






引言
在职业体育赛事中,主场优势(Home Field Advantage,HFA)是长期被关注的现象。传统统计方法多聚焦于胜率预测或描述性分析,但此类方法难以量化主场环境的因果效应。本文以英格兰顶级职业联赛(EPL)2020-2021赛季数据为例,系统阐述如何通过层次因果模型(Hierarchical Causal Model)与潜在结果框架(Potential Outcome Framework)构建严谨的因果推断流程,揭示主场效应对攻防指标与裁判判罚的影响机制。全文将详细解析数据预处理、模型构建、参数估计及结果解读的全流程技术细节。
一、数据架构与指标定义
1.1数据来源与特征选择
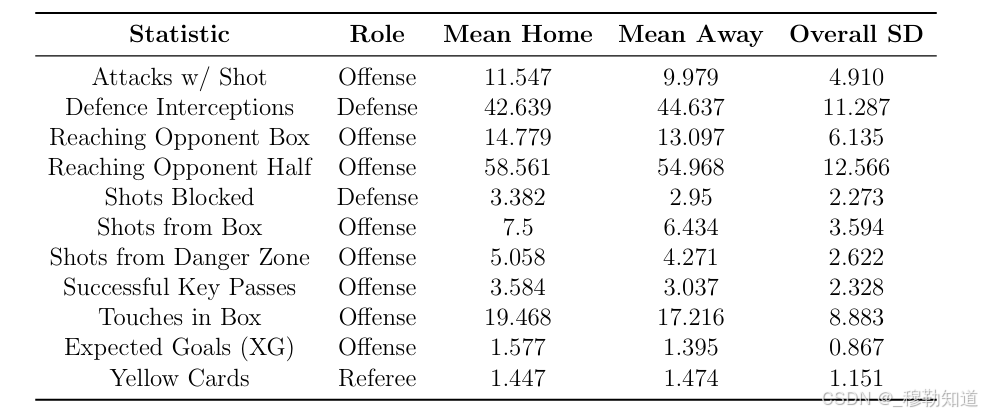
研究数据涵盖20支球队的380场赛事记录,每支球队与其余19支对手分别进行主客场各一次交锋。原始数据包含11项核心指标,分为进攻效能、防守效能与裁判判罚三类。例如:
- 进攻类指标:危险区域射门次数(Shots from Danger Zone)、成功关键传球(Successful Key Passes)
- 防守类指标:拦截次数(Defence Interceptions)、封堵射门(Shots Blocked)
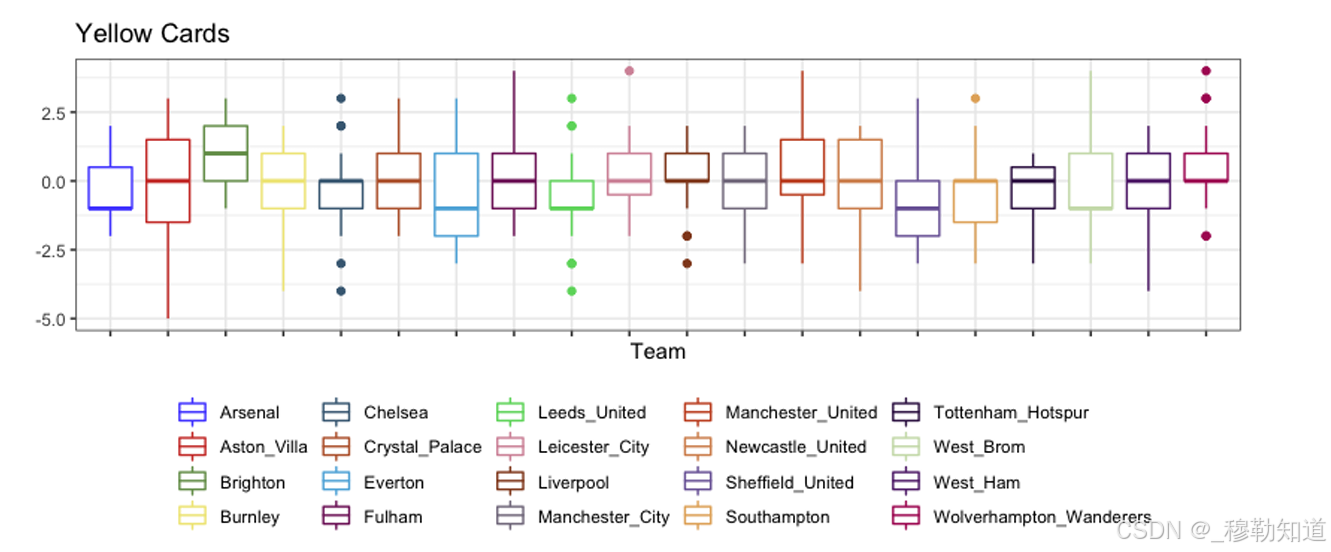
- 裁判类指标:黄牌数(Yellow Cards)
通过定义净差异值(Net Difference)作为观测结果变量:
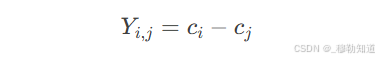
其中,ci与cj分别表示主场球队Ti与客场球队Tj在同一指标上的统计值。该设计将问题转化为对Y{i,j}的因果效应估计。
1.2潜在结果框架的适应性调整
传统因果推断常假设对照组(如中立场地)存在,但职业联赛中所有比赛均为主客场制。为此,引入对称匹配设计(Symmetric Match Design):
- 定义处理变量δi∈{0,1},当Ti为主场时δi=1,反之为0
- 潜在结果Y∗(δi=1,δj=0)表示Ti主场对阵Tj的理论结果
- 由于缺乏中立场地数据,需通过层次模型消除场地基线效应(Baseline Effect)的影响
二、层次因果模型构建
2.1模型形式化表达
假设联赛包含n支球队,每对球队进行两次交锋(主客场各一次)。定义以下结构方程:
主场模型: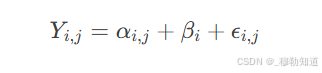
客场模型:
其中:
- αi,j表示假设中立场地下Ti与Tj的基线差异,满足αi,j=−αj,i
