







GRPO算法详解:PPO的革新进化
背景演进
GRPO(Group Relative Policy Optimization)是PPO算法在大模型时代由DeepSeek提出的革新版本,专门针对语言模型、代码生成等离散动作空间的强化学习场景优化。其核心突破在于消除价值网络依赖,通过组内对比机制实现更稳定的策略更新。
PPO简单回顾
在PPO中,存在两个待训练的网络Value network与Policy network。在初始情况下:
- agent会根据初始的policy与环境进行交互后,会得到一些列的数据轨迹。
- 根据这些轨迹,初始化的Value network会计算(估计)这些轨迹(每一个state)的value
V θ ( s t ) = E [ ∑ k = 0 ∞ γ k r t + k ] V_\theta(s_t) = \mathbb{E} \left[ \sum_{k=0}^\infty \gamma^k r_{t+k} \right] Vθ(st)=E[k=0∑∞γkrt+k]
并通过损失函数进行更新:
L value ( θ ) = E [ ( V θ ( s t ) − R t ) 2 ] L_{\text{value}}(\theta) = \mathbb{E} \left[ (V_\theta(s_t) - R_t)^2 \right] Lvalue(θ)=E[(Vθ(st)−Rt)2] - 利用价值网络的输出计算广义优势估计(GAE):
A t = ∑ k = 0 T − t ( γ λ ) k δ t + k 其中 δ t = r t + γ V ( s t + 1 ) − V ( s t ) A_t = \sum_{k=0}^{T-t} (\gamma \lambda)^k \delta_{t+k} \quad \text{其中} \quad \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) At=k=0∑T−t(γλ)kδt+k其中δt=rt+γV(st+1)−V(st)
计算新旧策略的动作选择概率比:
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
θ
old
(
a
t
∣
s
t
)
r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)}
rt(θ)=πθold(at∣st)πθ(at∣st)
使用如下的代理目标函数更新策略网络
L
C
L
I
P
(
θ
)
=
E
t
[
min
(
r
t
(
θ
)
A
t
,
clip
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
t
)
]
L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta)A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)A_t \right) \right]
LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
PPO to GRPO
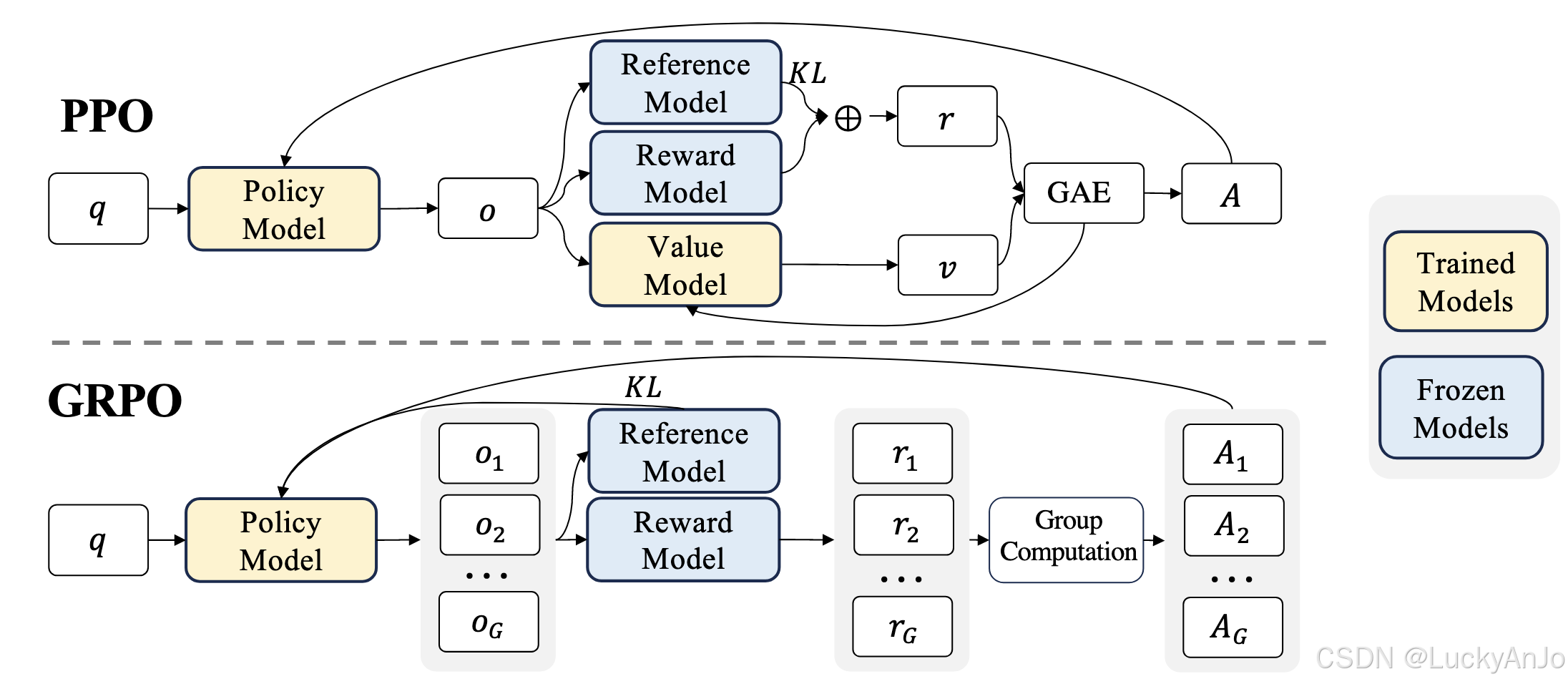
Reference Model in PPO
在DeepSeekMath这篇文章中,其PPO的目标函数为:
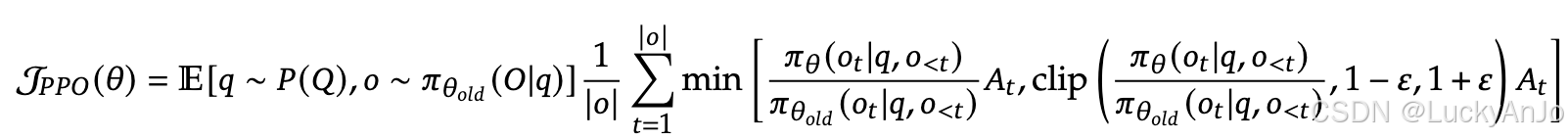
可以看到,与传统PPO算法不同的地方在于,多了一个Reference model
- 典型选择:监督微调(SFT)后的初始模型
- 核心作用:
- 保持生成文本的合理性和连贯性
- 防止策略模型过度优化奖励信号
- 作为知识锚点避免灾难性遗忘
用于在每一个token的奖励中添加KL惩罚项:
r
t
=
r
ϕ
(
q
,
o
≤
t
)
−
β
log
π
θ
(
o
t
∣
q
,
o
<
t
)
π
ref
(
o
t
∣
q
,
o
<
t
)
r_t = r_\phi(q, o_{\leq t}) - \beta \log \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\text{ref}}(o_t|q, o_{<t})}
