







省复赛(大数据)
本人系第九届华为ICT大赛实践赛云赛道选手,曾包揽省赛、中国总决赛及全球总决赛三项一等奖,并持有HCIE-Cloud Service认证。现通过本平台分享备赛经验与参赛心得,供各位同学参考。文中所述内容若有疏漏之处,恳请各位不吝指正,在此先行致谢!(建议首先阅读专栏首篇文章——【备赛指南】华为ICT大赛 实践赛 云赛道01,之后再逐步阅读后续内容)
三、大模型实时流处理场景化解决方案
大数据实时流处理概述
(1) 什么是数据实时处理?
数据从生成 -> 实时采集 -> 实时缓存存储 -> 实时计算 -> 实时落地 -> 实时展示 -> 实时分析
· 这一个流程线下来,处理数据的速度在秒级甚至毫秒级
数据实时采集ETL和脚本 -> 缓存队列Kafka、MQ -> 实时计算Flink、Spark -> 实时落地 数据库 -> 实时展示 数据可视化 -> 实时分析 BI报表
(2) 实时处理解决方案与其它解决方案的关系
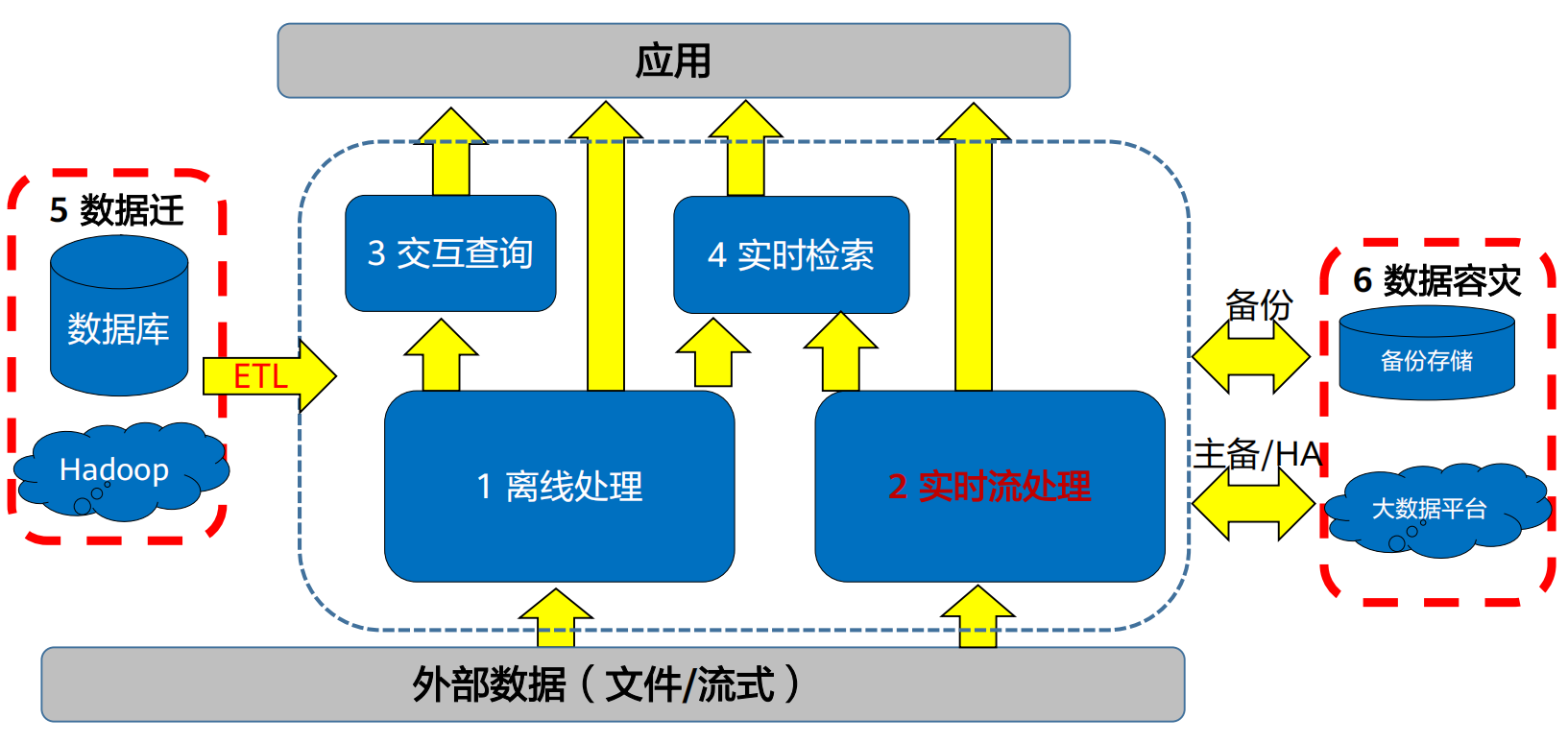
(3) 实时数据处理系统的诉求
①处理速度快:端到端处理需要达到秒级。如风控项目要求单条数据处理时间达到秒级,单节点TPS大于2000
②吞吐量高:需在短时内接收并处理大量数据记录,吞吐量需要达到数十兆/秒/节点
③可靠性高:网络、软件等故障发生时,需保证每条数据不丢失,数据处理不遗漏、不重复
④水平扩展:当系统处理能力出现瓶颈后,可通过节点的水平扩展提升处理性能
⑤多数据源支持:支持网络流、文件、数据库表、IOT等格式的数据源。对于文件数据源,可以处理增量数据的加载
⑥数据权限和资源隔离:消息处理、流处理需要有数据权限控制,不同的作业、用户可以访问、处理不同的消息和数据。多种流处理应用之间要进行资源控制和隔离,防止发生资源争抢
⑦第三方工具对接:支持与第三方规则引擎、决策系统、实时推荐系统等对接
(4) 华为实时流处理技术架构
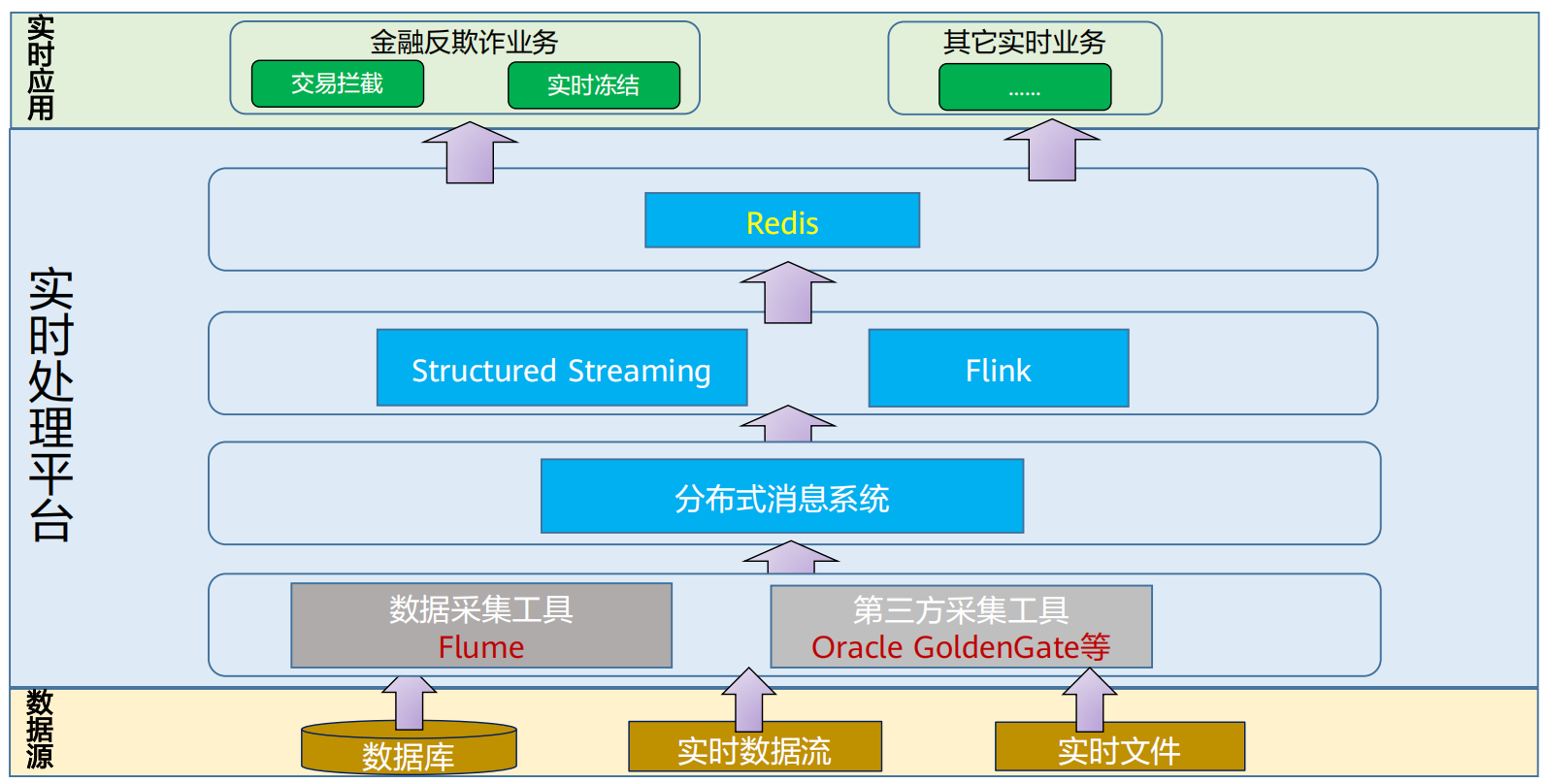
实时处理技术框架介绍
(1) Flume
1. Flume的概念
Flume是一个分布式、高可靠和高可用的海量日志采集、聚合与传输的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
2. Flume的功能
①提供从固定目录下采集日志信息到目的地(HDFS,HBase,Kafka)能力
②提供实时采集日志信息(taildir)到目的地的能力
③Flume支持级联(多个Flume对接起来),合并数据的能力
