






shell编程之正则表达式与文本处理器
正则表达式作为一种强大的字符串匹配工具,能够通过特定的字符组合来描述和匹配一系列符号符合特定规则的字符串,它不仅在脚本编程中扮演着重要角色,还是文本编辑器及多种程序设计语言中的核心功能之一
此外,文本处理器在 Shell 编程中同样占据着举足轻重的地位。grep、sed、awk 作为 Shell 编程中的“三剑客”,各自拥有独特的优势与广泛的应用场景。本章将详细介绍这些工具的使用方法,包括基本的文本搜索、复杂的文本替换、格式化的文本输出等,帮助轻松应对各种文本处理需求
正则表达式
正则表达式的定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为regex、regexp 或 RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说,是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母、数字、标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
正则表达式一般用于脚本编程与文本编辑器中。很多文本处理器与程序设计语言均支持正则表达式,例如 Linux 系统中常见的文本处理器(grep、egrep、sed、awk)以及应用比较广泛的python语言。正则表达式具备很强大的文本匹配机制,能够在文本海洋中快速高效的处理文本
正则表达式的用途
对于一般计算机用户来说,由于使用到正则表达式的机会不多,所以无法体会正则表达式的魅力,而对于系统管理员来说,正则表达式则是必备技能之一。
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的,有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败”“服务启动失败”等信息。这时可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将工作变得更加简单、方便
基础正则表达式
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用正则表达式最基础的部分。在 Linux 系统中常见的文件处理工具中 grep 与 sed支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式
基础正则表达式示例
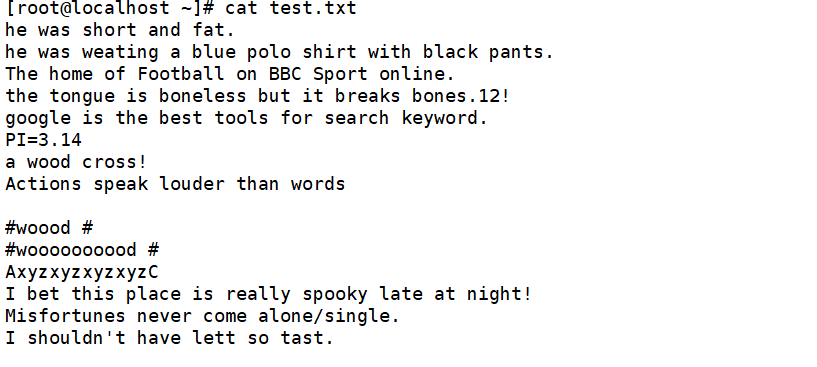
准备一个test.txt的文本,内容如下
(1)查找特定字符
查找特定字符非常简单,如执行如下命令即可从test.txt文件中查找出特定字符“the”所在位置。其中"-n"表示显示行号,“-i”表示不区分大小写。命令执行后,符合匹配标准的字符,字体颜色色会标为红色


若反向选择,如查找不包含“the”字符的行,则需要通过grep命令的“-v”选项来实现,并配合“-n”一起使用显示行号

(2)利用中括号“[ ]”来查找集合字符
想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh”与"rt"。此时执行以下命令即可同时查找到“shirt”与“short”这两个字符串,其中"[ ]“中无论有几个字符,都仅代表一个字符,也就是说”[io]“表示匹配"i"或者"o”

若要查找包含重复单个字符"oo"时,只需要执行以下命令

若查找"oo"前面不是"w"的字符串,只需要通过集合字符的反向选择"[^]"来实现该目的
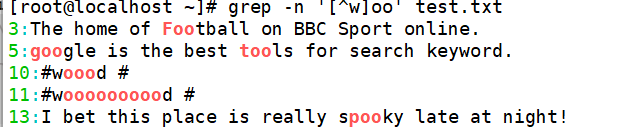
在上述命令的执行结果中发现“woood”与“wooooood”也符合匹配规则,二者均包含“w”。其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知,“#woood #”中加粗显示的是“ooo”,而“oo”前面的“o”是符合匹配规则的。同理“#woooooood #”也符合匹配规则。若不希望“00”前面存在小写字母,可以使用“grep -n’[^a-z]oo’test.txt”命令实现,其中 a-z”表示小写字母,大写字母则通过“A-Z”表示
查找包含数字的行可以通过"grep -n’[0-9]’ test.txt"来实现

(3)查找行首“^”与行尾字符“$”
基础正则表达式包含两个定位元字符:“^”(行首)与“$”(行尾)。在上面的示例中,查询“the”字符串时出现了很多包含“the”的行,如果想要查询以“the”字符串为行首的行,则可以通过“^元字符来实现

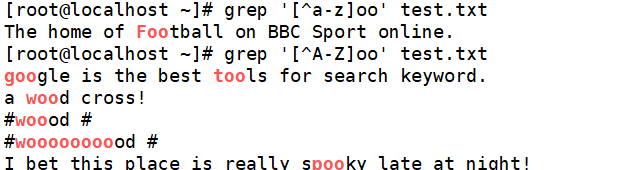
查询以小写字母开头的行可以通过“^[a-z]”规则来过滤,查询大写字母开头的行则使用“^[A-Z]”规则,若查询不以字母开头的行则使用"^[^a-zA-Z]"规则