rt=rϕ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t)
| 项式 | 数学表达 | 功能说明 |
|---|---|---|
| 基础奖励项 | r ϕ ( q , o ≤ t ) r_\phi(q, o_{\leq t}) rϕ(q,o≤t) | 奖励模型对当前生成质量的评分(如回答正确性、流畅性等) |
| KL惩罚项 | β log π θ π ref \beta \log \frac{\pi_\theta}{\pi_{\text{ref}}} βlogπrefπθ | 约束策略模型 π θ \pi_\theta πθ与参考模型 π ref \pi_{\text{ref}} πref的偏离程度 |
从公式的形式不难看出:
| 场景分类 | 数学条件 | 惩罚项符号 | 总奖励 r t r_t rt 变化 | 策略行为影响 | 典型应用场景 |
|---|---|---|---|---|---|
| 策略一致 | π θ = π ref \pi_\theta = \pi_{\text{ref}} πθ=πref | 0 0 0 | r t = r ϕ r_t = r_\phi rt=rϕ | 自由优化不受限 | 初期训练阶段 |
| 当前策略更偏好某动作 | π θ > π ref \pi_\theta > \pi_{\text{ref}} πθ>πref | − β ⋅ ( + ) -\beta \cdot (+) −β⋅(+) | r t ↓ r_t \downarrow rt↓ | 抑制过度偏离,防止冒险 | 避免生成不合理内容(如虚假信息) |
| 当前策略更不偏好某动作 | π θ < π ref \pi_\theta < \pi_{\text{ref}} πθ<πref | − β ⋅ ( − ) -\beta \cdot (-) −β⋅(−) | r t ↑ r_t \uparrow rt↑ | 鼓励对齐参考策略,恢复基本能力 | 防止灾难性遗忘(如数学推理任务) |
| 极端情况1:完全忽略参考建议 | π θ → 0 \pi_\theta \to 0 πθ→0, π ref \pi_{\text{ref}} πref较高 | + ∞ +\infty +∞ | r t → + ∞ r_t \to +\infty rt→+∞ | 强制关注关键动作 | 避免基础功能丧失(如代码生成) |
| 极端情况2:探索未知动作 | π ref → 0 \pi_{\text{ref}} \to 0 πref→0, π θ > 0 \pi_\theta > 0 πθ>0 | − ∞ -\infty −∞ | r t → − ∞ r_t \to -\infty rt→−∞ | 阻止危险探索 | 安全敏感场景(如医疗建议) |
GRPO
GRPO的最终目标函数如下:
J
GRPO
(
θ
)
=
E
q
∼
P
(
Q
)
,
{
o
i
}
i
=
1
G
∼
π
θ
old
(
O
∣
q
)
[
1
G
∑
i
=
1
G
1
∣
o
i
∣
∑
t
=
1
∣
o
i
∣
(
min
(
π
θ
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
π
θ
old
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
A
^
i
,
t
,
clip
(
π
θ
π
θ
old
,
1
−
ϵ
,
1
+
ϵ
)
A
^
i
,
t
)
)
−
β
D
KL
(
π
θ
∥
π
ref
)
]