④Flume支持按照用户定制采集数据的能力
3. Flume的基本概念
· 基本概念-Event
①Event是Flume数据传输的基本单元
②Event由Header和Body两部分组成
(1)Header:用来存放该event下的一些属性信息,通常使用<Key,Value>的结构
(2)Body:用来存放数据,数据结构为字节数组(Byte Array)
· 基本概念-Source
①Source负责接收events或通过特殊机制产生events,并将events批量放到一个或多个Channels
(1)驱动型source:是外部主动发送数据给Flume,驱动Flume接受数据
(2)轮询source:是Flume周期性主动去获取数据
②Source必须至少和一个channel关联
③Source的类型
(1)exec source:执行某个命令或者脚本,并将其执行结果的输出作为数据源
(2)avro source:提供一个基于avro协议的server,bind到某个端口上,等待avro协议客户端发过来的数据
(3)thrift source:同avro,不过传输协议为thrift
(4)http source:支持http的post发送数据
(5)syslog source:采集系统syslog
(6)spooling directory source:采集本地静态文件
(7)jms source:从消息队列获取数据
(8)Kafka source:从Kafka中获取数据
· 基本概念-Channel
①Channel位于Source和Sink之间,Channel的作用类似队列,用于临时缓存进来的events,当Sink成功地将events发送到下一跳的Channel或最终目的,events从Channel移除
②不同的Channel提供的持久化水平也是不一样的
(1)Memory Channel:不会持久化
· 消息存放在内存中,提供高吞吐,但不提供可靠性;因此在程序关闭或者机器宕机时可能丢失数据
(2)File Channel:基于WAL(预写式日志Write-Ahead Log)实现
· 对数据持久化;但是配置较为麻烦,需要配置数据目录和checkpoint目录;不同的File Channel均需要配置一个checkpoint目录
(3)JDBC Channel:基于嵌入式Database实现
· 内置的derby数据库,对event进行了持久化,提供高可靠性;可以取代同样具有持久特性的File Channel