“^”符号在元字符集合“[ ]”符号内外的作用是不一样的,在“[ ]”符号内表示反向选择,在“[ ]”符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符。例如,执行以下命令即可实现查询以小数点(.)结尾的行。因为小数点(.)在正则表达式中也是一个元字符
所以在这里需要用转义字符“\”将具有特殊意义的字符转化成普通字符

若查询空白行时,执行“grep ‘^$’ test.txt”
(4)查找任意一个字符“.”与重复字符"*"
在正则表达式中小数点(.)也是一个元字符,代表任意一个字符

在上述结果中,“wood”字符串“w…d”匹配规则。若想要査询 00、000、00000 等资料,则需要使用星号(*)元字符。但需要注意的是,“*”代表的是重复零个或多个前面的单字符。“o*”表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符,所以执行“grep-n’o*’ test.txt”命令会将文本中所有的内容都输出打印。如果是“oo*”,则第一个 。必须存在,第二个 o 则是零个或多个 o,所以凡是包含 0、00、000、000,等的资料都符合标准。同理,若査询包含至少两个 o 以上的字符串,则执行“grep -n ‘ooo*’ test.txt”命令即可
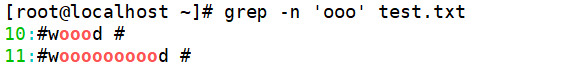
查询以w开头d结尾,中间包含至少一个o的字符串,执行以下命令

执行以下命令即可查询以w开头d结尾,中间的字符可有可无的字符串

执行以下命令即可查询任意数字所在行

(5)查找连续字符范围“{}”
在上面的示例中,使用了“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串该如何实现呢?例如,查找三到五个o的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{}”。因为“{}”在 she11 中具有特殊意义,所以在使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。“{}”字符的使用方法如下所示。
查询两个0的字符

查询以w开头d结尾,中间包含2~5个o的字符串

元字符总结
| 字符 | 说明 |
|---|---|
| | | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符 |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置 |
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| {n} | n 是一个非负整数。匹配确定的 n 次 |
| {n,} | n 是一个非负整数。至少匹配n 次 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符 |
| [a-z] | 字符范围。匹配指定范围内的任意字符 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置 |
| \B | 匹配非单词边界 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等 |
| \S | 匹配任何非空白字符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \w | 匹配字母、数字、下划线 |
| \W | 匹配非字母、数字、下划线 |
| \n | 标识一个八进制转义值或一个向后引用 |
扩展正则表达式
通常情况下会使用基础正则表达式就已经足够了,但有时为了简化整个指令,需要使用范围更广的扩展正则表达式。例如,使用基础正则表达式査询除文件中空白行与行首为“#”之外的行(通常用于查看生效的配置文件),执行“grep -v’^KaTeX parse error: Expected group after '^' at position 20: …t.txt| grep -v'^̲#’”即可实现。这里需要使用管…|^#’test.txt”,其中,单引号内的管道符号表示或者(or)。
此外,grep 命令仅支持基础正则表达式,如果使用扩展正则表达式,需要使用 egrep 或 awk 命令。awk 命令在后面的小节进行讲解,这里我们直接使用 egrep 命令。egrep 命令与 grep 命令的用法基本相似。egrep 命令是一个搜索文件获得模式,使用该命令可以搜索文件中的任意字符串和符号,也可以搜索一个或多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字或一个句子。
与基础正则表达式类型相同,扩展正则表达式也包含多个元字符,常见的扩展正则表达式的元字符主要包括以下几个,如下表所示。
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
|---|---|
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 |
| | | 替换,“或"操作字符具有高于替换运算符的优先级,得"mfood"匹配"m"或"food”。若要匹配"mood"或"food",请使用括号创建子表式,从而产生"(m |
| () | 查找“组”字符串示例:“egrep -n "t(ale)st test.txt”。“tast"与"test"因为这两个单词的”!"与"st"是重复的,所以将"a"与"e列于“()”符号当中,并以“"分隔,即可查询"tast"或者"test"字符串 |
| ()+ | 查找“组”字符串示例:“egrep -n "t(ale)st test.txt”。“tast"与"test"因为这两个单词的”!"与"st"是重复的,所以将"a"与"e列于“()”符号当中,并以“"分隔,即可查询"tast"或者"test"字符串作用:辨别多个重复的组示例:“egrep -n’A(xyz)+C’ test.txt”。该命令是査询开头的"A"结尾是"℃”,中间有一个以上的"xyz"字符串的意思 |
文本处理器
1.sed 工具
sed(stream EDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。sed 也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于 she11 脚本中,用以完成各种自动化处理任务。
sed 的工作流程主要包括读取、执行和显示三个过程。
读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)
执行:默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed命令将会在所有的行上依次执行。
显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空
在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完
注意:默认情况下所有的 sed 命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出
sed[选项]'操作'参数
sed「选项]-f scriptfile 参数
常见的 sed 命令选项主要包含以下几种
-e或–expression=:表示用指定命令或者脚本来处理输入的文本文件。
-f或–file=: 表示用指定的脚本文件来处理输入的文本文件。
-h 或–help:显示帮助。
-n,–quiet 或 silent:表示仅显示处理后的结果。
-i:直接编辑文本文件。
“操作”用于指定对文件操作的动作行为,也就是 sed 的命令。通常情况下是采用的“[n1[,n2]]”操作参数的格式。n1、n2 是可选的,代表选择进行操作的行数,如操作需要在 5~20 行之间进行,则表示为“5,20 动作行为”。常见的操作包括以下几种。
| 操作 | 作用 |
|---|---|
| a | 增加,在当前行下面增加一行指定内容 |
| c | 替换,将选定行替换为指定内容 |
| d | 删除,删除选定的行 |
| i | 插入,在选定行上面插入一行指定内容 |
| p | 打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCII 码输出。其通常与“-n”选项一起使用 |
| s | 替换,替换指定字符 |
| y | 字符转换 |
用法示例
(1)输出符合条件的文本(p表示正常输出)
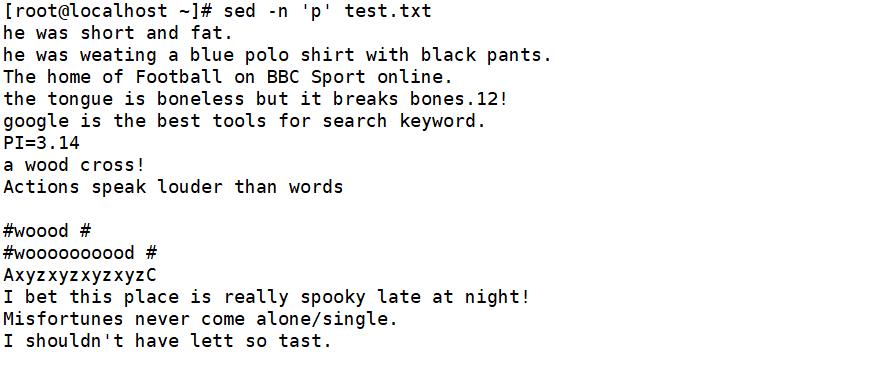
输出第三行

