






今天要给大家介绍一款超实用的工具——抖音视频下载助手,这是一款绿色单文件的抖音下载神器,真正做到了简洁高效,无需繁琐的安装步骤,双击文件即可快速打开软件,随时随地开启你的抖音视频下载之旅。
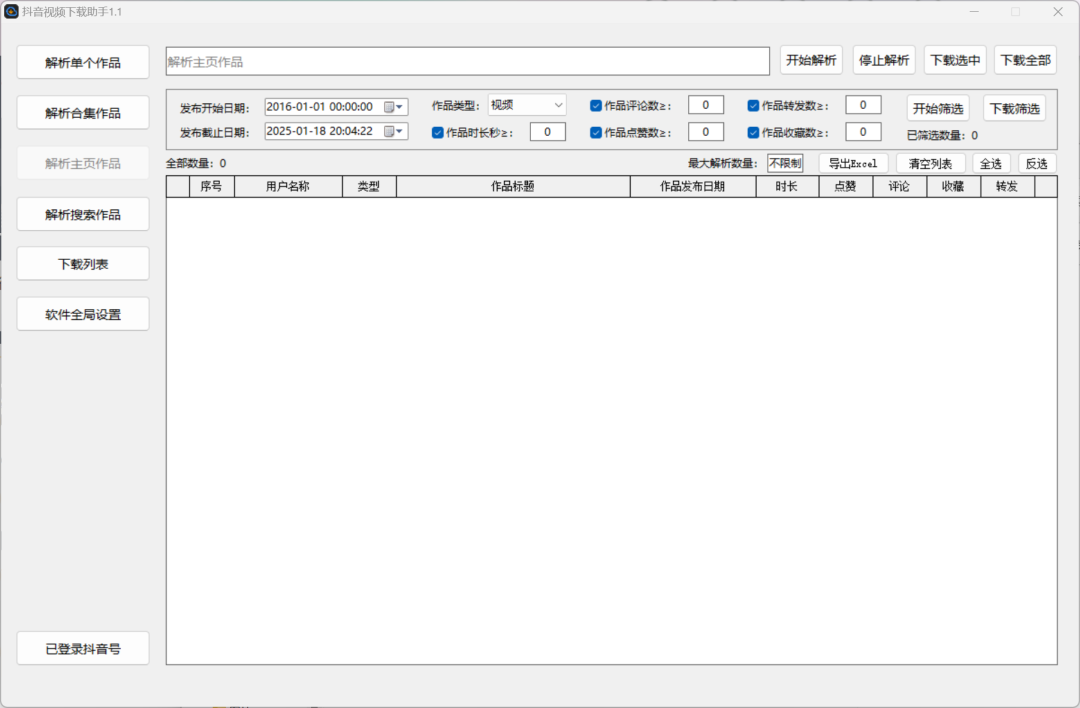
这款软件的功能十分强大,不仅可以轻松解析单个作品,还能批量解析合集,实现高效下载。无论是热门的单个视频,还是博主的系列合集,都能轻松搞定,满足你不同的下载需求。
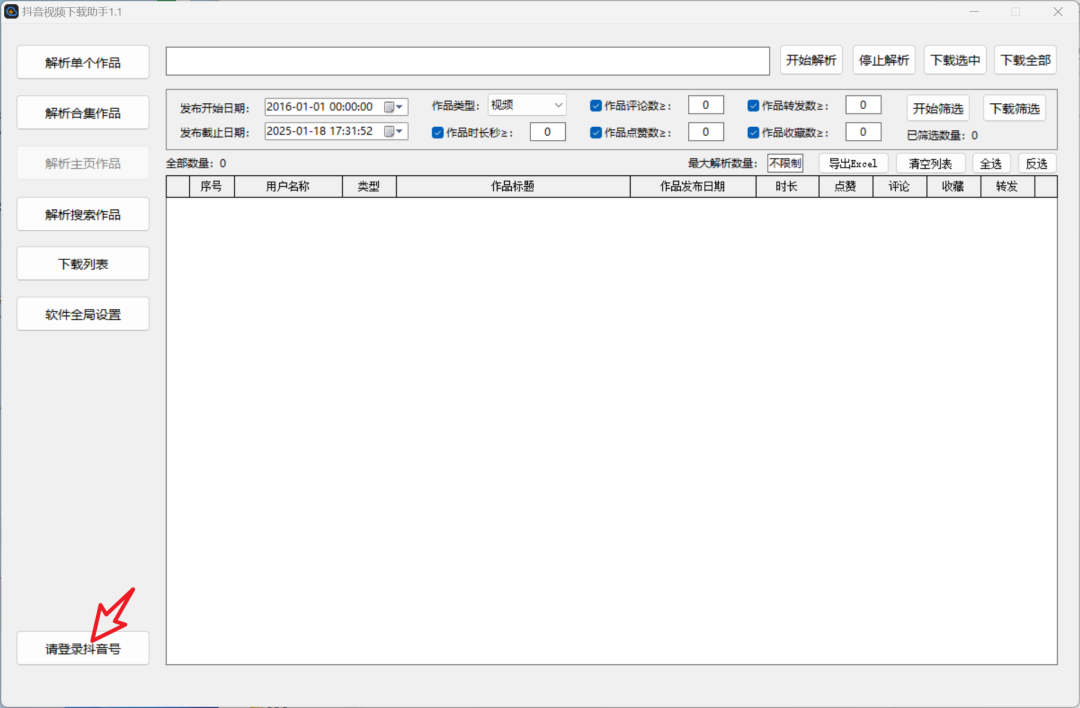