③Channels支持事务,提供较弱的顺序保证,可以连接任何数量的Source和Sink
· 基本概念-Sink
①Sink负责将events传输到下一跳或最终目的,成功完成后将events从Channel移除
②必须作用于一个确切的Channel
③Sink的类型
(1)hdfs sink:将数据写到hdfs上
(2)avro sink:使用avro协议将数据发送给另下一跳的Flume
(3)thift sink:同avro,不过传输协议为thrift
(4)file roll sink:将数据保存在本地文件系统中
(5)hbase sink:将数据写到HBase中
(6)Kafka sink:将数据写入到Kafka中
(7)MorphlineSolr sink:将数据写入到Solr中
4. Flume的架构
Flume基础架构:Flume可以单节点直接采集数据,主要应用于集群内数据
Flume多agent架构:Flume可以将多个节点连接起来,将最初的数据源经过收集,存储到最终的存储系统中。主要应用于集群外的数据导入到集群内
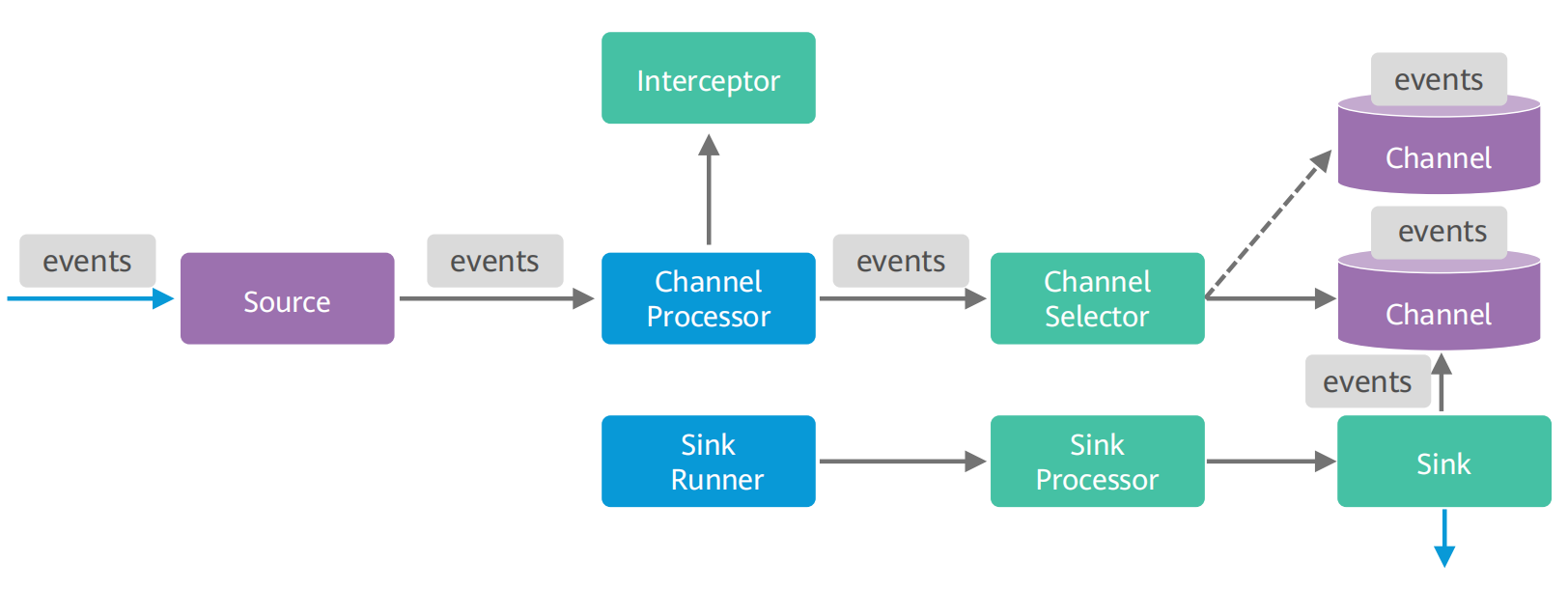
5. Flume支持多级级联和多路复制
Flume支持将多个Flume级联起来,同时级联节点内部支持数据复制
6. Flume的高级组件
①高级组件-Source interceptors
Flume可以在source阶段修改/删除event,这是通过拦截器Interceptors来实现的。拦截器可以设置多个,它采用责任链模式,多个拦截器可以按指定顺序拦截
比如:在收集的数据的event的head中加入处理的时间戳、agent的主机或者IP、固定key-value
常见的拦截器:
(1)Timestamp Interceptor | Host Interceptor | Static Interceptor | UUID Interceptor Searchand Replace Interceptor | Regex Filtering Interceptor
(2)自定义拦截器
②高级组件-Channel Selectors
Channel Selectors::Channel选择器
主要作用:对于一个source发往多个channel的策略设置
Channel Selectors类型:
(1)Replicating Channel Selector(default):将source过来的events发往所有channel
