成技术的进步。未来,随着 Diffusion Models 等新范式的兴起,生成模型 将在多模态合成、科学模拟等领域展现更广阔的应用前景。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









