







省赛初赛(大数据)
本人系第九届华为ICT大赛实践赛云赛道选手,曾包揽省赛、中国总决赛及全球总决赛三项一等奖,并持有HCIE-Cloud Service认证。现通过本平台分享备赛经验与参赛心得,供各位同学参考。文中所述内容若有疏漏之处,恳请各位不吝指正,在此先行致谢!(建议首先阅读专栏首篇文章——【备赛指南】华为ICT大赛 实践赛 云赛道01,之后再逐步阅读后续内容)
五、HBase
1. HBase的定义
是非关系型分布式数据库,也是Google的论文“BigTable”的开源实现
HBase是分布式存储系统,利用HDFS作为其文件存储系统,提供分布式数据系统,而ZooKeeper是协同服务
HBase为存入HDFS的数据进行优化和快速查询
HBase分布式存储最基本单位是Region
2. HBase与关系型数据库对比
(1) 数据索引:只有一个行键
(2) 数据维护:更新操作不会删除旧的版本
(3) 可伸缩性:更轻易增加或减少硬件实现水平扩展,可以不暂停服务
3. HBase的数据模型(由表构成,列存储)
(1) 行键Row Key:每行每个数据都要有行键(key)
相似的数据可以放在同一个行键,扫描更快
访问HBase表中的行
①通过单个行键访问
②通过一个行键的区间来访问
③全表扫描
(2) 列族
(3) 列:列从左到右排序是字典序a -> z
(4) Cell:单元格,最新存储的数据在最上面
(5) 时间戳:行键相同的情况下,时间戳越新版本越新
-
t6 contents : html✔ t5 contents : html
-
t9 anchor : aa.com✔ t8 anchor : bb.com✔ 列族 : 列
(6) HBase的数据类型是字节数组(byte[ ]),只有一种
4. HBase的体系架构
(1) Client:通过ZooKeeper获得Region位置,直接从HRegionServer读取数据。从来不和HMaster通信,HMaster只负责集群内
(2) ZooKeeper:会选举一个active的HMaster和多个standby的HMaster,避免单点失效
(3) HMaster:负责协调,只有一个。负责表(增、删、改、查)和Region(Region分裂或合并,对发生故障失效的HRegionServer上的Region进行迁移)
(4) HRegionServer:负责存,有多个。负责存储和维护分配给自己的Region(列族)
①HLog:预写日志。当某个HRegionServer发生故障,ZooKeeper会通知HMaster,HMaster有优先处理HRegionServer遗留的HLog文件(在HDFS上,默认有冗余)
-
共用日志优点:提高对表的写操作性能
-
共用日志缺点:恢复时需要拆分日志
②HRegion(Store):工作节点。Store的工作原理,当每次刷写都会生成一个新的StoreFile,数量多时会合并。当个StoreFile过大时又会分裂
-
③MemStore:当数据刚存入或刚被读取时会被当做热点数据存储在“内存”,为了高效
-
OpenScanner(读取过程会创建):读取内存数据MemStore为MemStoreScanner
-
-
④StoreFile:数据持久化到磁盘
-
⑤HFile:通过DFS Client,对接HDFS的DataNode,实际HBase的数据存储在HDFS里