(2)Multiplexing Channel Selector:Multiplexing selector会根据event中某个header对应的value来将event发往不同的channel(header与value就是KV结构)
· Event里面的header类型:Map<String,String>
· 如果header中有一个key:state,在不同的数据源设置不同的state则通过设置这个key的值来分配不同的channel
③高级组件-Sink Processor
Sink Processor:Sink处理器
主要作用:针对Sink groups的处理策略设置
三种类型:
(1)Default Sink Processor
(2)Failover Sink Processor
(3)Load balance Sink Processor
Default是默认类型,不需要配置Sink groups;Failover是故障转移机制;Load balance是负载均衡机制。后两个需要定义Sink groups
· 应用:负载均衡、故障转移
· 用户可以通过定义多个Sink组成一个Sink Group,Sink可以用于提供组内所有的sink的负载均衡并支持从一个Sink到另一个Sink的故障转移
(1)负载均衡的配置案例:source里的event流经过channel,进入sink组,在sink组内部根据负载算法(round robin、random)选择sink,后续可以选择不同机器上的agent实现负载均衡
(2)负载均衡轮询算法:轮询调度(Round Robin Scheduling)算法就是以轮询的方式依次将请求调度不同的服务器,即每次调度执行i=(i+1)mod n,并选出第i台服务器。算法简洁,无需记录当前所有连接的状态,是一种无状态调度
(3)Sink故障转移:当Sink1处理失败,event自配置一组Sink,这组sink组成一个Failover Sink Processor,动迁移到Sink2处理,此时sink1会放到一个队列,等待故障恢复,Sink1可以正常处理event时再依据优先级重新获取event的处理权


(2) Kafka
1. Kafka的简介
Kafka是一个高吞吐、分布式、基于发布订阅的消息系统。它最初由LinkedIn公司开发使用Scala语言编写,之后成为Apache项目的一部分。Kafka是一个分布式的、可划分的、多订阅者、冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据
2. Kafka的拓扑结构图
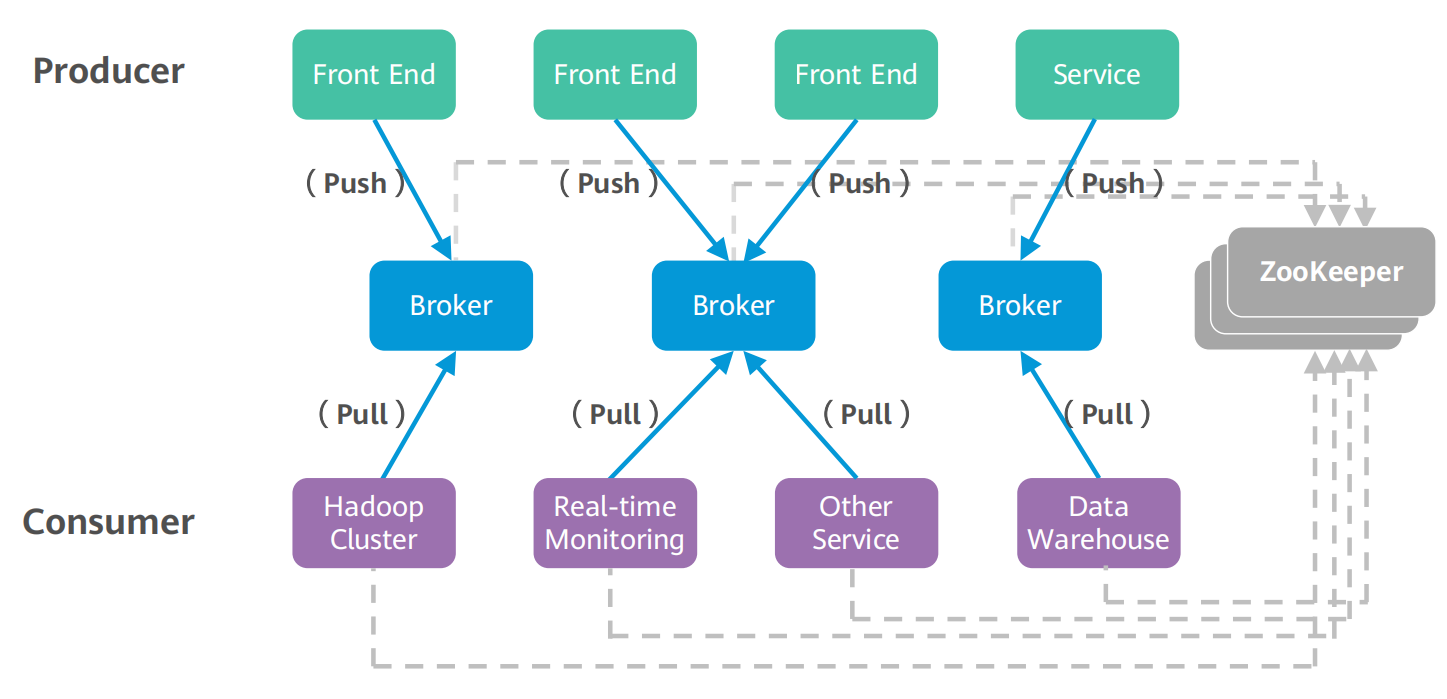
