




聊一聊
很多公司上班都是允许播放个音乐的。
歌曲是可以点了。
但歌曲上的照片也更换吗?
我想换成自己喜欢的图片放上面。
这个当然也是可以的。
今天给大家分享这款软件就可以修改音乐内嵌的图片。
软件介绍
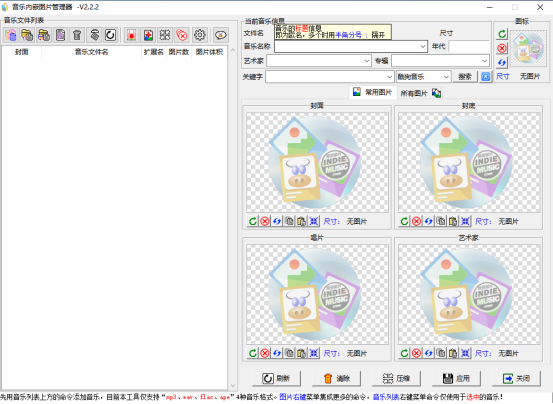
音乐内嵌图片管理器
这个软件几乎可以替换音乐里面的所有的图片。
看界面就能看出来操作非常简单。
需要一点点图片处理技术。
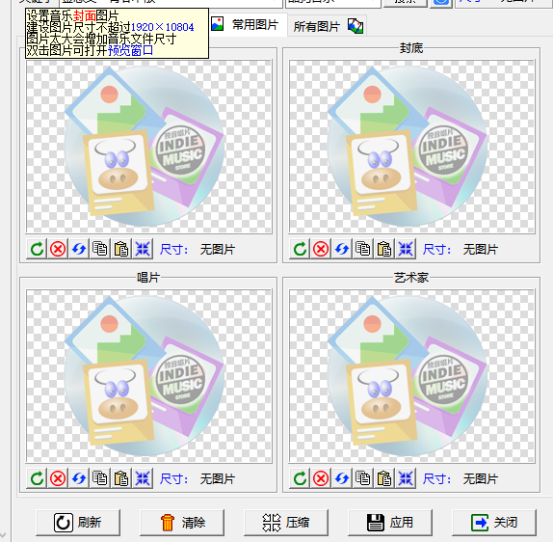
至少要将图片大小调整成软件需要的大小。
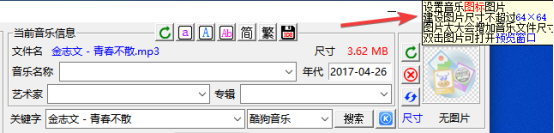
不同的封面,对图片尺寸大小也不一样。
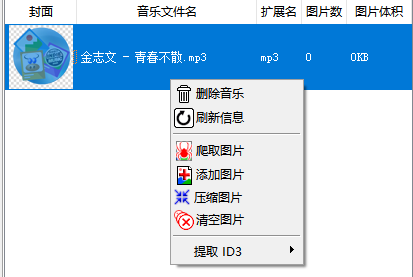
这里我打开一首歌,右键,选择添加图片。
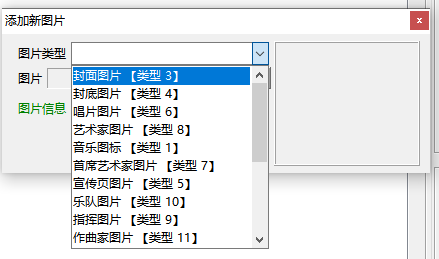
添加时,可以选择图片类型,不同类型需要不同尺寸。
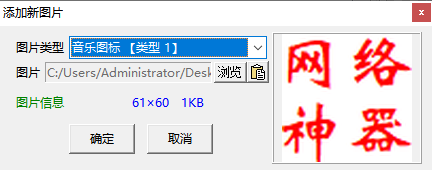
这里我选择音乐图标,选择了一张图片。

然后就能看出效果了。
其他图片操作方法如上。
软件就介绍到这,更多功能请自行测试。
链接:https://pan.quark.cn/s/1cc2baf874a0
提取码:WfZ5

















 8103
8103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









