






图像识别课堂总结
一、线性回归和softmax回归
1. 线性回归
用途:预测连续值(如房价估计)。
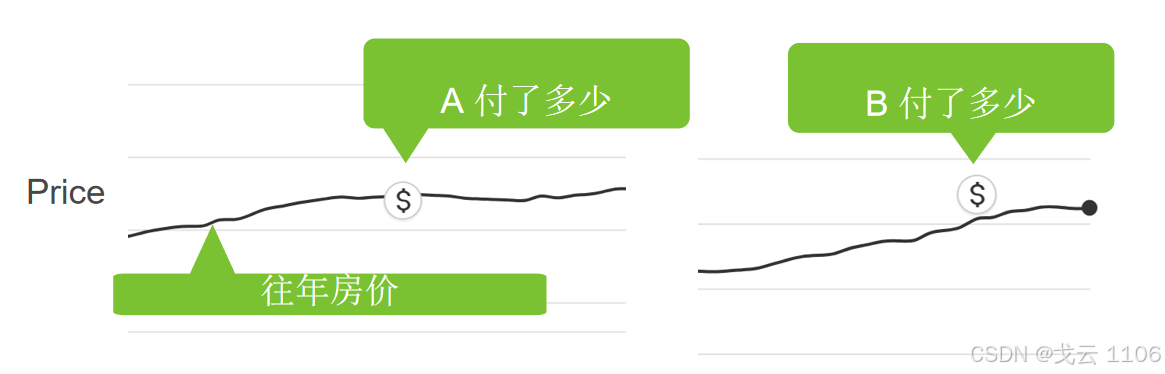
核心:通过训练数据学习参数(权重和偏置),使用损失函数(如均方误差)衡量预测值与真实值的差距。
优化方法:
梯度下降:沿梯度反方向更新参数,逐步降低损失。
随机梯度下降(SGD):每次随机选取样本更新参数,计算高效但波动大。
小批量随机梯度下降:折中方案,平衡计算资源与稳定性(深度学习默认算法)。
超参数:
学习率(太小收敛慢,太大可能震荡)。
批量大小(太小浪费计算资源,太大降低更新频率)。
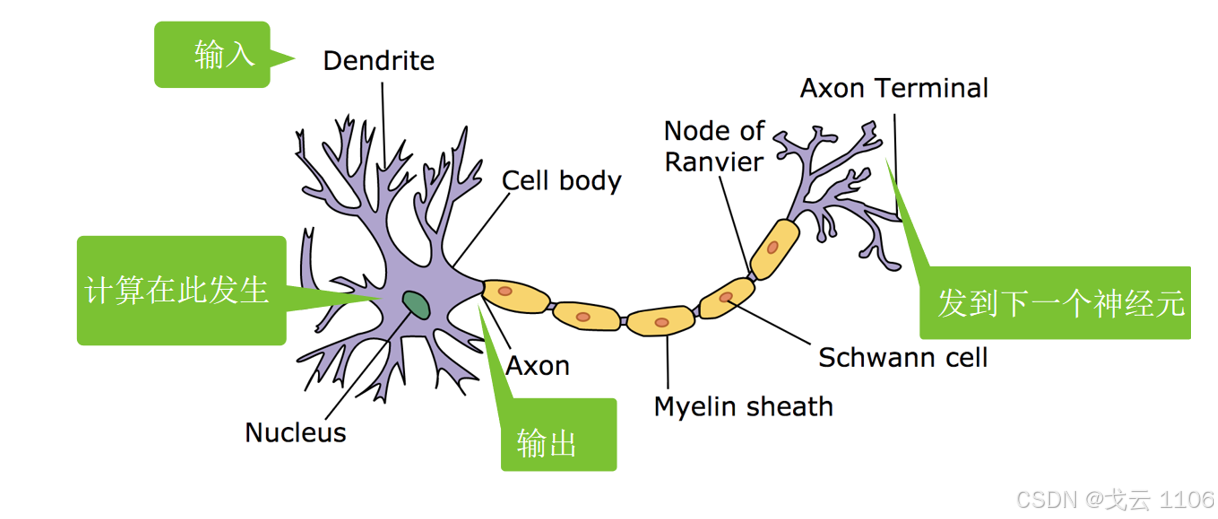
2. 神经网络
从输入端计算到输出端输出,再输出到下一层最后发到下一个神经元。
3.基础优化算法
梯度法
神经网络在学习时找到最优的参数(权重和偏置)——指损失函数取最小值时的参数。我们不知道他在何处能取得最小值,所以使用梯度来寻找函数的最小值的方法就是梯度法。
严格的讲,梯度指示的反向是各点处的函数值减小最多的方向
随机梯度下降
它通过不断的在损失函数递减的方向上更新参数来降低误差。
梯度:使得函数值增加最快的方向,更新权重的方向
学习率:步长的超参数,每次沿梯度方向一步走多远
选择批量值
批量值不能太小:批量值太小,难以充分利用计算资源
批量值不能太大:批量值太大,浪费计算资源;
4.从回归到多类分类
回归:单个连续数值输出自然区间与真实值的区别作为损失
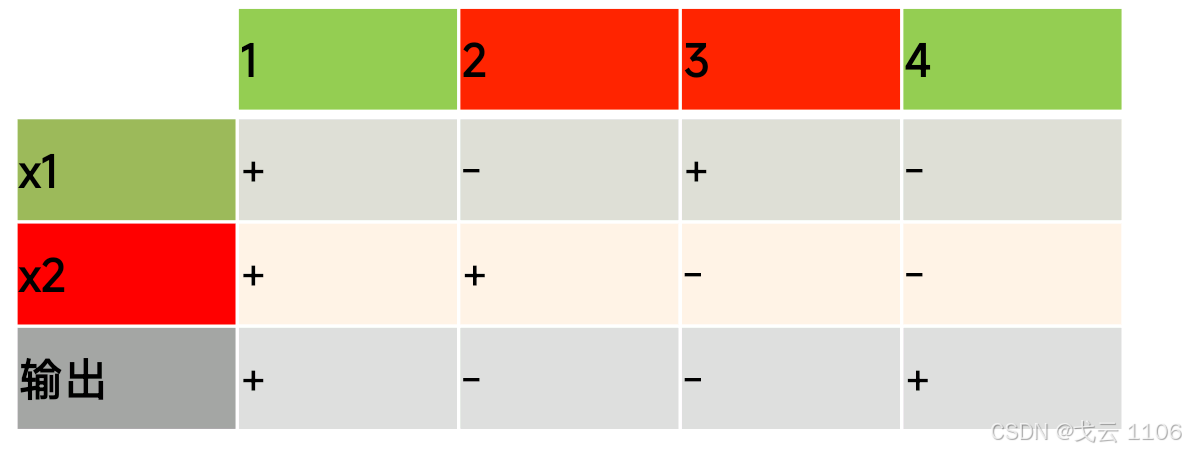
分类:通常多个输出输出的i表示预测为第i类的置信度
独热编码、使用均方损失训练、最大值作为预测
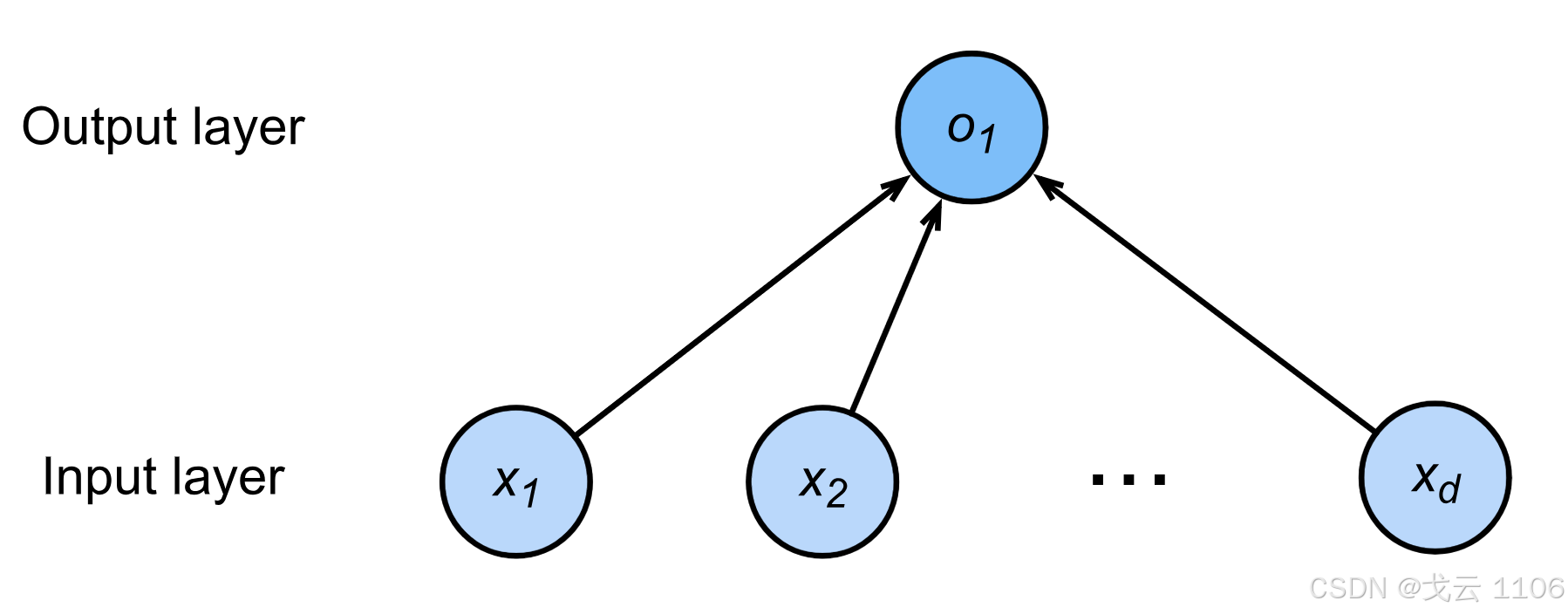
