






一、高并发场景设计
1. 如何设计一个百万级QPS的秒杀系统?
实战方案:
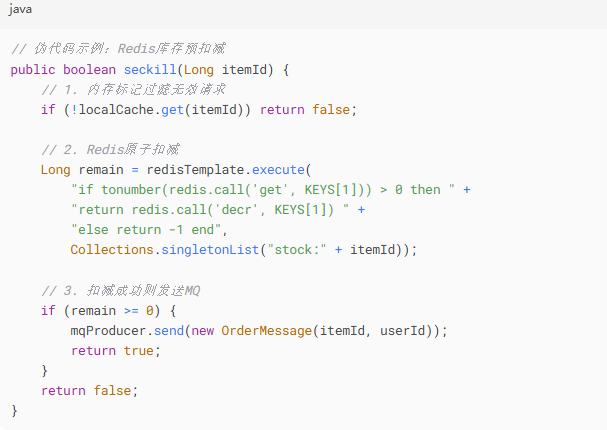
关键技术点:
-
分层削峰:静态页面 + Nginx限流 + 队列泄洪
-
库存预热:Redis集群预加载库存数据
-
热点隔离:单独Redis集群处理秒杀商品
-
熔断降级:当库存耗尽时直接返回售罄
二、分布式系统设计
2. 如何实现分布式系统唯一ID生成?
方案对比:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| UUID | 简单无网络依赖 | 无序且存储空间大 | 日志跟踪 |
| 数据库自增 | 绝对递增 | 单点故障风险 | 数据量小的内部系统 |
| Redis INCR | 性能好(10w+/s) | 依赖Redis可用性 | 中等规模分布式系统 |
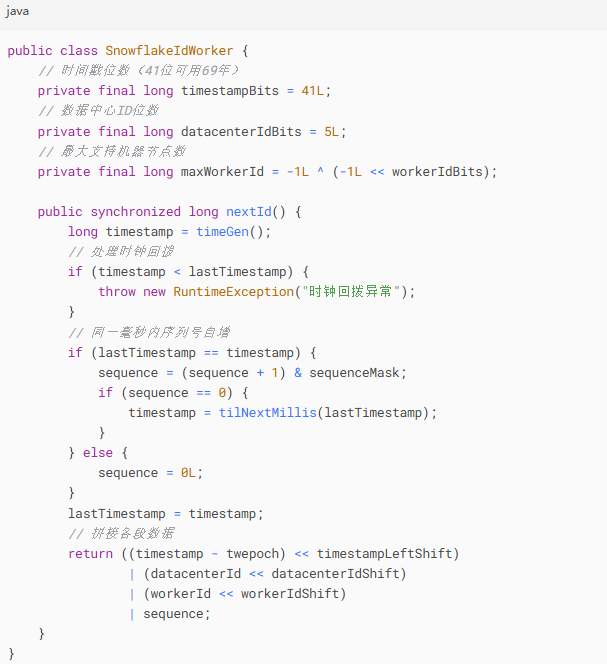
| Snowflake | 趋势递增且不依赖存储 | 时钟回拨问题 | 大型分布式系统 |
| Leaf-Segment | 高可用、号段缓冲 | 需要DB支持 | 电商、金融等业务系统 |
Snowflake实现要点:
三、缓存场景实战
3. 如何解决缓存穿透与雪崩?
组合拳解决方案:
缓存穿透应对:

缓存雪崩预防:
-
过期时间随机化:基础过期时间 + 随机偏移量(1-5分钟)
-
多级缓存架构:本地缓存(Caffeine)→ Redis集群 → DB
-
热点数据永不过期:后台定时更新
-
熔断降级机制:Hystrix/Sentinel保护DB
四、数据库优化场景
4. 十亿级数据分页查询优化
终极解决方案:
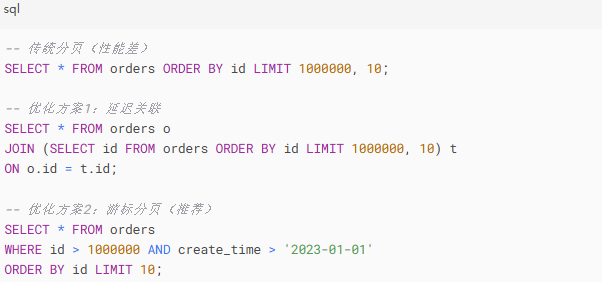
完整优化策略:
-
深度分页:使用ES search_after或游标方式
-
读写分离:查询走从库
-
索引优化:覆盖索引+索引下推
-
业务妥协:禁止跳页(只允许上一页/下一页)
五、微服务场景
5. 如何设计可靠的分布式事务?
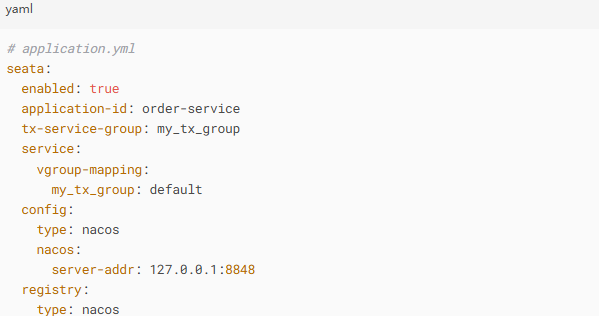
Seata实战配置:
选型对比:
| 方案 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 2PC | 强一致 | 差 | 低 | 金融支付 |
| TCC | 最终一致 | 中 | 高 | 积分、优惠券 |
| SAGA | 最终一致 | 好 | 中 | 长流程业务 |
| 本地消息表 | 最终一致 | 中 | 中 | 订单创建等异步场景 |
六、实际工程问题
6. 线上CPU飙高如何快速定位?
实战排查步骤:
-
快速定位问题容器/主机

2.分析线程栈

3.结合性能工具

-
常见原因
-
死循环(检查递归/while条件)
-
锁竞争(查看BLOCKED状态线程)
-
GC频繁(结合jstat -gcutil分析)
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