输出所有偶数行,n表示读入下一行资料
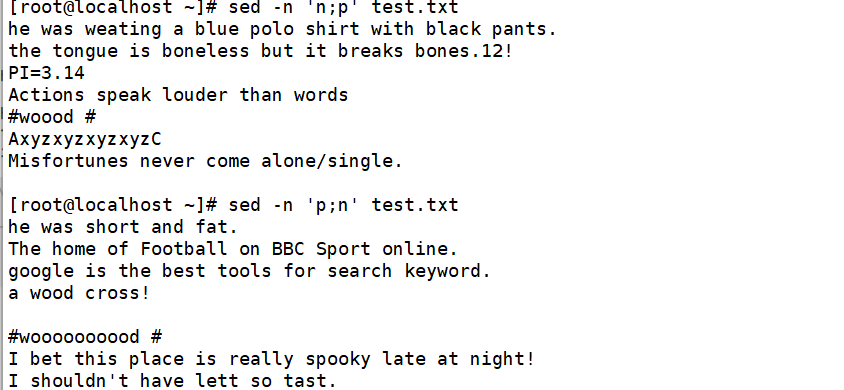
输出1~5行之间的奇数行

输出第10行到结尾的奇数行

在执行“sed -n’18,${n;p}’test.txt”命令时,读取的第 1 行是文件的第 18 行,读取的第 2行是文件的第 11 行,依此类推,所以输出的偶数行是文件的第 11 行、13 行直至文件结尾,其中包括空行
以上是 sed 命令的基本用法,sed 命令结合正则表达式时,格式略有不同,正则表达式以“/”包围。
例如,以下操作是 sed 命令与正则表达式结合使用的示例
输出包含the的行

输出从第四行至第一个包含the的行
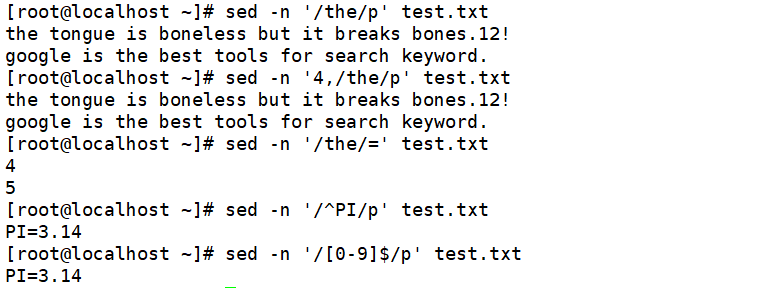
(2)删除符合条件的文本(d)
因为后面的示例还需要使用测试文件 test.txt,所以在执行删除操作之前需要先将测试文件备份
以下示例分别演示了 sed 命令的几种常用删除用法。
下面命令中 nl 命令用于计算文件的行数,结合该命令可以更加直观地査看到命令执行的结果。
删除第三行
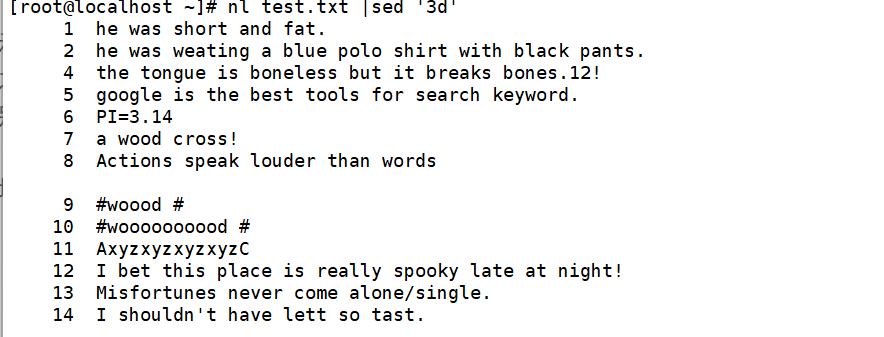
删除第3~5行

