










目标
文章篇幅太长,人生又太短,AI总结好了,先看大纲再重点学习,是不是很爽,内容总结转成思维导图是不是更爽,这就是探索的目标了。
总体思路:
AI大模型进行文章总结,输出markdown==》markdown通过markmap转为html文件=》网页内容转成图片
说明:不要问,为什么不直接转成图片,因为能直接转成图片的太丑,不丑的只能转成网页👀。
准备:
准备环境,用目前知道的最可心的trae,安装部署参考上一篇文档:
【Ai工具】trae和传统编程环境vs+代码助手的PK,结果大捷-CSDN博客
AI生成文档总结
可以让AI助手帮你生成代码,仿照上一篇参考文档里类似的过程,或者直接修改下面代码:
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 定义文件夹路径
input_folder = r'D:\01成长探索\001佛法_禅修法要\阿含经译文\mkinpt'
output_folder = r'D:\01成长探索\001佛法_禅修法要\阿含经译文\mkoutpt'
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 遍历文件夹中的每个文件
for filename in os.listdir(input_folder):
if filename.endswith('.txt'): # 假设文件是txt格式,可以根据需要修改
file_path = os.path.join(input_folder, filename)
print(f'-----------: {filename}')
# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 使用大模型进行分析和总结
completion = client.chat.completions.create(
model="qwen-max", # 此处以 deepseek-r1 为例,可按需更换模型名称。 #deepseek-v3 qwen-max qwen-turbo-0206 qwen-plus-latest
messages=[
{'role': 'user', 'content': f'请仔细阅读并全面总结以下内容,结果以markdown格式输出,输出的内容后续用于生成思维导图,请兼顾这一点,首行不要输出```markdown,各项要有能生成导图分支的符合标识:\n{content}'}
]
)
# 通过content字段获取最终答案
summary = completion.choices[0].message.content
# 将总结结果保存为Markdown文件
output_file_path = os.path.join(output_folder, f'{os.path.splitext(filename)[0]}_内容总结.md')
with open(output_file_path, 'w', encoding='utf-8') as output_file:
