






机器学习1
一、集成算法的简介
对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务等。
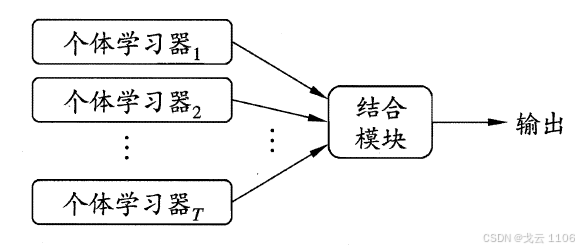
结合策略
1、 简单平均法
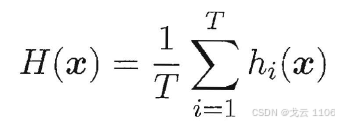
2、 加权平均法
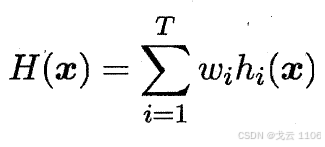
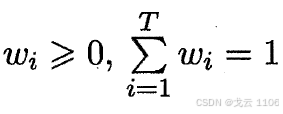
集成学习的结果通过投票法产生?即“少数服从多数”

二、Pytorch实现cifar10多分类(2)
1、使用模型
#导入需要的模块
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from collections import Counter
#定义一些超参数
BATCHSIZE=100
DOWNLOAD_MNIST=False
EPOCHES=20
LR=0.001

#定义相关模型结构,这三个网络结构比较接近
class CNNNet(nn.Module):
def __init_(self):
super(CNNNet,self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(in_channels=16,out_channels=36,kernel_size=3,stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(1296,128)
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x=self.pool1(F.relu(self.conv1(x)))
x=self.pool2(F.relu(self.conv2(x)))
#print(x.shape)
x=x.view(-1,36*6*6)
x=F.relu(self.fc2(F.relu(self.fc1(x))))
return x

class Net(nn.Module):
def __init_(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 36, 5)
#self.fc1 = nn. Linear(16 * 5 * 5, 120)
self.pool2 = nn.MaxPool2d(2, 2)
self.aap=nn.AdaptiveAvgPool2d(1)
#self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(36, 10)
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
#print(x.shape)
#x = x.view(-1, 16 * 5 * 5)
x=self.aap(x)
#print(x.shape)
#x = F.relu(self.fc2(x))
x = x.view(x.shape[0], -1)
#print(x.shape)
x=self.fc3(x)
return x

class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.convl = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0),-1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out

cfg = {
'VGG16':[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19':[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M' ],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0),-1)
out = self.classifier(out)
return out

def _make_layers(self,cfg):
layers = []
in_channels = 3
for x in cfg:
if x= = 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
#导入数据,这里数据已下载本地,设download=False
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Data
print('==> Preparing data..')
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),(0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),(0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFA10(root='./data', train=True, download=False, transform=transform_train)
trainloader = torch,utils,data,DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# Model
print('==> Building model..')
net1 = CNNNet()
net2=Net()
net3=LeNet()
net4 = VGG('VGG16')