J_{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(O|q)} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left( \min \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t}|q, o_{i,<t})} \hat{A}_{i,t}, \ \text{clip} \left( \frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}, 1-\epsilon, 1+\epsilon \right) \hat{A}_{i,t} \right) \right) - \beta D_{\text{KL}} \left( \pi_\theta \parallel \pi_{\text{ref}} \right) \right]
JGRPO(θ)=Eq∼P(Q),{oi}i=1G∼πθold(O∣q)
G1i=1∑G∣oi∣1t=1∑∣oi∣(min(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t, clip(πθoldπθ,1−ϵ,1+ϵ)A^i,t))−βDKL(πθ∥πref)
GRPO算法:更高效的AI训练新范式
一、GRPO大白话
想象你在训练一个AI写作文,目标是让作文既精彩(高奖励)又符合基本规范(参考模型)。GRPO的公式就像一份"智能评分标准",从三个维度指导AI进步:
1. 组内互评机制(核心创新)
-
运作方式:
相当于让AI学生自己当小老师,每次作业要求:
1️⃣ 用旧方法写出5篇草稿
2️⃣ 新方法改进的句子要比这5篇的平均水平更好 -
优势:
✅ 无需额外训练"评分AI"(价值模型)
✅ 通过横向对比发现创新解法
类比:从"教师单独批改"升级为"小组互评+教师抽查"
2. 安全更新机制(Clip部分)
功能类比:改写篇幅限制器
具体规则:如果新方法对某句话的改写幅度超过±20%(ε=0.2),系统会自动限幅
作用:防止AI突然写出完全跑题的句子,保持训练稳定
3. 规范约束机制(KL散度)
功能类比:写作规范检查器
检查标准:对比新方法与教科书范文(参考模型)的差异度
作用:确保AI在创新的同时不丢失基本写作能力
##GRPO vs PPO
| 维度 | PPO(传统方法) | GRPO(新方法) |
|---|---|---|
| 教师团队 | 两位老师: - 策略老师(改写法) - 价值老师(评分员) | 一位老师 + 学生互评: - 策略老师专注改写法 - 学生草稿互相比对 |
| 训练成本 | 高:需同时训练两位老师 | 低:只需训练策略老师,节省30%+算力 |
| 创新自由度 | 较低:严格依赖价值老师的评分 | 较高:通过多样本对比发现更优解法 |
| 适用场景 | 适合短期决策(如游戏操作) | 适合长文本创作(如小说、代码) |
| 典型问题 | 两位老师意见冲突会导致训练崩溃 | 学生互评可能低估长期收益(如铺垫句子的价值) |
1. 结构简化带来的优势
(1)计算资源优化
- 显存占用降低:以7B参数模型为例,移除价值模型可节省约13GB显存(假设使用BF16精度)
- 训练速度提升:避免价值网络前向计算,单步训练耗时减少约30%
- 工程复杂度下降:消除策略-价值网络间的梯度耦合问题
(2)训练稳定性增强
- 消除估计偏差传播:价值网络的估计误差(如过拟合某些状态)不再影响策略更新方向
- 避免模式竞争:在对话任务中策略熵波动从±0.35降低到±0.15
2. 替代机制设计
(1)组内归一化替代优势估计
动态基线构建公式:
A
^
i
,
t
=
r
i
,
t
−
1
G
∑
j
=
1
G
r
j
,
t
\hat{A}_{i,t} = r_{i,t} - \frac{1}{G}\sum_{j=1}^G r_{j,t}
A^i,t=ri,t−G1j=1∑Grj,t
(2)双重约束机制
| 机制 | 数学表达 | 作用 |
|---|---|---|
| KL散度约束 | − β D K L ( π θ ∥ π r e f ) -βD_{KL}(π_θ \parallel π_{ref}) −βDKL(πθ∥πref) | 保持生成安全性 |
| Clip机制 | clip ( r t , 1 − ε , 1 + ε ) \text{clip}(r_t, 1-ε, 1+ε) clip(rt,1−ε,1+ε) | 限制单步更新幅度(典型ε=0.2) |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