删除以小写字母开头的行

删除以.结尾的行
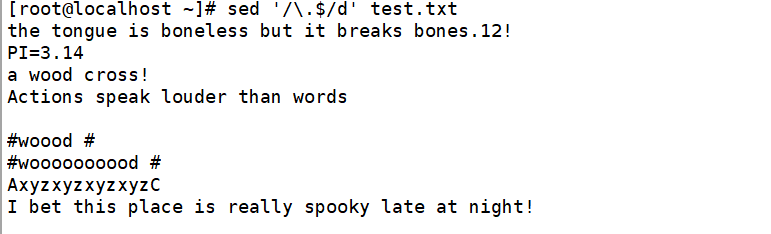
删除所有空行

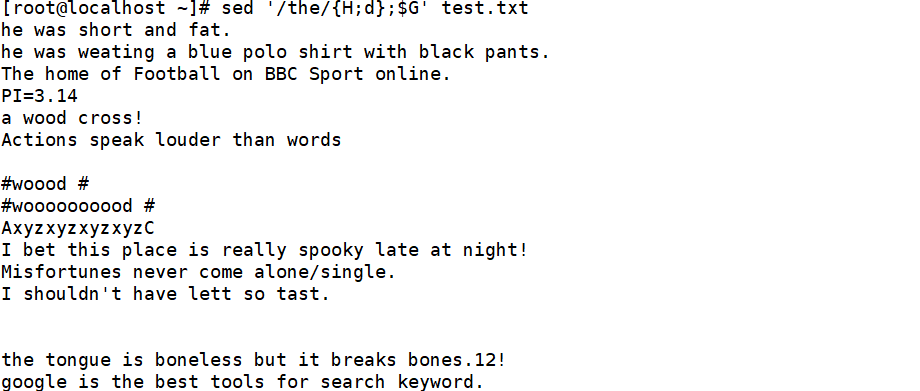
注意:若是删除重复的空行,即连续的空行只保留一个,执行“sed -e’/^KaTeX parse error: Expected group after '^' at position 6: /{n;/^̲/d}'test.txt”命令即可实现。其效果与“cat-s test.txt”相同,n 表示读下一行数据。
(3)替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y(字符转换)命令选项,常见的用法如下所示。
把每行中的第一个the替换成THE
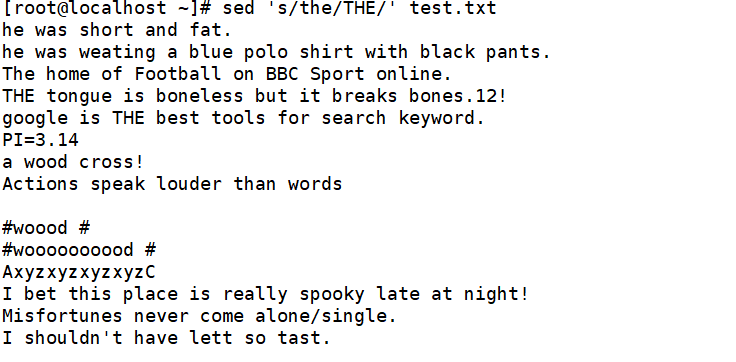
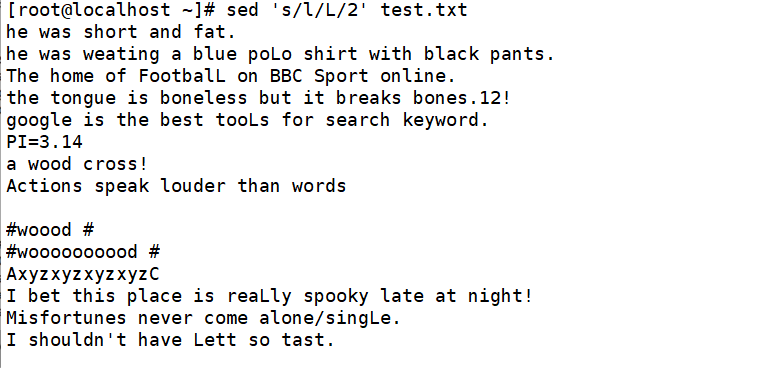
将每行中的第二个l替换成L
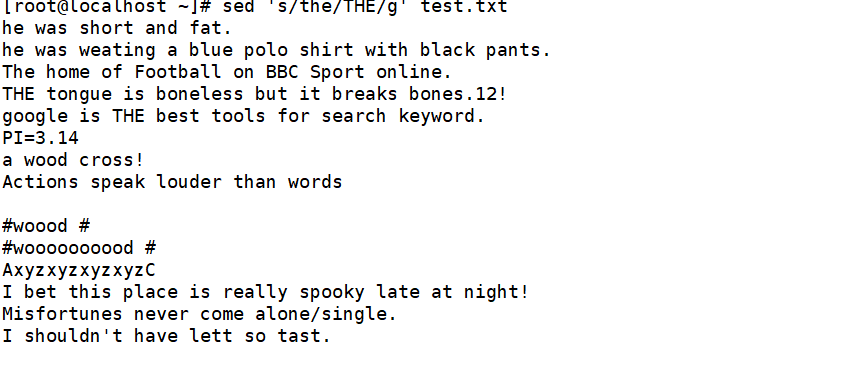
将文件中所有的the替换成THE
将文件中的所有o删除