三、集成方法
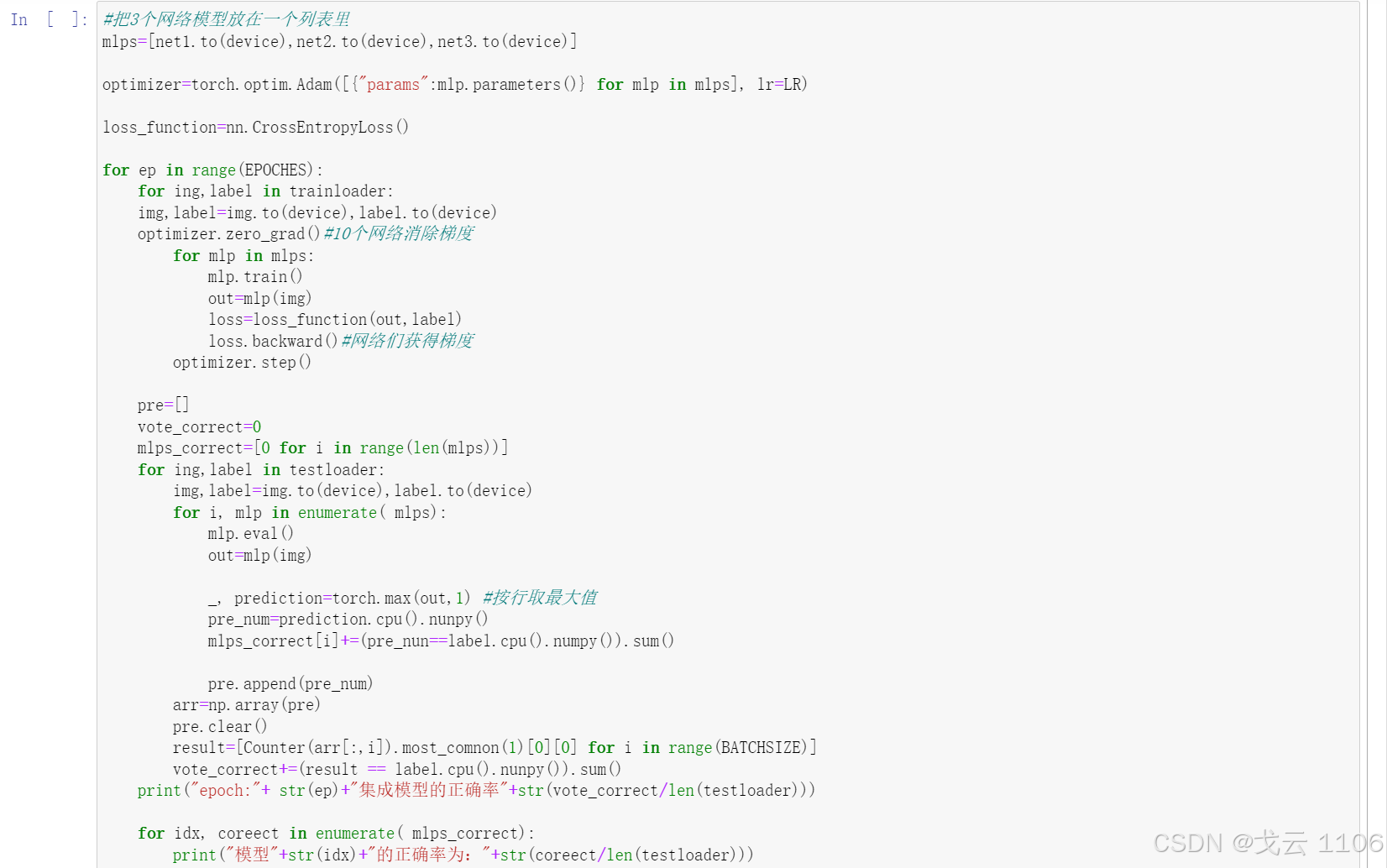
模型集成方法采用类似投票机制的方法,具体代码如下:
#把3个网络模型放在一个列表里
mlps=[net1.to(device),net2.to(device),net3.to(device)]
optimizer=torch.optim.Adam([{"params":mlp.parameters()} for mlp in mlps], lr=LR)
loss_function=nn.CrossEntropyLoss()
for ep in range(EPOCHES):
for ing,label in trainloader:
img,label=img.to(device),label.to(device)
optimizer.zero_grad()#10个网络消除梯度
for mlp in mlps:
mlp.train()
out=mlp(img)
loss=loss_function(out,label)
loss.backward()#网络们获得梯度
optimizer.step()
pre=[]
vote_correct=0
mlps_correct=[0 for i in range(len(mlps))]
for ing,label in testloader:
img,label=img.to(device),label.to(device)
for i, mlp in enumerate( mlps):
mlp.eval()
out=mlp(img)
_, prediction=torch.max(out,1) #按行取最大值
pre_num=prediction.cpu().nunpy()
mlps_correct[i]+=(pre_nun==label.cpu().numpy()).sum()
pre.append(pre_num)
arr=np.array(pre)
pre.clear()
result=[Counter(arr[:,i]).most_comnon(1)[0][0] for i in range(BATCHSIZE)]
vote_correct+=(result == label.cpu().nunpy()).sum()
print("epoch:"+ str(ep)+"集成模型的正确率"+str(vote_correct/len(testloader)))
for idx, coreect in enumerate( mlps_correct):
print("模型"+str(idx)+"的正确率为:"+str(coreect/len(testloader)))