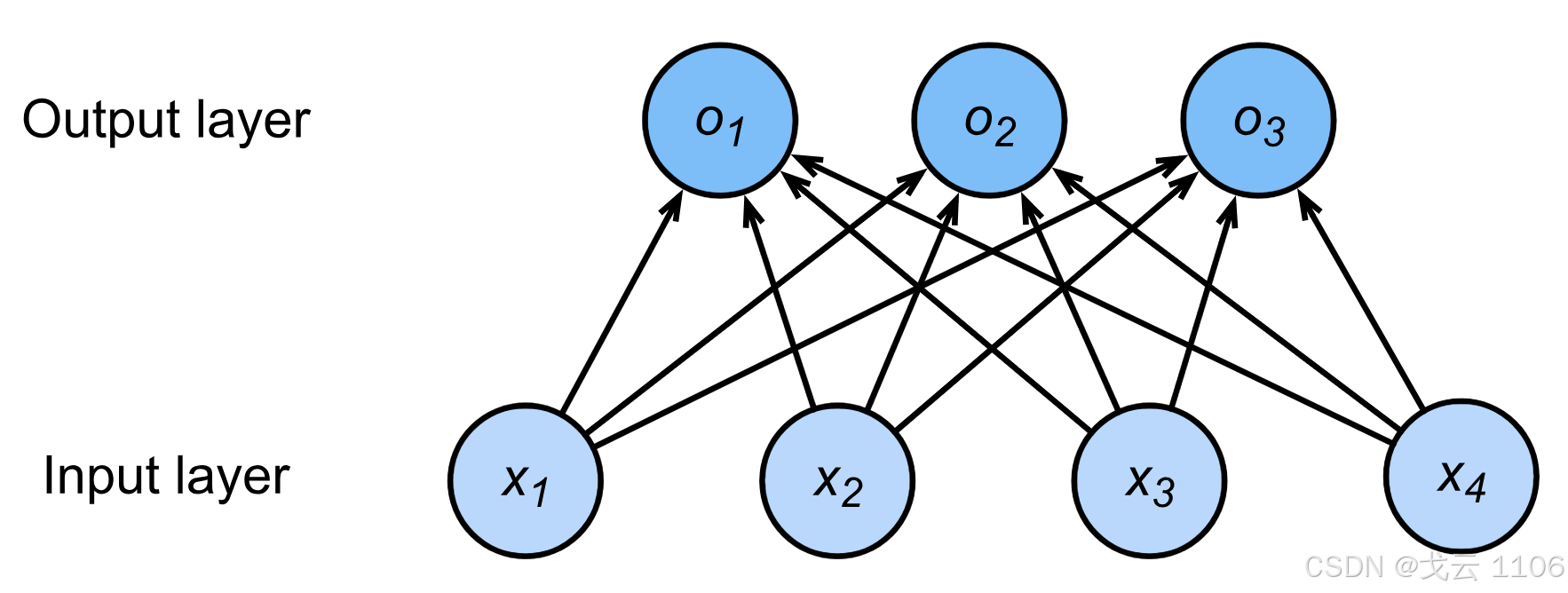
一个单层神经网络;
由于计算每个输出o1,o2,o3取决于所有输入x1、x2、x3和x4,因此softmax回归层也是全连接层。
5. Softmax回归
运算:输出匹配概率(非负,和为1)用 exp 获得大于0的值除以总和以获得概率分布。
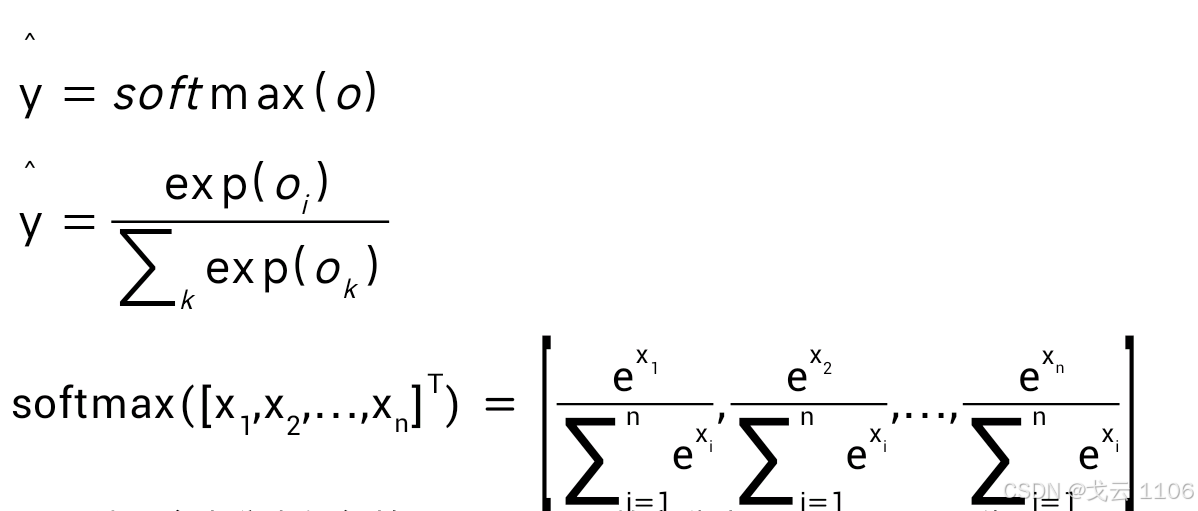
用途:多类分类任务(如MNIST手写数字分类、ImageNet图像分类)。
核心:
输出层神经元数等于类别数,每个输出表示对应类别的置信度。
Softmax运算:将输出转化为概率分布(非负且和为1),例如 `exp(o_i)/Σexp(o_j)`。
损失函数:
交叉熵损失:衡量预测概率分布与真实分布的差异,更适合分类任务(相比平方损失)。
特点:
全连接层结构,所有输入特征共同影响每个输出。
输出结果可解释为类别概率。
二.多层感知机
1.感知机基础
定义:1957年由美国学者Frank Rosenblatt提出,一种二分类模型(输出0或1)。

结构:输入权重(\(w\))和偏置(\(b\)),通过线性加权和激活函数(如阶跃函数)生成输出。
应用:实现简单逻辑门(与门、或门、与非门),但无法直接解决异或门问题(线性不可分)。
2.感知机的局限性
只能处理线性可分问题,无法表达复杂非线性关系(如异或逻辑)。
解决方案:引入多层感知机(MLP),通过隐藏层和非线性激活函数构建非线性模型。
3.多层感知机(MLP)
核心改进:
增加隐藏层和激活函数(如ReLU、Sigmoid、Tanh),解决线性不可分问题。
激活函数需满足:非线性、计算高效、导数值域合理(避免梯度爆炸/消失)。
常见激活函数:
ReLU:简单高效,缓解梯度消失问题。
Sigmoid/Tanh:将输出压缩到特定区间(如(0,1)或(-1,1)),但可能引发梯度饱和。
4.网络结构与超参数
隐藏层设计:
层数和每层神经元数为超参数,需根据任务调整。
输出层使用Softmax处理多分类问题(如MNIST手写数字识别)。
学习过程:
前向传播:输入→隐藏层→输出层,逐层计算。
反向传播:基于损失函数(如交叉熵)计算梯度,更新权重(优化算法如梯度下降)。
5.模型评估与优化
误差类型:
训练误差:模型在训练集上的误差(可能过拟合)。
泛化误差:模型在新数据上的误差(反映实际性能)。
数据划分:
验证集:用于调参(如K折交叉验证),避免使用测试集调参。
测试集:仅用于最终评估(类似高考,严格一次性使用)。
过拟合与欠拟合:
过拟合:模型过度拟合训练数据细节(解决方案:权重衰减、暂退法)。
欠拟合:模型未充分学习数据规律(需增加模型复杂度或数据量)。
关键实践方法
K折交叉验证:数据不足时,将训练集分为K份,轮流作为验证集,取平均误差。
模型复杂度控制:平衡参数数量与数据复杂度(如样本量、特征多样性)。
三、卷积神经网络
1. 全连接层的问题
多层感知机(MLP)需将图像展平为一维向量,丢失空间结构信息。
高分辨率图像(如3600万像素)使用MLP会导致参数量爆炸(例如36亿参数),远超实际需求。
2. 卷积神经网络(CNN)的优势
参数共享与池化显著减少参数量。
两大核心原则:
平移不变性:不管检测对象出现在图像中的哪个位置,神经网络的前面几层都应该对相同的图像区域具有相似的反应。
局部性:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远的区域的关系。
3. CNN基础组件
卷积层:通过卷积核提取特征,支持多输入/输出通道(如RGB图像)。