在每行行首插入#号
在每行行尾插入字符EOF

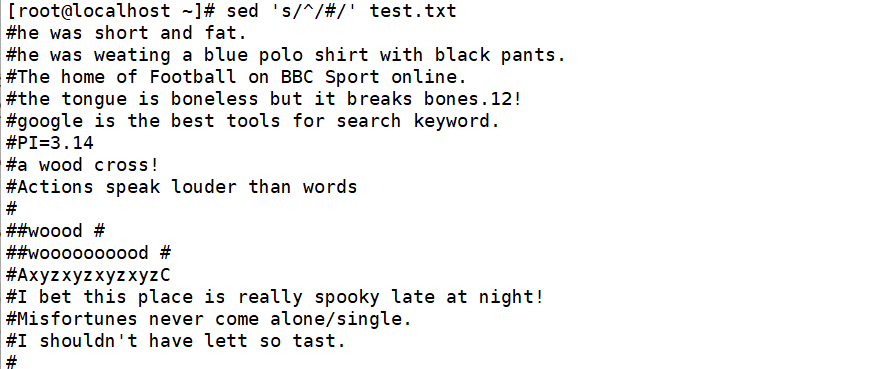
将包含the的所有内容中的o都替换成0
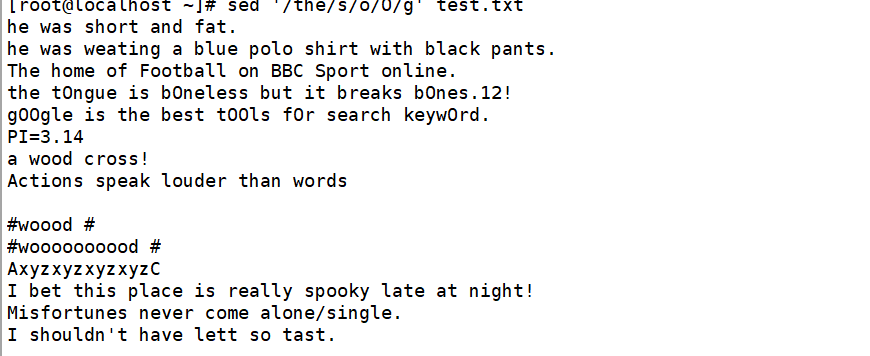
(4)迁移符合条件的文本
在使用 sed 命令迁移符合条件的文本时,常用到以下参数:
H:复制到剪贴板;
g、G:将剪贴板中的数据覆盖/追加至指定行;
w:保存为文件;
r:读取指定文件;
a:追加指定内容
具体操作方法如下所示。
将包含the的行迁移至末尾,{;}用于多个操作
将第1~15行转移至第17行后

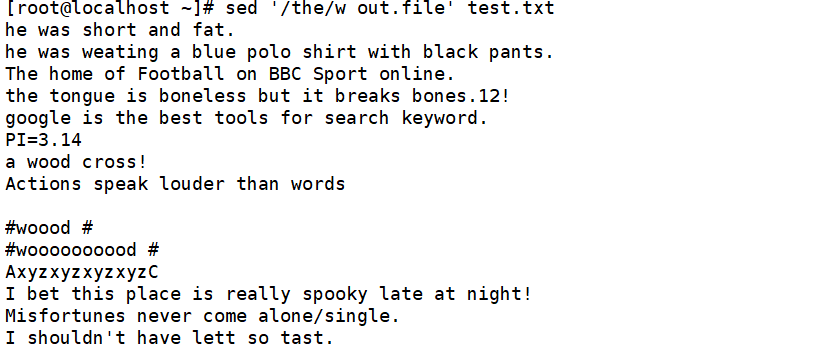
将包含the的行另存为文件out.file
将文件/etc/hostname的内容添加到包含the的每行后面
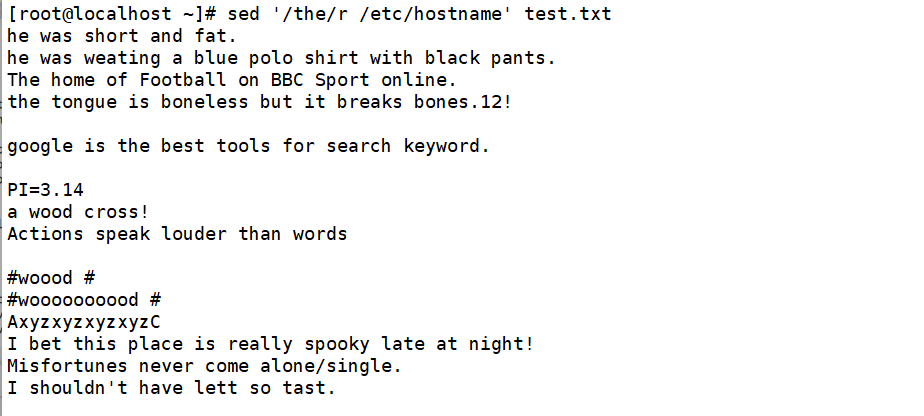
在第三行后插入一个新行,内容为New

