






# 数据来源 https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/weibo_senti_100k/intro.ipynb
# 数据概览: 10 万多条,带情感标注 新浪微博,正负向评论约各 5 万条
# 停用词字典 https://github.com/goto456/stopwords
import jieba # 导入中文分词的第三方库,jieba分词
data_path = "../sources/weibo_senti_100k.csv" # 数据路径
data_stop_path = "../sources/hit_stopwords.txt" # 停用词数据路径
data_list = open(data_path, encoding='UTF-8').readlines()[1:] # 读出数据并去掉第一行的介绍标签, 每一行为一个大字符串
stops_word = open(data_stop_path, encoding='UTF-8').readlines() # 读取停用词内容
stops_word = [line.strip() for line in stops_word] # 将每行换行符去掉(去掉换行符),并生成停用词列表 移除字符串开头和结尾的空白字符(包括空格、换行符\n、制表符\t等)
stops_word.append(" ") # 可以自己根据需要添加停用词
stops_word.append("\n")
voc_dict = {} #初始化一个空字典,用于统计每个词语在数据集中出现的次数(词频统计)
min_seq = 1 # 用于过滤词频数 设定词频过滤的阈值,仅保留出现次数 ≥ min_seq 的词语。 目的:过滤掉低频词(如错别字、生僻词),减少噪声和计算量。
top_n = 1000 #保留词频最高的前1000个词语。
UNK = "<UNK>"
#作用:代表 未知词(Unknown Token),用于处理未出现在词汇表中的词语。
#使用场景:当模型遇到训练时未见过的新词(如网络新词 "绝绝子"),会统一替换为 <UNK>。在词汇表中,<UNK> 的ID通常为 len(voc_dict)。
#示例:词汇表若为 {"好":0, "喜欢":1, UNK:2},则句子 "这个绝绝子" 会被编码为 [2]。
PAD = "<PAD>"
#作用:代表 填充符(Padding Token),用于统一不同长度的句子。
# 使用场景:在批量训练时,所有句子需填充到相同长度(如32个词),短句用 <PAD> 补足。
# 在词汇表中,<PAD> 的ID通常为 len(voc_dict)+1。
# 示例:
# 句子 "今天开心" 填充到长度5后变为 ["今天", "开心", "<PAD>", "<PAD>", "<PAD>"]。
print(data_list[0]) #打印一下 看看格式是否符合预期
# 对data_list进行分词的处理
# for item in data_list[:100]: 使用前100条数据测试,100000条数据太多
for item in data_list:
label = item[0] # 字符串的第一个为标签
content = item[2:].strip() # 从第三项开始为文本内容(这个可以通过查看下载的数据看到), strip()去掉最后的换行符
seg_list = jieba.cut(content, cut_all=False) # 调用结巴分词对每一行文本内容进行分词
seg_res = []
# 打印分词结果
for seg_item in seg_list:
if seg_item in stops_word: # 如果分词字段在停用词列表里,则取出
continue
seg_res.append(seg_item) # 如果不在则加入分词结果中
if seg_item in voc_dict.keys(): # 使用字典统计词频seg_item in voc_dict.keys():
voc_dict[seg_item] += 1
else:
voc_dict[seg_item] = 1
# print(content) # 打印未分词前的句子
# print(seg_res)
# 对字典进行排序,取TOPK词,如果将所有词都要,将会导致字典过大。我们只关注一些高频的词
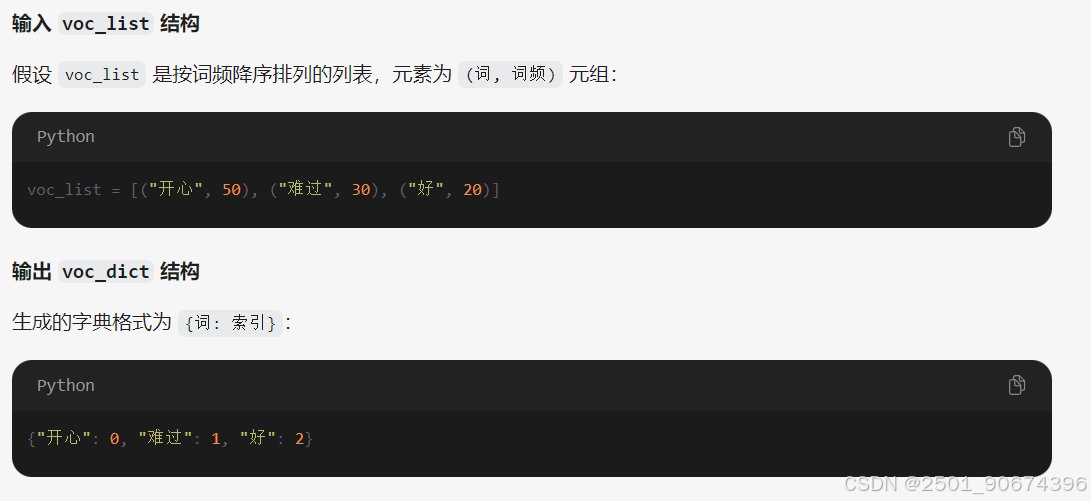
voc_list = sorted([_ for _ in voc_dict.items() if _[1] > min_seq],
key=lambda x: x[1], # key:指定一个参数的函数,该函数用于从每个列表元素中提取比较键
reverse=True)[:top_n] # 取排完序后的前top_n个词,
voc_dict = {word_count[0]: idx for idx, word_count in enumerate(voc_list)} # 根据排序后的字典重新字典
voc_dict.update({UNK: len(voc_dict), PAD: len(voc_dict) + 1}) # 将前top_n后面的归类为UNK
print(voc_dict) # '泪': 0, '嘻嘻': 1, '都': 2,
# 保存字典
ff = open("../sources/dict.txt", "w")
for item in voc_dict.keys():
ff.writelines("{},{}\n".format(item, voc_dict[item])) # '泪': 0, '嘻嘻': 1, '都': 2,上面有的地方已加上详细注释 接下来继续解释一下我遇到的不理解的代码
seg_list = jieba.cut(content, cut_all=False)
- 作用:将中文句子
content切分为词语列表。 - 参数说明:
cut_all=False:启用精确分词模式(默认模式),输出最合理的分词结果。cut_all=True:启用全模式,输出所有可能的分词组合(不推荐常规使用)。
分词示例
假设输入 content = "我爱自然语言处理":