填充(Padding):在输入边缘补零,控制输出尺寸。
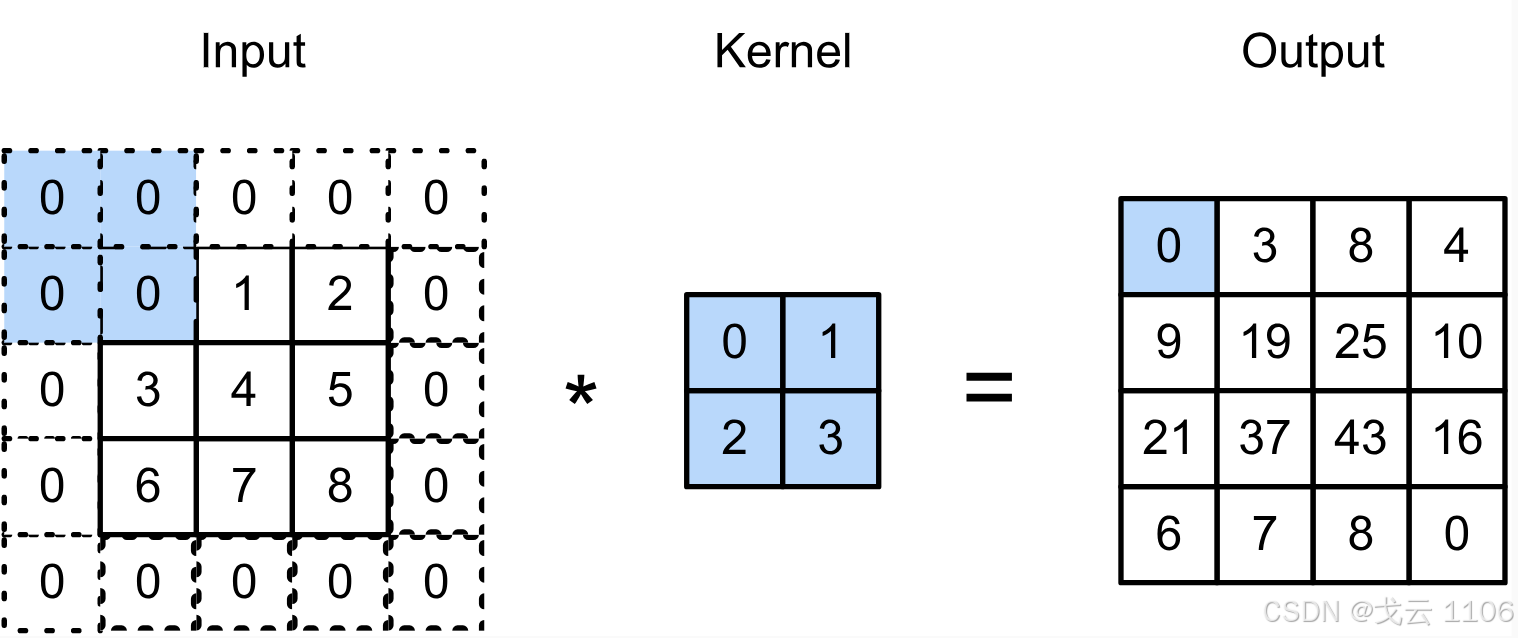
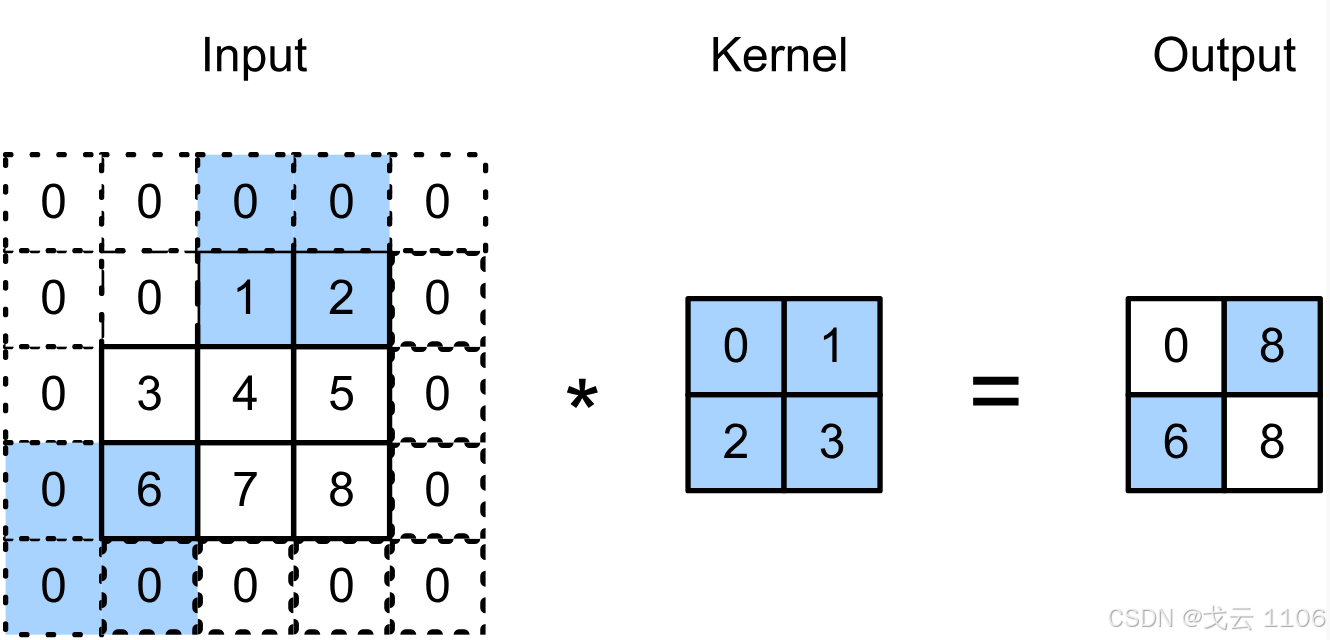
步幅(Stride):调整卷积核滑动步长,减少输出尺寸。
池化层:最大池化(保留显著特征)和平均池化(平滑特征)。
4. 经典网络架构
LeNet(1995):
首个成功CNN,用于手写数字识别。
结构:2个卷积层 + 池化层 → 3个全连接层。
激活函数:Sigmoid。
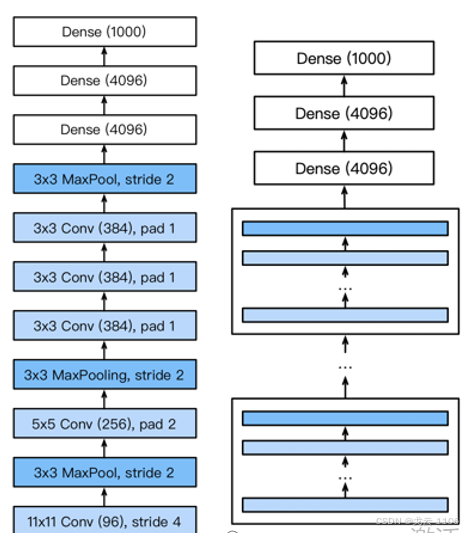
AlexNet(2012):
ImageNet竞赛冠军,推动深度学习发展。
改进:
使用ReLU激活函数(缓解梯度消失)。
引入Dropout(防止过拟合)。
数据增强与最大池化。
结构:5卷积层 + 2全连接隐藏层 → 输出层。
VGG(2014):
核心思想:重复堆叠3×3卷积块**构建深层网络(如VGG-16、VGG-19)。
优势:更深的网络提取更高层次特征,性能优于AlexNet。
5. 视觉分层理论
浅层:提取边缘、颜色等底层特征。
中层:提取条纹、形状等纹理特征。
高层:提取语义特征(如物体部件)。
6. 发展脉络
LeNet → AlexNet → VGG:网络深度和复杂度逐步增加,性能显著提升。
关键改进:ReLU、Dropout、数据增强、模块化设计(VGG块)。
四、Pytorch神经网络工具箱
1. 核心组件
`nn.Module`:
继承自基类,自动管理可学习参数(如权重、偏置)。
适用于卷积层、全连接层、Dropout层等。
可与`nn.Sequential`结合使用,且能自动切换训练/测试状态(如Dropout)。