在使用这款软件之前,需要先进行登录操作。点击软件右下角的【请登录D音号】按钮,然后使用手机扫描二维码即可完成登录,整个过程简单快捷,轻松几步就能让你畅享下载功能。
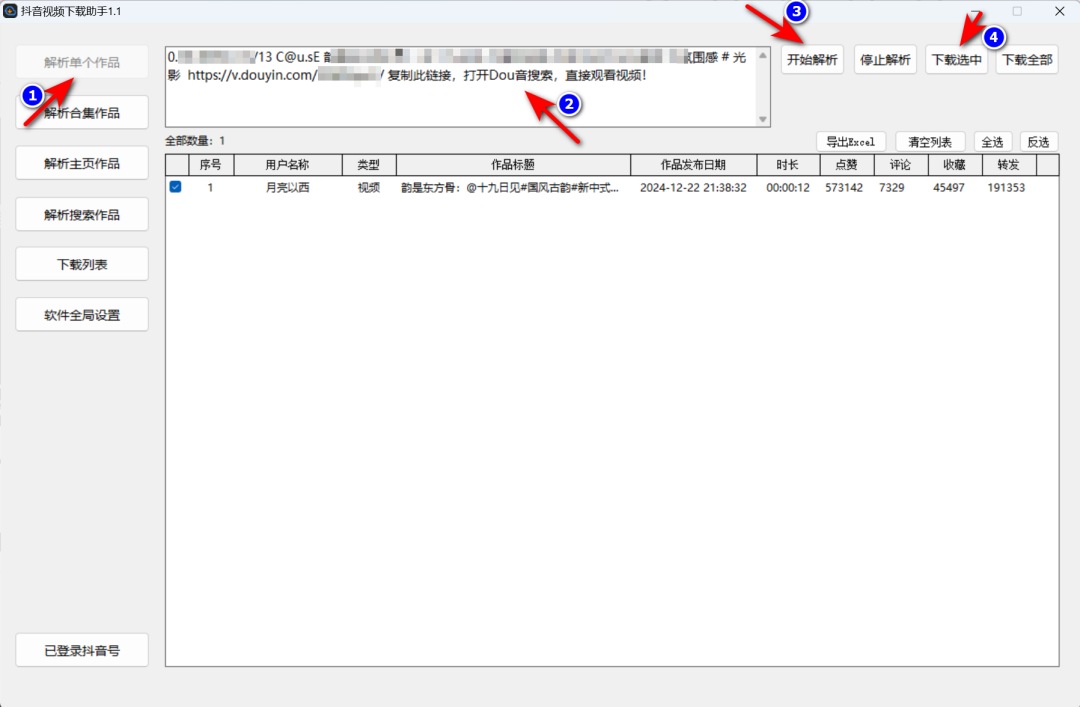
在刚开始使用这款软件时,我曾犯过一个小错误。一开始,我是直接把视频链接复制到地址栏,然后点击解析、下载,但其实这不是最正确的方式。正确的操作是,首先要点击软件界面中的【解析单个作品】按钮。这个链接地址可以从抖音网页端获取分享时的链接地址,也可以从抖音APP上分享时复制链接。通过这种方式,可以确保解析和下载更加精准、高效。
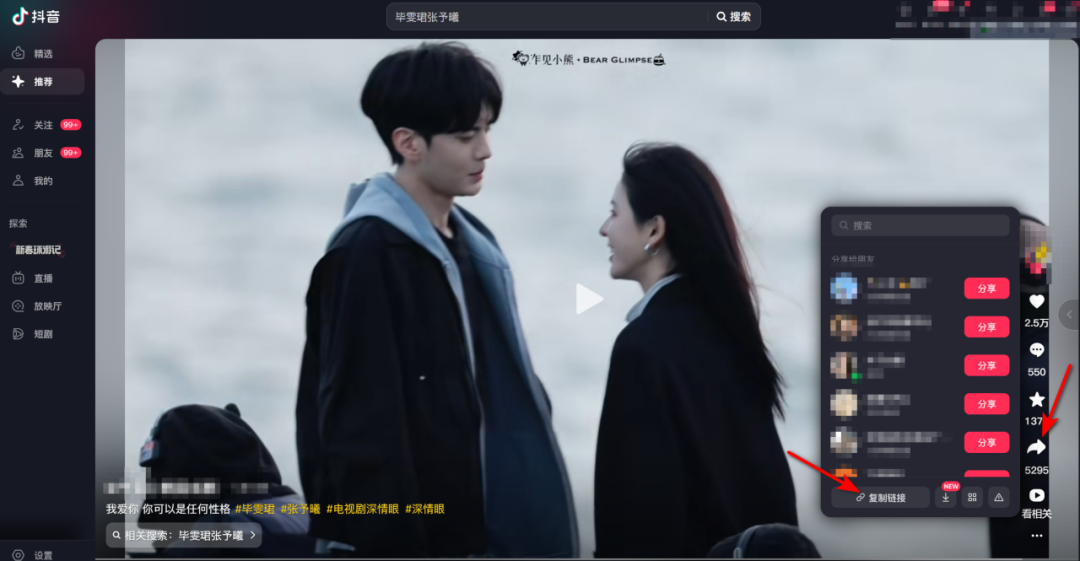