初始化结果列表
seg_res = []
创建一个空列表,用于存储过滤停用词后的分词结果。
若分词结果为 ["我", "的", "手机"],过滤停用词后可能为 ["我", "手机"]
遍历分词结果并过滤停用词
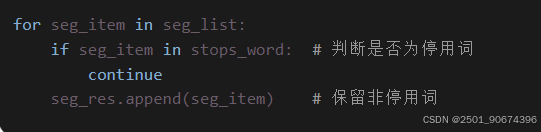
seg_list 是 jieba.cut() 的分词结果(如 ["今天", "天气", "好"])
若当前词在停用词列表中,跳过该词;否则加入 seg_res
continue用法


注释:在Python中,_通常用作临时变量名,尤其是在不需要关心变量具体名称的情况下,比如在循环中。但在这里,_被用作迭代变量,遍历voc_dict.items()的每个元素。voc_dict是一个字典,items()方法返回字典的键值对,每个元素是一个元组,形式为(key, value)。
因此,_在这里代表每个键值对元组。例如,如果voc_dict是{'apple': 5, 'banana': 3},那么voc_dict.items()会生成dict_items([('apple', 5), ('banana', 3)])。在每次迭代中,_依次取这两个元组的值:('apple', 5)和('banana', 3)。
接下来是条件部分if _[1] > min_seq。这里的_[1]指的是元组的第二个元素,也就是字典的值(value),即每个词的出现次数。min_seq是一个阈值,用于过滤掉出现次数小于或等于该值的项。因此,整个条件判断的是当前项的值是否大于min_seq,如果是,则保留该元素。
key=lambda x: x[1]:按元组的第二个元素(词频)排序。
reverse=True:降序排列(从高到低)。

第一行解释:
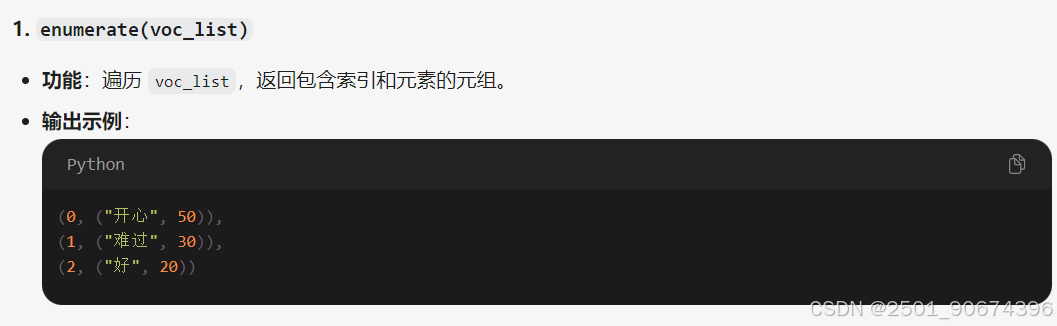

第二行解释:
首先,我需要明确update()方法的功能。根据搜索结果和,Python中的dict.update()方法用于将一个字典的键值对合并到当前字典中。如果键已存在,则更新其值;如果不存在,则添加新键值对。例如,如果原字典是{'a': 1},执行update({'b':2})后,字典变为{'a':1, 'b':2}。
接下来,用户代码中的UNK和PAD是预定义的特殊标记,分别代表未知词和填充符。在自然语言处理任务中,UNK用于处理词汇表外的词语,而PAD用于统一输入序列的长度。这两个标记需要被加入到词汇表中,并分配唯一的ID。
在我们的代码中,voc_dict在添加前已经包含了按词频排序后的高频词及其对应的索引。此时,len(voc_dict)表示当前词汇表的大小,也就是下一个可用的索引位置。例如,如果已经有1000个词,索引从0到999,那么len(voc_dict)是1000,所以UNK的索引就是1000,PAD则是1001。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