3. Kafka的组件
①Kafka的Topics
每条发布到Kafka的消息都有一个类别,这个类别被称为Topic,也可以理解为一个存储消息的队列
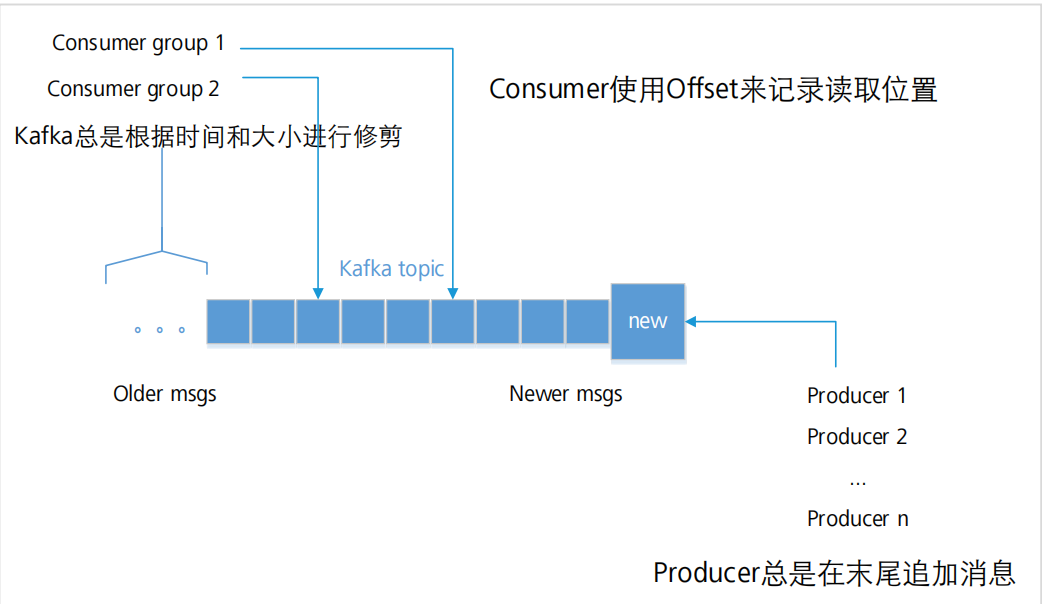
②Kafka的Broker
Broker:缓存代理,Kafka集群中的一台或多台服务器统称为Broker
为了减少磁盘写入的次数,Broker会将消息暂时buffer起来,当消息的个数达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数
Broker的无状态机制:
· Broker没有副本机制,一旦Broker宕机,该Broker的消息将都不可用
· Broker不保存订阅者的状态,由订阅者自己保存
· 无状态导致消息的删除成为难题(可能删除的消息正在被订阅),Kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除
· 消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息
③Kafka的Logs
Kafka把Topic中一个Partition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完的文件,减少磁盘占用
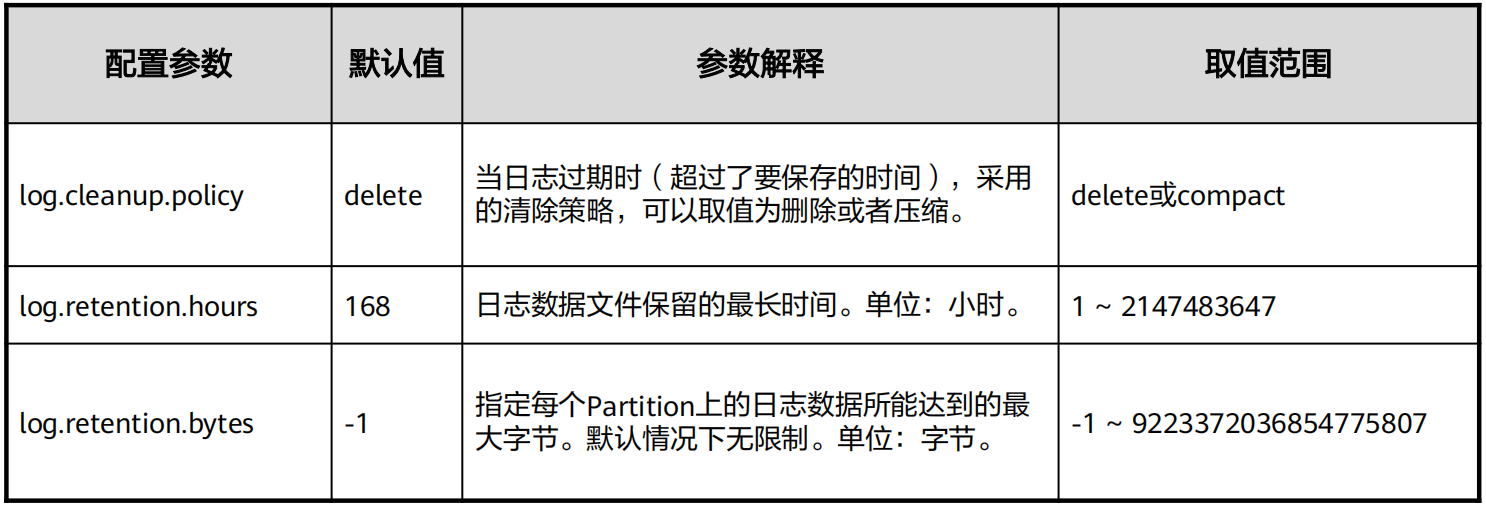
Kafka Log Cleanup:
· 日志的清理方式有两种:delete和compact
· 删除的阈值有两种:过期的时间和分区内总日志大小
④Kafka的消费组
允许Consumer Group(包含多个Consumer,如一个集群同时消费)对一个topic进行消费,不同的Consumer Group之间独立订阅
为了减小一个Consumer Group中不同Consumer之间的分布式协调开销,指定partition为最小的并行消费单位,即一个Group内的Consumer只能消费不同的partition
4. Kafka的命令
①创建一个主题
· 创建一个名为“test”的主题,它只包含一个分区,只有一个副本
![]()
· 查看主题
![]()
②Producer生产数据
· Kafka附带一个命令行客户端,它将从文件或标准输入中获取输入,并将其作为消息发送到Kafka集群。默认情况下,每行将作为单独的消息发送
· 发送一些消息
![]()
③Consumer消费数据