在包含the的每行后插入一个新行,内容为New
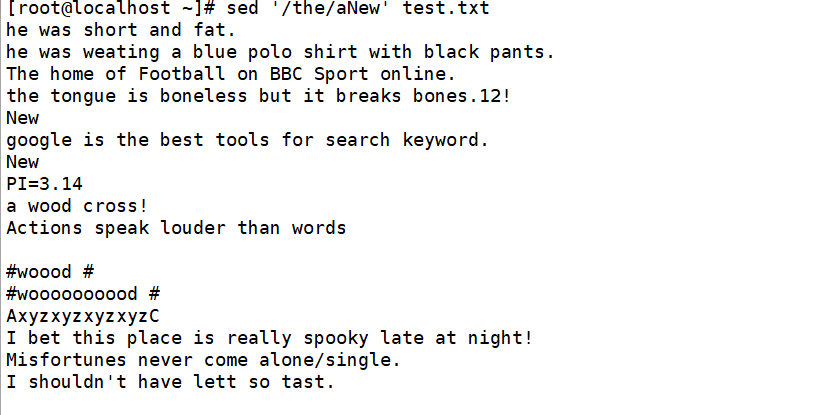
在第三行后插入多行内容,中间的\n表示换行

awk工具
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互的情况下实现相当复杂的文本操作,被广泛应用于 shel1 脚本,完成各种自动化配置任务。
通常情况下 awk 所使用的命令格式如下所示,其中,单引号加上大括号“{}”用于设置对数据进行的处理动作。awk 可以直接处理目标文件,也可以通过“-f”读取脚本对目标文件进行处理
awk 选项'模式或条件{编辑指令}'文件 1 文件 2.
过滤并输出文件中符合条件的内容
awk -f 脚本文件 文件 1 文件 2 …
从脚本中调用编辑指令,过滤并输出内容
前面提到 sed 命令常用于一整行的处理,而 awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。在使用 awk 命令的过程中,可以使用逻辑操作符“&&”表示“与”、“|”表示“或”、“!”表示“非”还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
在 Linux 系统中/etc/passwd 是一个非常典型的格式化文件,各字段间使用“:”作为分隔符隔开,Linux 系统中的大部分日志文件也是格式化文件,从这些文件中提取相关信息是运维的日常工作内容之一。若需要査找出/etc/passwd 的用户名、用户 ID、组 ID 等列,执行以下 awk 命令即可