`nn.functional`:
提供函数式接口(如激活函数、池化)。

2. 模型构建方法
继承`nn.Module`基类:
自定义网络结构,灵活定义前向传播逻辑。
使用`nn.Sequential`:
按顺序堆叠层,支持三种方式:
1.可变参数(无层名)
2.add_module`方法(添加命名层)
3.`OrderedDict`(有序字典命名层)
模型容器:
`nn.ModuleList`:存储子模块列表,支持动态扩展。
`nn.ModuleDict`:以字典形式管理子模块。
3. 自定义网络模块
残差块(Residual Block):
类型1:输入与输出直接相加,后接ReLU激活。
类型2:通过1×1卷积调整输入通道/分辨率,确保形状匹配。
组合两种模块可构建经典网络(如ResNet18)。
4. 模型训练流程
1. 数据准备:加载并预处理数据集。
2. 定义损失函数:如交叉熵损失(`nn.CrossEntropyLoss`)。
3. 选择优化器:如SGD、Adam。
4. 训练循环:前向传播→计算损失→反向传播→参数更新。
5. 验证/测试循环:评估模型性能。
6. 结果可视化:如损失曲线、准确率曲线。
五、Pytorchon神经网络工具箱
1. 数据加载工具(`utils.data`)
`Dataset`:
基础数据容器,需实现`__getitem__`方法以支持单样本读取。
`DataLoader`:
批量加载数据,支持多进程加速(`num_workers`参数)。
关键参数:
`batch_size`:批量大小。
`shuffle`:是否打乱数据顺序。
`drop_last`:是否丢弃最后不足一个批次的数据。
`pin_memory`:是否将数据固定到显存以加速GPU传输。
注意事项:
`DataLoader`本身不是迭代器,需通过`iter()`转换后遍历。