- βi为球队Ti的主场效应参数
- ϵi,j服从独立正态分布N(0,σ02)
2.2参数可识别性证明
将主客场模型相加可得:

该式消除基线参数αi,j,仅保留目标参数βi与βj。对全部N=n(n−1)场比赛构建线性方程组:
其中设计矩阵H∈RN/2×n为全秩矩阵(当n≥3时)。通过最小二乘法可得参数估计量:
联赛整体效应Δ=n1∑i=1nβi的估计量为:
2.3统计推断与协方差估计
基于线性模型理论,参数估计量的协方差矩阵为:
其中残差方差估计量:
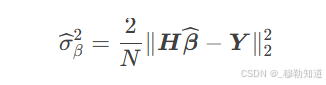
对于联赛效应Δ,其方差需考虑团队间异质性:
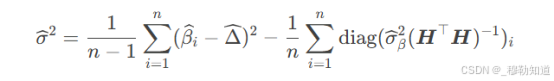
该公式通过总方差分解(Law of Total Variance)校正了估计偏差。
三、仿真验证与模型鲁棒性
3.1数据生成机制
为验证估计量性能,设置两种仿真场景:
1.独立基线场景:αi,j∼N(0,22)且αi,j=−αj,i
2.能力差异场景:生成球队能力值Abi∼N(0,22),并令αi,j=Abi−Abj
参数设定:Δ=1, βi∼N(1,0.32)βi∼N(1,0.32), ϵi,j∼N(0,σ02)ϵi,j∼N(0,σ02),变化σ02∈{0.5,1,2}与团队数n∈{10,20,40,80}。
3.2结果分析
偏差与覆盖概率:当n≥20时,Δ^的偏差趋近于零,95%置信区间覆盖概率稳定在93.3%~95.5%
方差估计精度:样本方差(SV)与估计方差(MV)的比值接近1,表明方差估计量无偏
团队效应估计:βi的箱线图显示,估计量在不同噪声水平下均保持对称分布,无系统性偏移
仿真结果表明,即便在基线参数非独立生成的场景下,模型仍能保持稳健性。
四、实证结果与战术启示
4.1主场效应的异质性
通过估计20支球队的βi发现:
- 低排名球队主场效应更强:降级区球队(如富勒姆)在进攻类指标上呈现显著正效应,其置信区间宽度达2.5~3.0个标准差
- 高排名球队效应不显著:联赛前三球队的主场效应多数指标未通过显著性检验(p>0.05),表明其竞技水平足以抵消场地差异
4.2指标敏感度排序
联赛整体效应Δ的显著性检验显示:
- 进攻类指标:进入对方半场次数(Reaching Opponent Half, Δ^=3.592Δ=3.592, p<0.001)、危险区域射门(Δ=0.786, p=0.005)
- 裁判类指标:黄牌数(Δ=−0.026, p=0.834)无显著偏差
- 防守类指标:封堵射门(Δ=0.350, p=0.287)效应微弱