awk 从输入文件或者标准输入中读入信息,与 sed 一样,信息的读入也是逐行读取的。不同的是 awk将文本文件中的一行视为一个记录,而将一行中的某一部分(列)作为记录中的一个字段(域)。为了操作这些不同的字段,awk 借用 shell中类似于位置变量的方法,用$1、$2、$3…顺序地表示行(记录)中的不同字段。另外 awk 用$0 表示整个行(记录)。
不同的字段之间是通过指定的字符分隔。awk 默认的分隔符是空格。awk允许在命令行中用“-F 分隔符”的形式来指定分隔符。在上述示例中,awk 命令对/etc/passwd 文件的处理过程如下图所示。
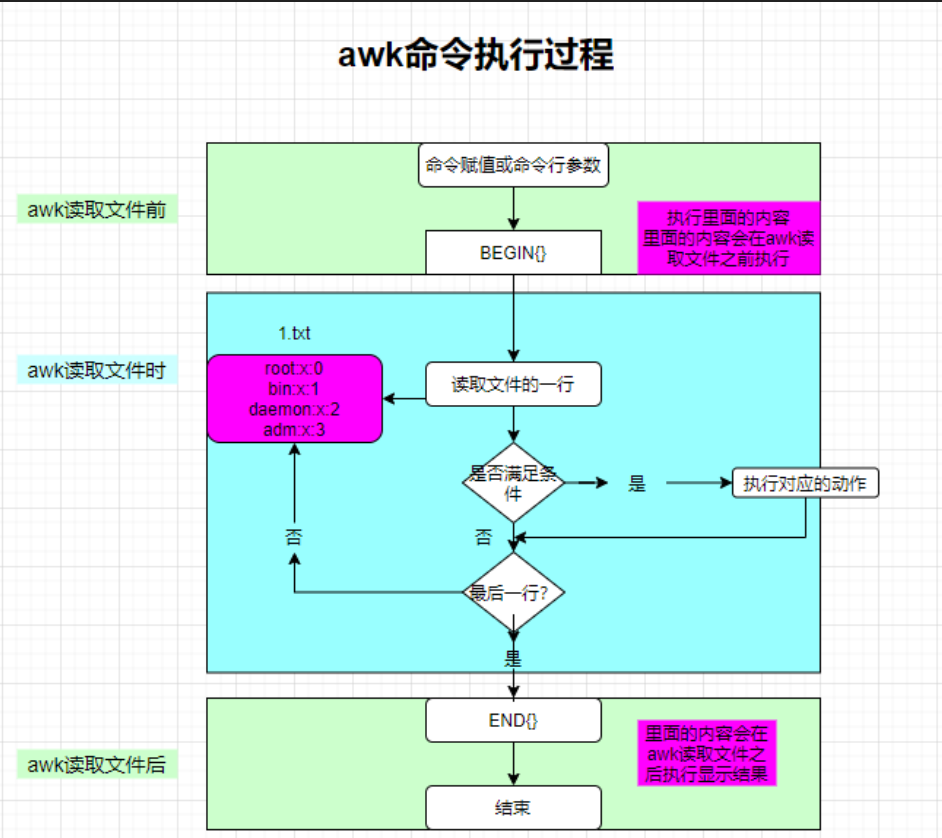
awk 包含几个特殊的内建变量,如下所示:
| FS | 指定每行文本的字段分隔符,默认为空格或制表位 |
|---|---|
| NF | 当前处理的行的字段个数 |
| NR | 当前处理的行的行号(序数) |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME | 被处理的文件名 |
| RS | 数据记录分隔,默认为\n,即每行为一条记录 |
用法示例
(1)按行输出文本
输出所有内容
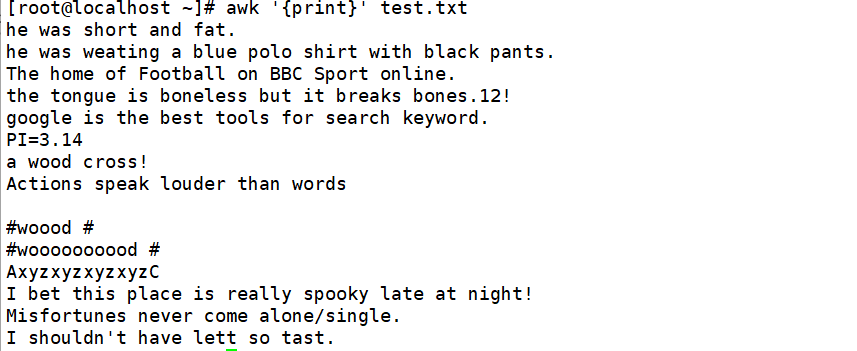
输出所有内容,等同于cat test.txt
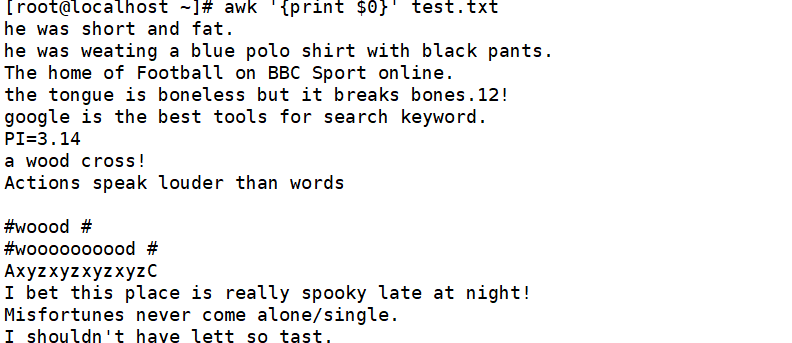
输出第1~3行内容
输出第1~3行内容