· Kafka还有一个命令行使用者,它会将消息转储到标准输出
· 消费数据
![]()
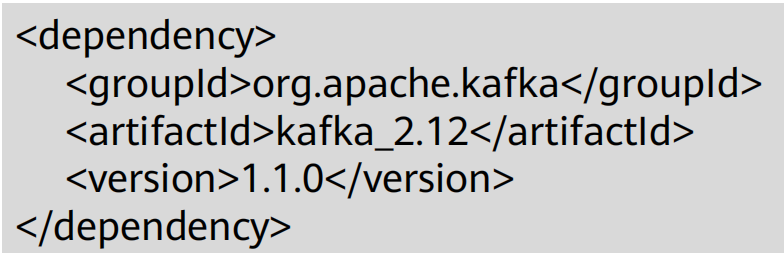
④Kafka Java操作
· Java操作Kafka需要添加Maven依赖
5. Kafka的应用场景
①消息队列
比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时。在这个领域,Kafka足以媲美传统消息系统,如ActiveMQ或RabbitMQ
②行为数据跟踪
Kafka的另一个应用场景是查看用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控或放到Hadoop离线数据仓库里处理
③元信息监控
作为操作记录的监控模块来使用,即汇集记录一些操作信息,可以理解为运维性质的数据监控
④流处理
保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将原始topic来的数据进行阶段性处理、汇总、扩充或者以其他的方式转换到新的topic下再继续后面的处理
⑤日志收集
日志收集方面,其实开源产品有很多,包括 Scribe、Apache Flume。很多人使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或 HDFS)进行处理。然而Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟
(3) Flink
1. Flink的概述
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎,对无界和有界数据流进行状态计算
Flink可以部署在各种资源提供者(如YARN,Apache Mesos和Kubernetes)上,也可以作为裸机硬件上的独立群集。配置为高可用性,Flink没有单点故障,提供高吞吐量和低延迟,并为世界上最苛刻的流处理应用程序提供支持
2. Flink的优势
Flink是一个开源的分布式流式处理框架
①提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下
②它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误
③大规模运行,在上干个节点运行时有很好的吞吐量和低延迟
3. Flink的应用场景
Flink最适合应用场景是低时延的数据处理场景:高并发处理数据,时延毫秒级,且兼具可靠性