结果表明,主场优势主要体现在空间控制与进攻机会创造,而非直接得分或裁判判罚。这暗示球队可通过强化主场场地熟悉度(如特定区域传球路线训练)放大战术优势。

五、技术扩展方向
5.1模型假设的松弛
当前框架假设噪声项服从正态分布,未来可引入稳健估计量(如Huber损失函数)或非参数Bootstrap法以降低分布依赖。此外,可扩展至多元响应模型(Multivariate Response Model),同时分析多指标间的协变关系。
5.2动态效应建模
将时间因素纳入层次模型,例如:
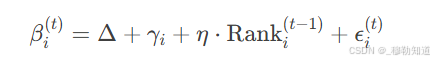
其中{Rank}i^{t1}表示球队上赛季排名,η为动态调节参数。此类扩展可捕捉主场效应的时序演变。
5.3因果中介分析
通过结构方程模型(Structural Equation Model)分解主场效应的传导路径:

可量化各因素(如旅行疲劳、设施熟悉度)的间接效应占比。
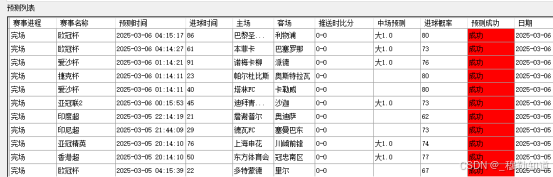
六、模型预测效果展示
预测成效
该预测模型依托于庞大的赛事数据,通过应用机器学习算法进行深度分析。经过精确的数据挖掘与算法处理,模型具备一定的赛事结果预测能力,其预测准确率约为80%。这一预测能力对赛事发展趋势的判断具有重要意义,为赛事分析提供了有价值的参考依据。
模型的80%准确率得益于多种先进技术的协同运作,诸如泊松分布和蒙特卡洛模拟等方法。这些技术从不同角度对赛事数据进行分析,有效提升了预测的准确性。该模型已被广泛应用于全球范围的赛事,通过筛选相关赛事并整理关键信息,为关注者提供数据支持,帮助优化体育赛事分析工作。
赛事监测成效
在赛事的进行过程中,监测模块发挥着关键作用。该模块利用先进的数据采集技术,实时捕捉比分和比赛进程等关键信息。这些数据一旦采集完成,便进入智能分析流程,通过高效的算法进行快速处理,最终转化为赛事分析和趋势预测结果。
随后,分析结果会即时推送给用户,帮助用户及时了解赛事动态,并基于科学分析对比赛走势进行合理预判。这一过程避免了盲目观赛,提升了用户对赛事的理解,同时优化了整体的观赛体验。
结语
本文构建的层次因果模型为职业联赛主场效应分析提供了可复现的技术框架。通过对称匹配设计与线性方程组求解,有效解决了传统方法中对照组缺失的难题。实证结果表明,主场优势本质上是空间控制效能的提升,而非简单的结果偏倚。该模型可进一步应用于球员交易评估、战术优化等场景,为数据驱动的体育科学提供方法论基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