输出1,3行内容

输出所有奇数行的内容

输出所有偶数行的内容

输出所有root开头的行

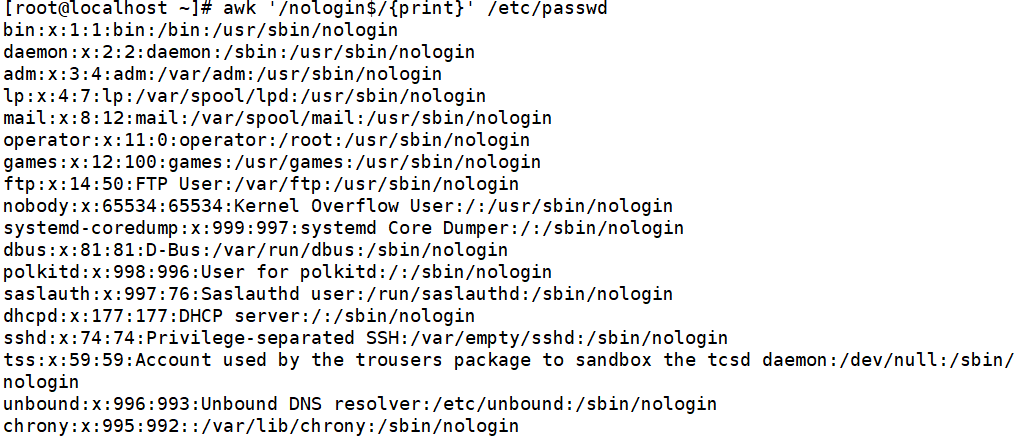
输出所有nologin结尾的行
统计以/bin/bash结尾的行
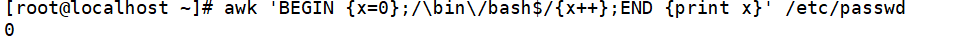
(2)按字段输出文本
输出每行中(以空格或制表位分割)的第三个字段
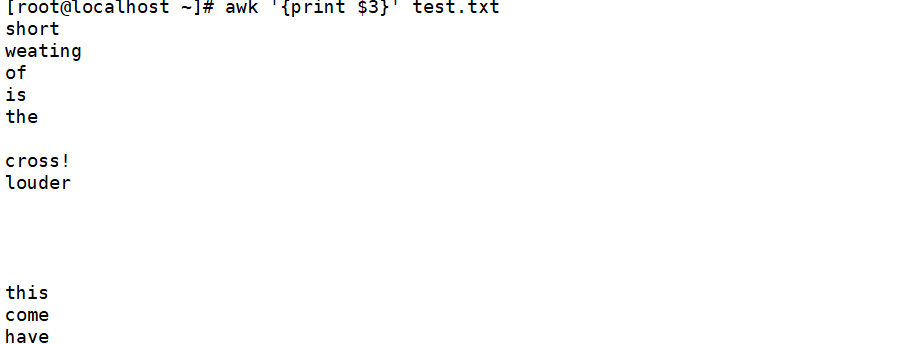
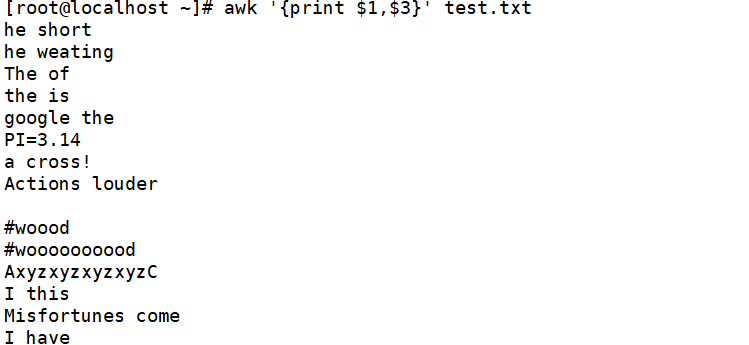
输出每行中的第1,3个字符
输出包含8个字段且第1个字段中包含nfs的行的第1,2个字段

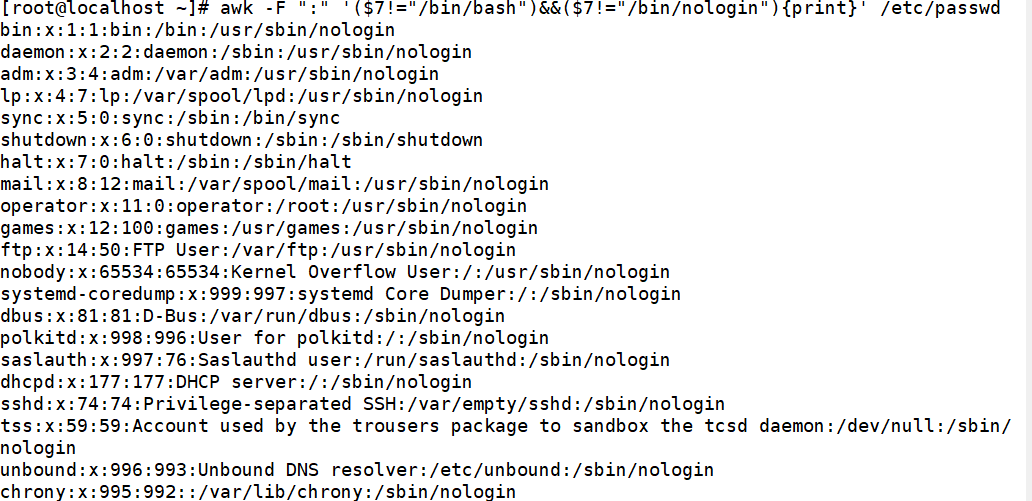
输出第7个字段既不为/bin/bash也不为/sbin/bash的所有行
(3)通过管道,双引号调用shell命令
调用wc-l命令统计使用bash的用户个数
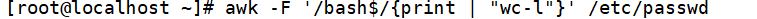
调用w命令,并用来统计在线用户数

调用hostname,并输出当前的主机名


















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