典型应用场景有:
①欺诈识别
②异常检测
③基于规则的警报
④业务流程管理
⑤Web应用程序(社交网络)
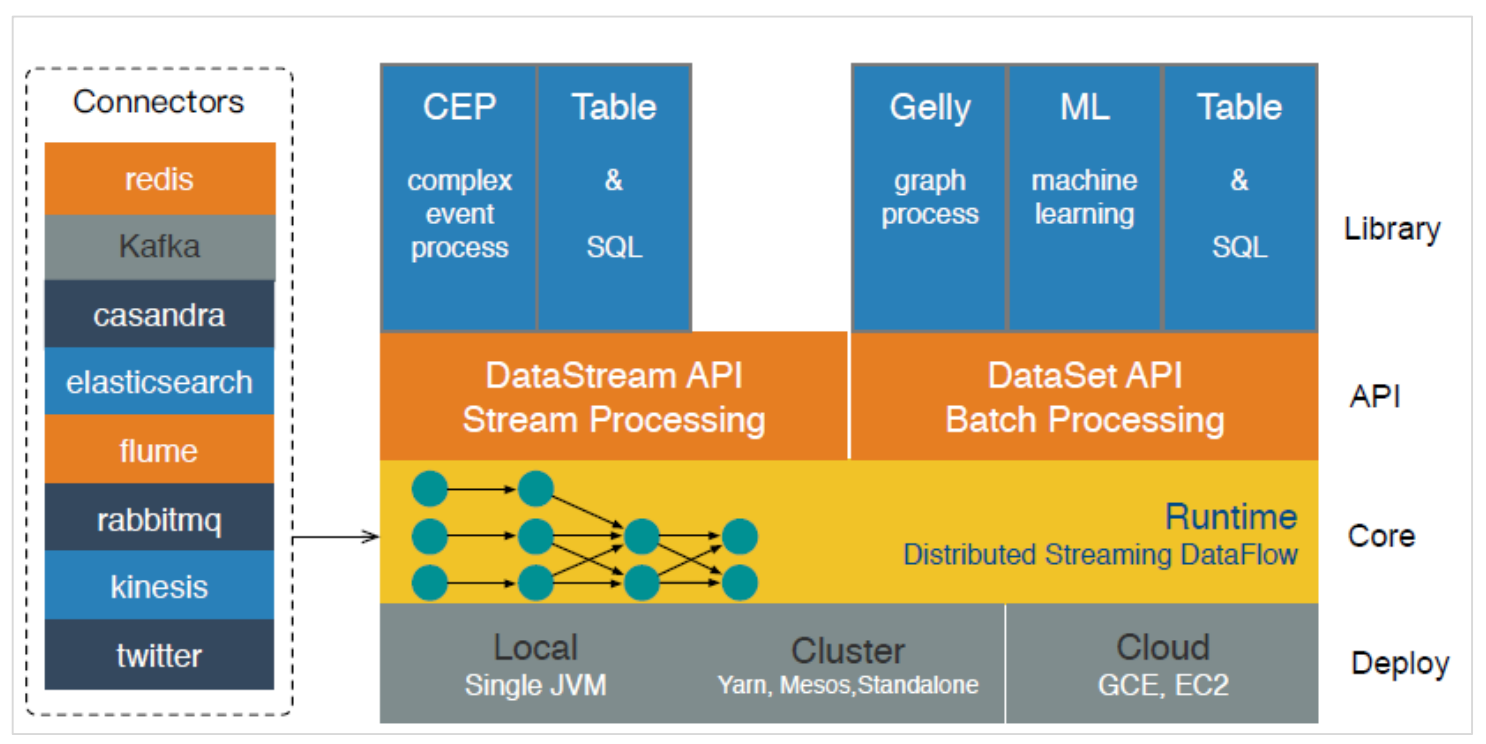
4. Fink的架构图
5. Flink的关键概念
①事件驱动:根据一个或者多个事件流提取数据,并进行计算和状态更新等
②时间语义:通过事件时间来确定事件创建的时间,并能够结合处理时间进行事件解析
③有状态流处理:Flink可以通过保持现有的计算状态以及依赖关系来进行长期的流式数据计算任务
④状态快照: Flink可以通过Checkpoint机制确保计算状态正确,并且能够保证一致性级别为Exactly-once
6. 流数据的连续处理
无界流:有定义流的开始,但没有定义流的结束。数据源会无休止地产生数据。无界流的数据必须持续处理即数据被读取后需要立刻处理。不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性
有界流:有定义流的开始,也有定义流的结束。有界流可以在读取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
7. 处理模式类型
①事件时间:是每条事件在它产生的时候记录的时间,该时间记录在事件中,在处理的时候可以被提取出来。例如,小时的时间窗处理将会包含事件时间在该小时内的所有事件,而忽略事件到达的时间和到达的顺序
追加事件时间
· Event Time可以从日志数据的时间戳(time stamp)中提取
· 我们可以直接在代码中,对执行环境调用 setStreamTimeCharacteristic方法,设置流的时间特性,具体的时间,还需要从数据中提取时间戳(time stamp)

②处理时间:当前机器处理该条事件的时间
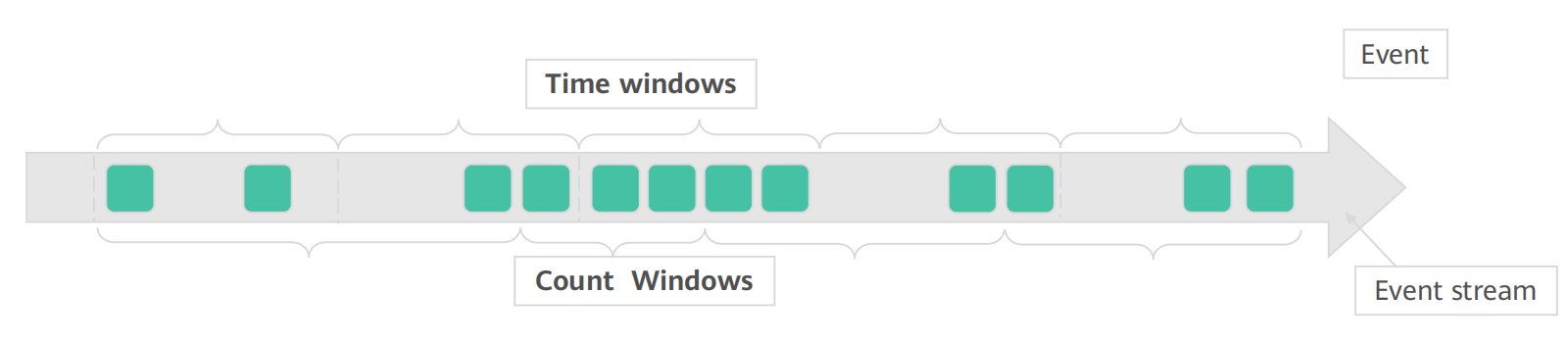
8. Flink的窗口介绍
①Flink支持基于时间窗口操作,也支持基于数据的窗口操作
按计数标准划分:滚动计数窗口、滑动计数窗口
按时间行为划分:滚动时间窗口、滑动时间窗口、会话窗口
②Flink Window API
在Flink中通过使用window()方法来进行窗口分配
Flink提供了更加简单的.timeWindow和.countWindow方法,用于定义时间窗口和计数窗口
注意:window()方法必须要在KeyBy使用之后才可以进行使用
③窗口分配器
使用window()方法时,需要填入一个参数为窗口分配器(WindowAssigner)