-
Compaction机制:减少同一个Region中同一个ColumnFamily下的HFile数目,以提高性能
-
Minor Compaction:小范围的HFile合并,触发次数更高
-
Major Compaction:全局的HFile文件,触发次数低并且会把旧的和已被删除的数据进行彻底清除
-
-
OpenScanner(读取过程会创建):读取磁盘数据HFile为StoreFileScanner
-
-
Region分裂或合并很快,是逻辑的
HBase有个自己维护的meta表,有Mate Region和User Region
5. HBase的读写
(1) 写:HLog -> MemStore(内存) -> StoreFile(磁盘)
(2) 读:MemStore -> StoreFile,在磁盘找到后也会加载至内存中
6. BloomFilter:用于查询数据是否存在。相当于在大表里查询某一格是否存在
(1) 若该格不存在则一定为空
(2) 若该格存在可能有误差,存的是别的数据,概率很小
7. Hindex二级索引:华为开发,支持列索引(一般HBase都是行)
六、Hive
1. Hive的定义
(1) 是分布式数据仓库,封装了MapReduce,使得可以用命令调用它。有助于使用SQL读取、写入和管理HDFS数据
目的是解决不会写代码和不熟悉Java,提供了SQL(最好理解的编程语言)语法平替
Hive SQL
①DDL数据定义语言:建表、修改表、删表、分区、数据类型
②DML数据管理语言:数据导入、数据导出
③DQL数据查询语言:简单查询、复杂查询
(2) 支持Tez、Spark计算引擎
(3) 灵活方便的ETL(提取、转换、加载数据到目标数据仓库)
(4) 数据存储在HDFS
(5) Hive是离线数仓,不支持实时
2. Hive和传统数据库的区别
(1) 传统数据库:容量存在上限,当容量较大时速度会很慢,但索引高效
(2) Hive:因为存储在HDFS上,容量无上线,但索引效率较低(也存在HDFS上),还需要咨询开发应用模型
3. Hive的优点
(1) 高可靠、高容错
-
HiveServer(Hive工作节点)采用集群模式
-
双MetaStore(存储元数据)
-
超时重试机制
(2) 类SQL:类似SQL语法、内置大量函数
(3) 可扩展:自定义存储格式、自定义函数
(4) 多接口:Beeling、JDBC、Thrift、ODBC
4. Hive的架构
(1) 接口层
-
JDBC、ODBC
(2) 访问层
-
Web Interface(Web方式)
-
Thrift Server(第三方方式)
(3) Driver层
-
Compiler编译
-
Optimizer自动优化:从逻辑执行→物理执行→Run,中间会进行优化
-
Executor执行
-
MetaStore(元数据管理)
(4) 执行层
-
Tez、MapReduce、Spark计算引擎
5. Hive的运行流程
(1) HQL语句:Client提交HQL命令
(2) Hive
(3) Tez(default):执行查询
(4) Yarn:进行资源调度执行计算
(5) HDFS:根据表类型更新HDFS或Hive仓库数据,通过JDBC返回查询结果
6. Hive的数据存储模型(存储在HDFS上)
(1) 数据库:Database,在HDFS上是目录
(2) 表:目录中的目录