output_file.write(summary)
有代码可见,需要总结的文档目录和输出目录放在下面目录中:
input_folder = r'D:\01成长探索\001佛法_禅修法要\阿含经译文\mkinpt'
output_folder = r'D:\01成长探索\001佛法_禅修法要\阿含经译文\mkoutpt'
目前只,识别txt文件,也可以自行修改。
md转网页
查了几种,markmap转成的思维导图比较好看,让AI用markmap技术转换md文件,结果它还不会,还训练了一下,训练过程也很简单,就是把markmap的技术文档给AI,大家感兴趣,可以看我的总结文档:
这里说一下,转换过程:
安装支持包:
npm install -g markmap-cli在Trae终端执行界面:
然后就可以转换了:
markmap 增壹阿含经卷2_内容总结.md -o 增壹阿含经卷2_内容总结.html转换效果如下:

网页转图片
当然如果少可以用截图的方式,我文档多,想批量处理,所以选择用命令或程序处理。
python方式:
用Selenium结合Pillow库来实现。首先因为支持包:
pip install selenium
pip install pillow引入后执行代码:
from selenium import webdriver
from PIL import Image
import time
# 初始化浏览器
driver = webdriver.Chrome()
# 打开网页
driver.get(r'E:\02trae\fores\zah\mkd\增壹阿含经卷2_内容总结.html')
# 等待页面加载完成
time.sleep(5)
# 获取页面截图
driver.save_screenshot('screenshot2.png')
# 关闭浏览器
driver.quit()其中网页地址也支持浏览器地址(本地或公网页面地址):
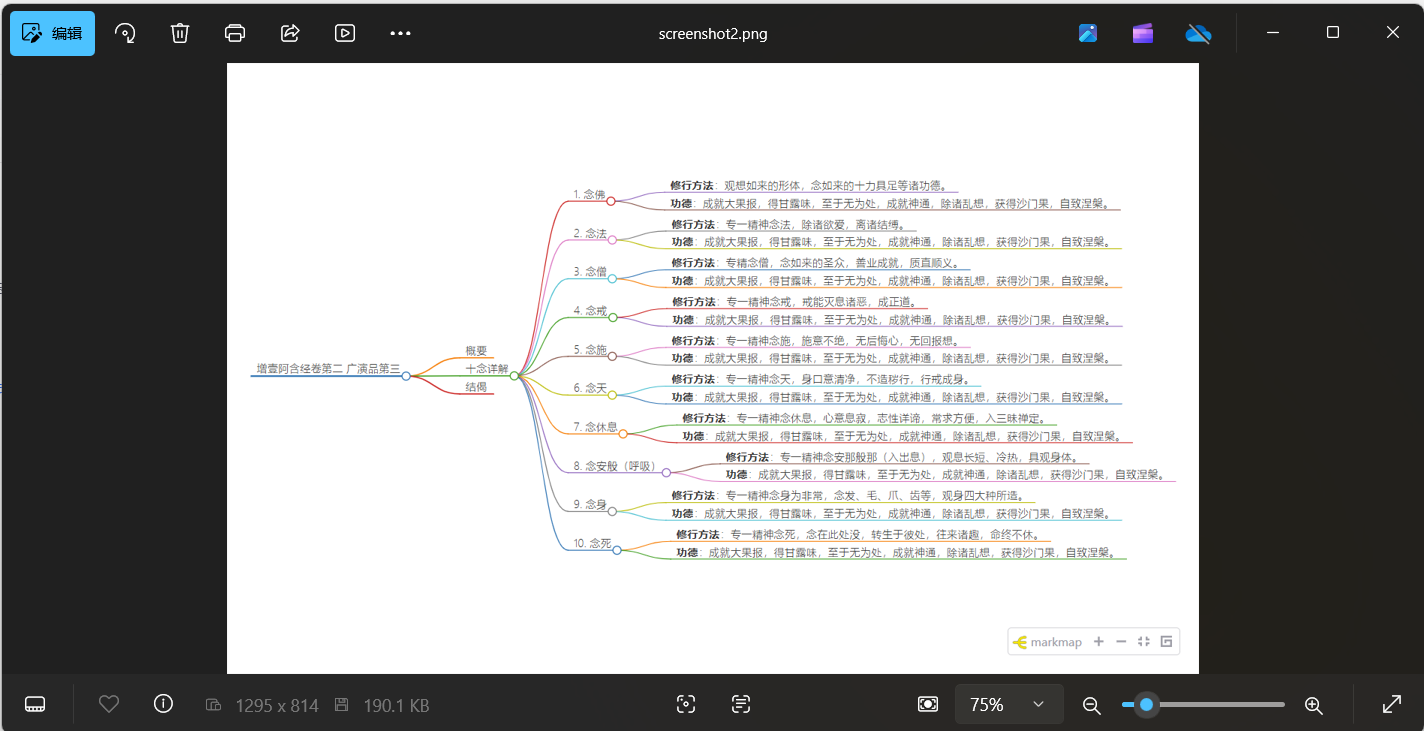
driver.get('file:///E:/02trae/fores/zah/mkd/%E5%A2%9E%E5%A3%B9%E9%98%BF%E5%90%AB%E7%BB%8F%E5%8D%B72_%E5%86%85%E5%AE%B9%E6%80%BB%E7%BB%93.html')执行过程中,网页会打开,然后截图,图片效果是这样,感觉还行:
Ai还给了其他方式。
命令行方式:wkhtmltopdf
wkhtmltopdf:可以将HTML页面转换为PDF或图片,先安装,然后用命令:
wkhtmltoimage http://example.com screenshot.png我没有试,看着还是挺简单的,大家也可以试试。
总结
找解决方案还是辛苦啊, 转换过程还是有点繁杂,走过路过的朋友,谁有md直接转图片的方法,留言知会一声哈。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