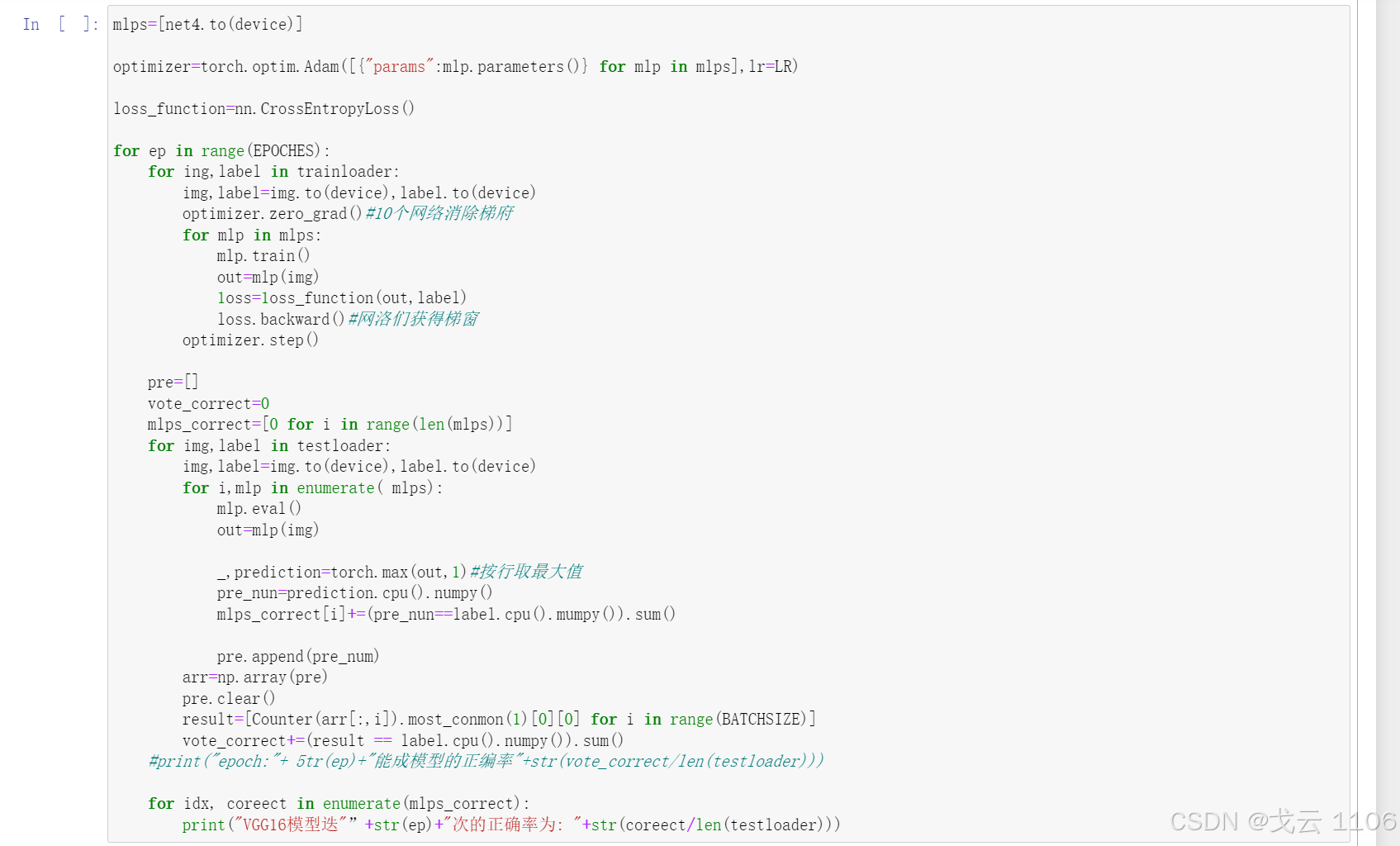
mlps=[net4.to(device)]
optimizer=torch.optim.Adam([{"params":mlp.parameters()} for mlp in mlps],lr=LR)
loss_function=nn.CrossEntropyLoss()
for ep in range(EPOCHES):
for ing,label in trainloader:
img,label=img.to(device),label.to(device)
optimizer.zero_grad()#10个网络消除梯府
for mlp in mlps:
mlp.train()
out=mlp(img)
1oss=1oss_function(out,label)
loss.backward()#网洛们获得梯窗
optimizer.step()
pre=[]
vote_correct=0
mlps_correct=[0 for i in range(len(mlps))]
for img,label in testloader:
img,label=img.to(device),label.to(device)
for i,mlp in enumerate( mlps):
mlp.eval()
out=mlp(img)
_,prediction=torch.max(out,1)#按行取最大值
pre_nun=prediction.cpu().numpy()
mlps_correct[i]+=(pre_nun==label.cpu().mumpy()).sum()
pre.append(pre_num)
arr=np.array(pre)
pre.clear()
result=[Counter(arr[:,i]).most_conmon(1)[0][0] for i in range(BATCHSIZE)]
vote_correct+=(result == label.cpu().numpy()).sum()
#print("epoch:"+ 5tr(ep)+"能成模型的正编率"+str(vote_correct/len(testloader)))
for idx, coreect in enumerate(mlps_correct):
print("VGG16模型迭"”+str(ep)+"次的正确率为: "+str(coreect/len(testloader)))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