数据分散在不同目录时,直接使用`DataLoader`可能不便,需结合`ImageFolder`。
2. 数据预处理工具(`torchvision.transforms`)
功能:
对PIL Image和Tensor进行常见操作(如裁剪、缩放、归一化等)。
组合操作:
使用`Compose`将多个预处理步骤串联,类似`nn.Sequential`。
示例:
```python
transform = transforms.Compose([
transforms.Resize(256),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
```
3. 图像数据读取工具(`ImageFolder`)
功能:
自动读取按类别分目录存储的图像数据(如`train/dog/xxx.jpg`、`train/cat/yyy.jpg`)。
返回格式为`(图像路径, 类别索引)`,需搭配`DataLoader`批量加载。

4. 可视化工具(TensorBoard)
使用步骤:
1. 初始化日志记录器:
```python
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir='logs')
```
2. 记录数据:
常用API:
`add_scalar`:记录标量(如损失值)。
`add_image`:记录图像。
`add_graph`:可视化模型结构。
示例:
```python
writer.add_scalar('Loss/train', loss, epoch)
```
3. 启动服务:
命令行输入:
```bash
tensorboard --logdir=logs --port 6006
```
4. Web查看:
浏览器访问`http://localhost:6006`。
5. 其他注意事项
`DataLoader`的采样器:
`sampler`控制单样本采样逻辑,`batch_sampler`控制批次采样逻辑。
数据目录结构:
`ImageFolder`要求子目录名对应类别标签(如`类别1/`、`类别2/`)。
TensorBoard扩展功能:
支持特征图、模型计算图、直方图等高级可视化。
六、图像分类项目
1. 图像分类定义与层次
定义:将不同图像划分到指定类别,最小化分类误差。
分类层次:
通用多类别分类:基础分类任务(如猫、狗、鸟等大类)。


2. 子类细粒度分类:区分同一大类下的子类(如不同犬种)。


实例级分类:识别具体实例(如特定个体的猫)。

2. 评估指标
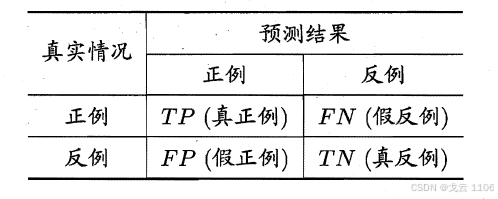
混淆矩阵:
TP(真正例):正确预测的正类样本。
FP(假正例):错误预测的正类样本。
TN(真反例):正确预测的负类样本。
FN(假反例):错误预测的负类样本。
关键指标:
精确率(Accuracy):总正确样本数 / 总样本数,衡量整体正确率。
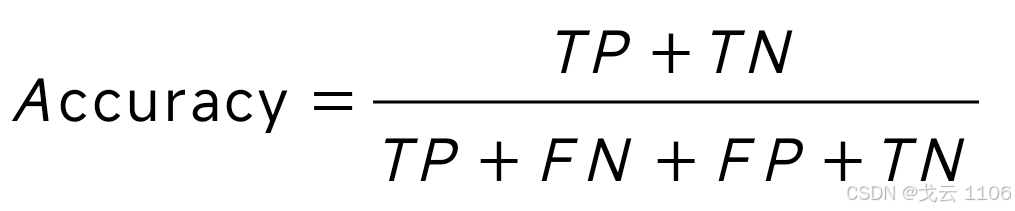
准确率(Precision):预测为正类的样本中实际为正类的比例(查准率)。
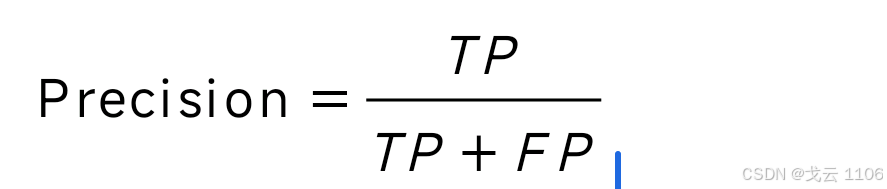
召回率(Recall):实际正类样本中被正确预测的比例(查全率)。
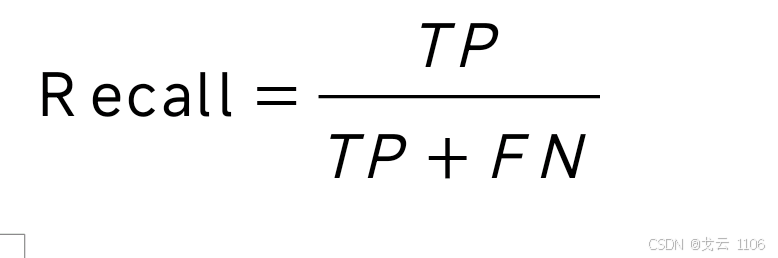
F1 Score:Precision与Recall的调和平均数,综合平衡查准与查全。
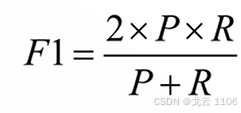