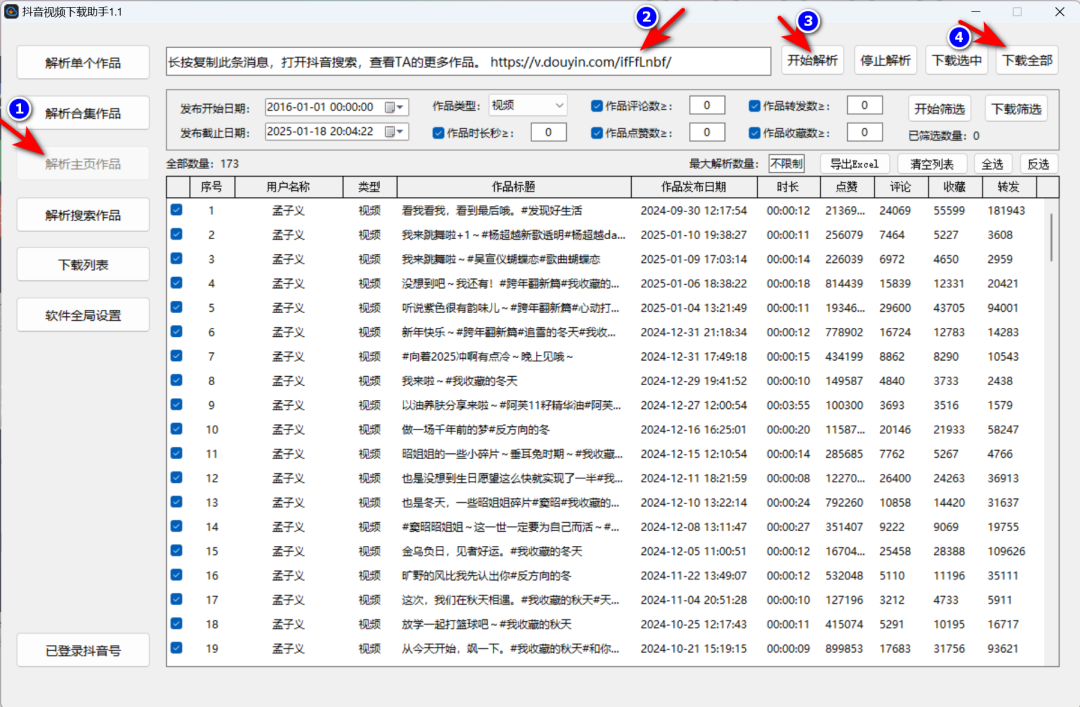
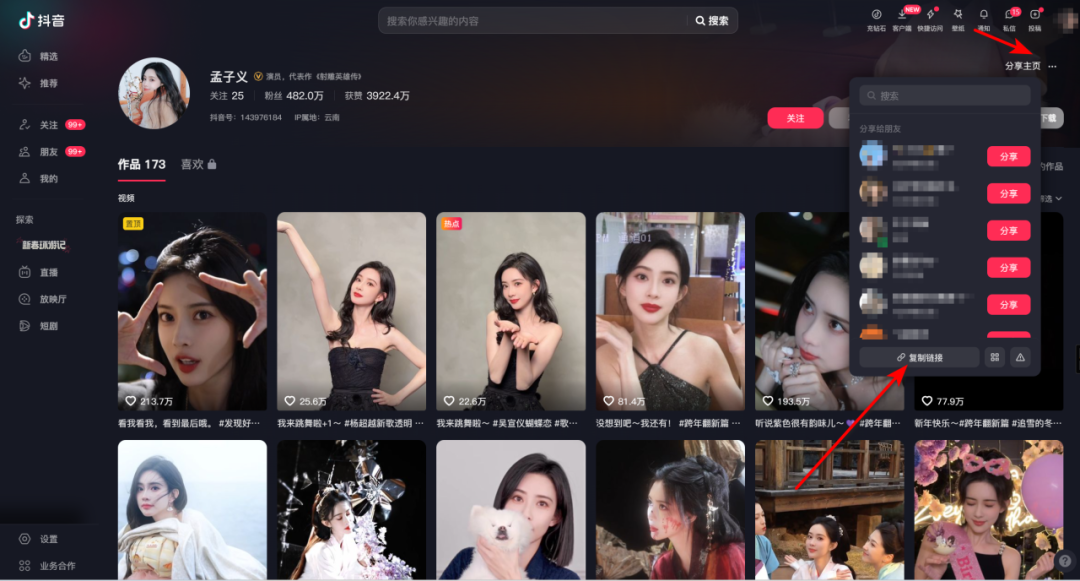
除了单个视频的解析和下载,这款软件还能解析主页作品。如果你想下载某个视频博主主页的所有视频,操作方法与单个作品解析下载完全一致。在获取主页链接时,只需点击博主主页右上角的“分享主页”,然后复制链接地址即可。这样一来,你就可以轻松获取博主的所有精彩视频,一次性下载,畅享观看。
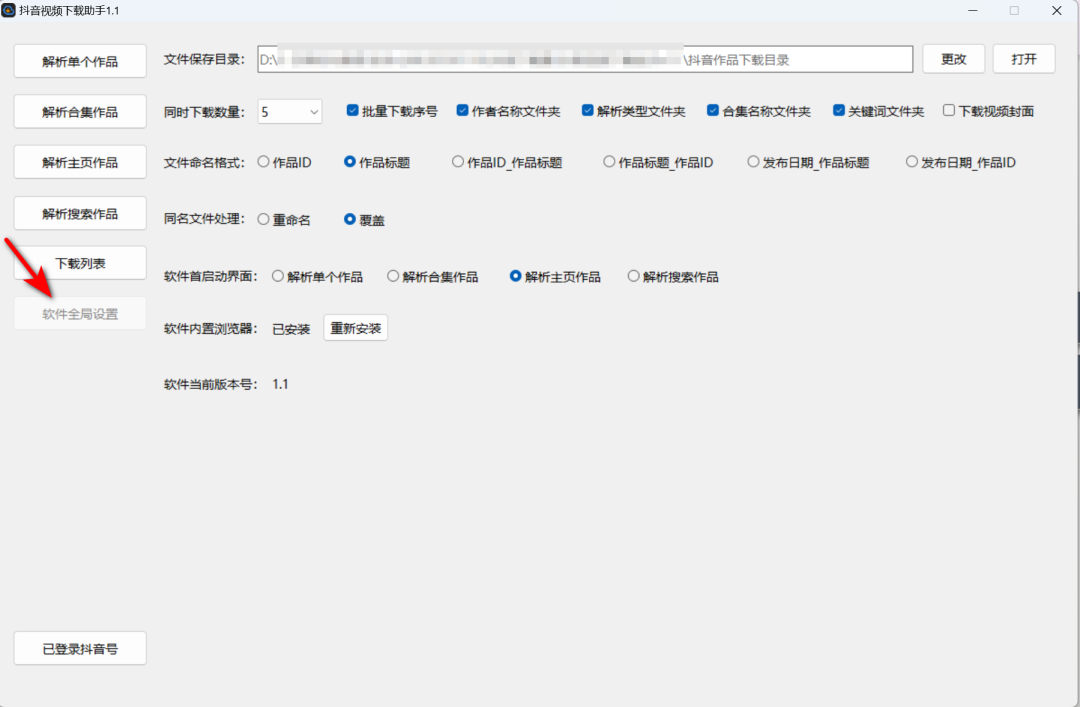
此外,这款软件还提供了丰富的【软件全局设置】选项。在这里,你可以自由设置视频的保存路径,方便你将下载的视频分类存储;还可以调整同时下载的数量,根据你的网络状况和需求进行优化;更有文件命名格式的自定义功能,让你的下载文件更加规范、易于查找。这些人性化的设置,让软件的使用体验更加贴心、便捷。
总体来说,抖音视频下载助手的使用体验非常棒,无论是功能的实用性,还是操作的便捷性,都让人印象深刻。它真正做到了简单易用,却又功能强大。如果你也想轻松下载抖音视频,不妨试试这款软件,相信它会成为你下载抖音视频的得力助手。
链接:https://pan.quark.cn/s/a57a64559429


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