①托管表MANAGED_TABLE:元数据和数据会被一起删除
-
如果数据只存储一段时间建议托管表,默认创建托管表
②外部表EXTERNAL_TABLE:只删除元数据
-
如果数据要永久保存建议外部表
(3) 分区:表目录中的目录。数据表可以按照某个字段的值划分分区
-
每个分区是一个目录
-
分区数量不固定
-
分区下可再有分区或桶
(4) 桶:根据字段拆分文件成桶,也可以不拆分直接存文件。数据可以根据桶的方式将不同数据放入不同桶中
-
每个桶是个文件
-
建表时指定桶个数,桶内可排序
-
数据按照某个字段的Hash后放入某个桶中
(5) 倾斜数据和正常数据:都是正常的
7. Hive支持的函数
UDF:输入一条返回一条,都是用户自定义函数,内置函数也算
七、ClickHouse
1. ClickHouse的定义
ClickHouse是OLAP(联机分析处理)的列式数据库,查询速度快特别是基于大宽表
支持SQL查询非SQL结构数据,主要计算引擎是MergeTree
俄罗斯yandex公司开发,独立于Hadoop大数据体系
DBMS:数据库+管理系统
2. ClickHouse的应用场景
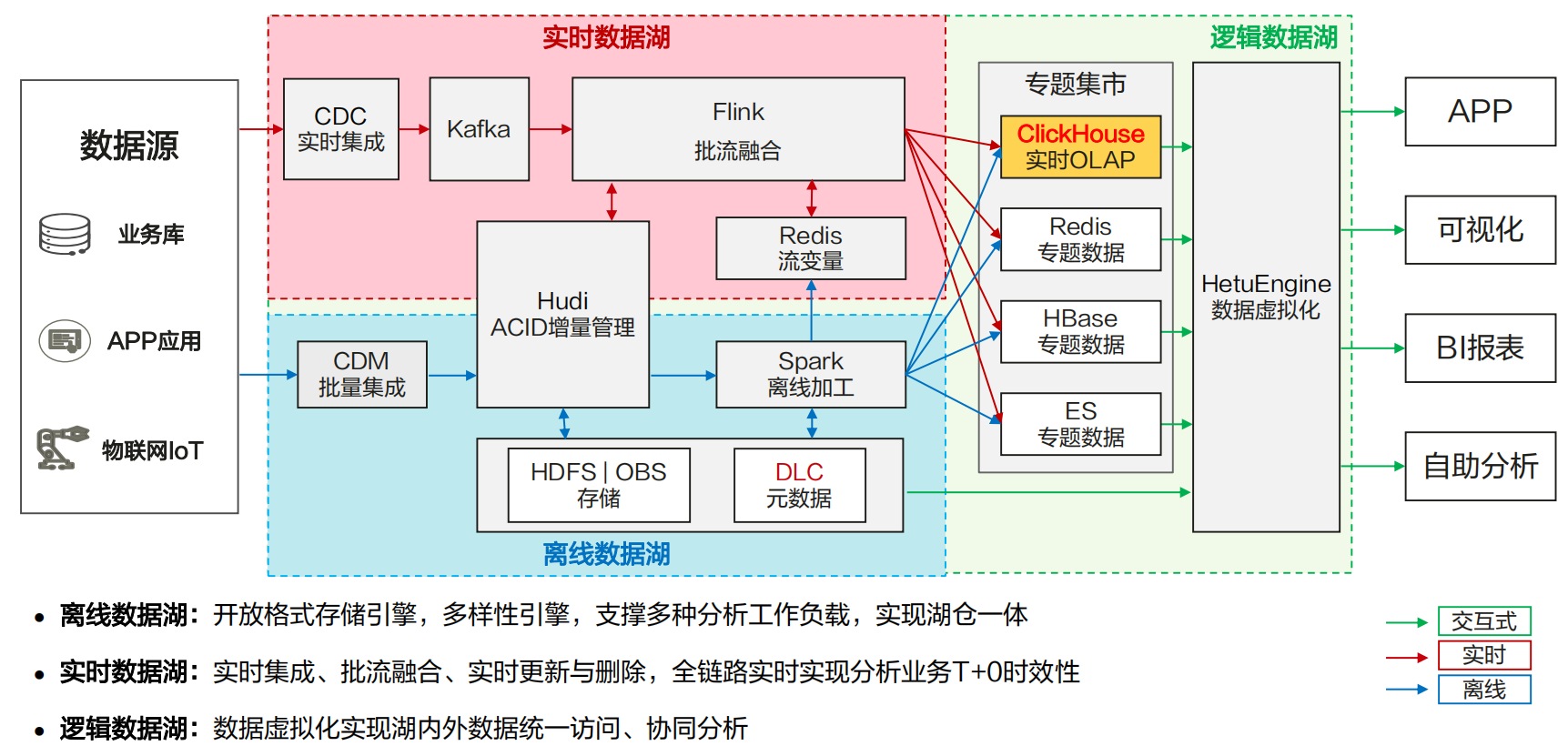
(1) CDC:增量数据采集
(2) Kafka:消息队列,错峰上传数据,先将数据暂存,还能对接多个用户
(3) Flink:实时流式,来一条处理一条,而不是积攒再处理
(4) Spark:离线加工
(5) Redis:流处理批处理都可以,是非关系型数据库
(6) DLC:元数据管理
(7) ES:谷歌百度底层查询服务
3. ClickHouse的架构
(1)TCP:ClickHouse Client(CLI)客户端,HTTPS:JDBC Driver(BalancedClickHoudeDataSource)
(2) ClickHouseBalancer负载
(3) 多个ClickHouseServer工作节点
(4) 多个ZNodes冗余(底层是ZooKeeper)
4. ClickHouse的表索引
决定
(1) 数据存储和读取的位置
(2) 支持哪些查询方式
(3) 是否并发式访问数据
(4) 能不能使用索引
(5) 是否可以执行多线程请求
(6) 数据复制使用的参数
常见的表索引
(1) TinyLog:小日志文件
(2) Memory:内存
(3) MergeTree:树型结构
MergeTree合并树:被设计用来将大量数据插入一张表中,数据以数据块的形式被快速写入,数据块会在后台进行异步合并,确保高效的插入和查询性能
①主键排序、稀疏索引
②支持数据分区
③支持副本机制(ReplacingMergeTree系列)
④支持数据采样
⑤并发数据访问
⑥支持TTL,Time to Live,数据的存活时间,到期自动删除
⑦支持二级索引(Data Skipping Index跳级索引)偏移量
(4) ReplacingMergeTree:复制聚合树,支持副本机制
(5) SummingMergeTree:摘要聚合树
5. ClickHouse的副本机制
数据分片和副本的区别
(1) 分片:数据量很大时进行切分存储,为了水平切分,数据不同
(2) 副本:复制了一份,数据完全相同
都支持并发访问:用户A同时访问分片1和分片2。用户A访问副本1,用户B访问副本2
ClickHouse副本机制的定义