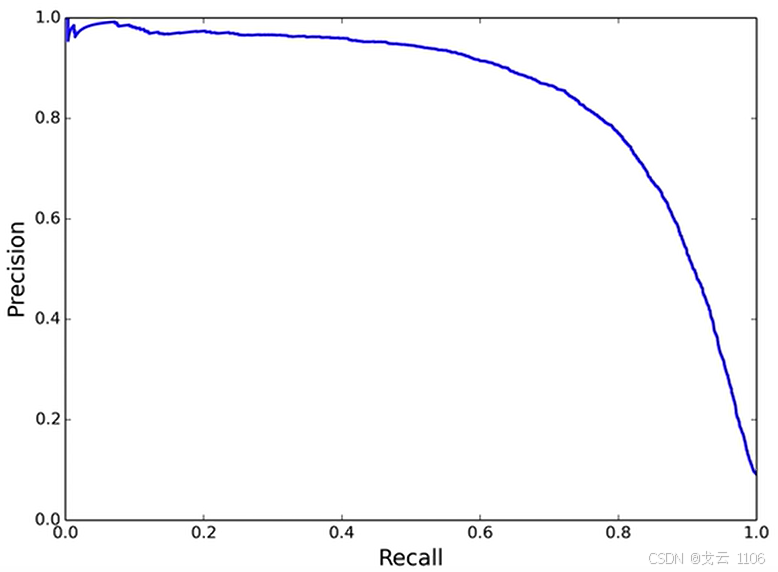
P-R曲线:横轴为召回率,纵轴为精确率,面积越大模型性能越好。
多类别混淆矩阵:
大小为`k×k`(k为类别数),对角线表示正确分类样本数,非对角线表示错误分类。
3. 模型设计关键概念
网络深度:最长路径中卷积层+全连接层的数量(如LeNet-5为5层)。
网络宽度:每一层的通道数(如LeNet的C1层为6通道,C3层为16通道)。
4. 样本量过少的解决方案
迁移学习:
使用预训练模型(如ImageNet)作为特征提取器,加速收敛并提升小数据集性能。
数据增强:
有监督方法:基于标签的变换(平移、翻转、亮度/对比度调整、裁剪、缩放等)。
无监督方法:通过GAN生成新样本,扩充数据集。
5. 模型基本概念
1.网络的深度
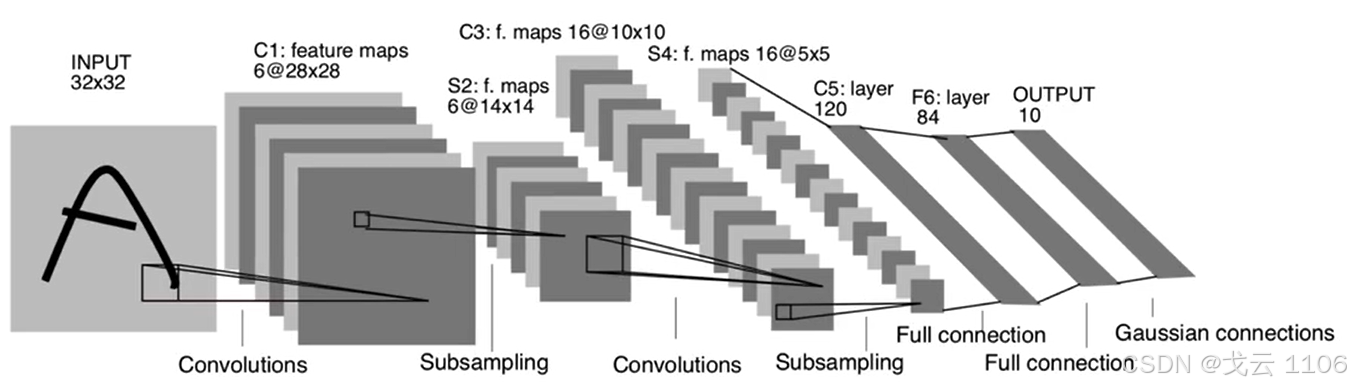
深度学习最重要的属性,计算最长路径的卷积层+全连接层数量。LeNet网络,C1+C3+C5+F6+Output共5层
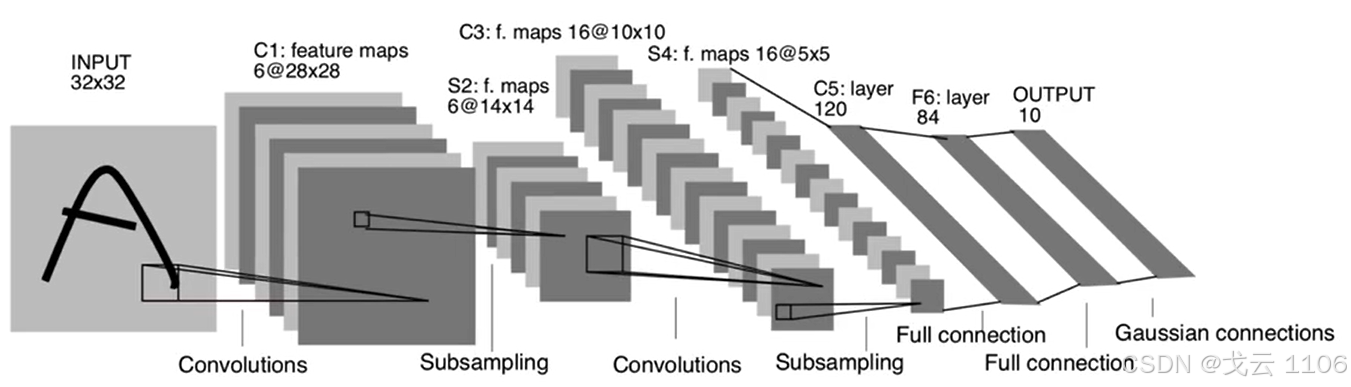
2.网络的宽度
每一个网络层的通道数,以卷积网络层计算。LeNet网络,C1(6),C3(16)。
图像分类中样本量过少的问题
样本量极少:样本获取较难导致总体样本量过少。
解决方案1迁移学习:使用预训练模型。
ImageNet数据集具有通用性,使用它进行预训练可加速模型收敛。
解决方案2数据增强(有监督方法与无监督方法)
有监督方法:平移、翻转、亮度、对比度、裁剪、缩放等。
无监督方法:通过GAN网络生成所需样本,然后再进行训练。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