用以在不同数据中心进行同步,用来建设多数据中心、异地多活的集群架构。副本机制是实现高可用、负载均衡、迁移/升级的基础
ClickHouse副本的特定
(1) 副本配置可以个性化
(2) 依赖ZooKeeper分布式协同能力,实现多个副本之间数据同步
(3) 写入数据有原子性和唯一性
-
原子性:Block数据块数据全部写入成功或失败
-
唯一性:避免重复写入(Hash信息摘要)
6. ClickHouse的分布式查询
ClickHouse通过分片和分布式表机制提供了线性扩展的能力
(1) 分片机制:将一张表的数据水平切分到多个节点,不同节点之间数据不重复
(2) 分布式表:查询分片数据,通过分布式表进行查询(shard分片、Replicate副本)
7. ClichHouse的可视化运维(在华为云上)
(1) 在线扩容和数据迁移
(2) 滚动升级和滚动重启(不用全部节点暂停,停一个节点)
(3) 自动集群拓扑及ZooKeeper防止过载
(4) CSV:用“ ,”分隔数据,可以直接支持表格打开
八、MapReduce
1. MapReduce的定义
基于Google发布的MapReduce论文开发,基于分而治之的思想
-
Map:就是分而治
-
Reduce:把处理完的结果进行统计合并
用于大规模数据集的并发计算和离线计算(高度抽象的编程思想)
2. MapReduce的过程
MapReudce工作流程
①输入:分片1、分片2、分片3(HDFS的文件block,运行在不同机器节点,而Map就在不同机器里)
②Map任务:Map( )、Map( )、Map( )
③shuffle:Map shuffle + Reduce shuffle
④Reduce任务:reduce( )、reduce()、reduce( )
⑤输出:按逻辑输出对应数值
(1) Map阶段:数据所在计算,在一堆杂乱无章的数据提取key和value,也就是特征【提取】
Job提交前,先将待处理文件进行分片,一个数据块(Block)作为一个分片。Map阶段会将Map( )后数据放入“环形内存缓冲区”当到80%发生溢写Spill,将缓冲区数据写入本地磁盘
map( )把每个分片的词拆分,combine统计每个分片每个词的总数,Merge统计全部分片每个词的总数,Reduce主动找map拉取数据
①HDFS
②Split、map( )、Document
③环形内存缓冲区
④Map Phase
partition(分区)
sort(排序)
combine(合并 可选 当计算逻辑可以优化时可以选择合并,减少网络间传输)
Merge(归并)
⑤本地磁盘
(2) shuffle:一定规则放入
从“环形内存缓冲区”到“Reduce”之间都是Shuffle
(3) Reduce阶段:数据是以key后跟着的value来组织的,这些value是有相关性【合并】
当数据量很少时,不需要溢写到磁盘,直接缓存中归并输出给Reduce
①Map Phase
②MOF文件:Map( )完就是MOF文件,对MOF的排序和合并处理交给Reduce【Map Tesk】
③本地磁盘
④Reduce Phase
copy复制
缓存,Merge(归并)
磁盘,Reduce(归约)
HDFS

















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