窗口分配器的主要功能是将每条输入的数据分发到正确的window中
Flink提供了以下通用的窗口分配器:
(1)滚动窗口(tumbling window)
(2)滑动窗口(sliding window)
(3)会话窗口(session window)
(4)全局窗口(global window)
④窗口函数
窗口函数(Window Function)定义了窗口中所采集的数据的计算操作
· 增量聚合函数(incremental aggregation functions)
每条数据到来就进行计算,保持一个简单的状态
ReduceFunction,AggregateFunction
· 全窗口函数(full window functions)
先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
ProcessWindowFunction
⑤窗口其他可选API
.trigger()-- 触发器:定义window什么时候关闭,触发计算并输出结果
.evictor()--移除器:定义移除某些数据的逻辑
.allowedLateness()--允许处理迟到的数据
.sideOutputLateData()将迟到的数据放入侧输出流
.getSideOutput()获取侧输出流
9. Flink的容错功能
· Checkpoint机制是Flink运行过程中容错的重要手段
Checkpoint机制不断绘制流应用的快照,流应用的状态快照被保存在配置的位置(如:JobManager的内存里,或者HDFS上)
Checkpoint机制:
①Checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性
②该机制可以保证应用在运行过程中出现故障时,应用的所有状态能够从某一个检查点恢复,保证数据仅被处理一次(Exactly Once)。另外,也可以选择至少处理一次(AtLeast Once)
· Flink分布式快照机制的核心是barriers,这些barriers周期性插入到数据流中,并作为数据流的一部分随之流动
10. Flink的应用程序
用户实现的Flink程序是由Stream数据和Transformation算子组成
Stream是一个中间结果数据,而Transformation是算子,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream
Sink:数据输出,支持HDFS、Kafka、文本

11. Flink的DataStream数据流处理
①DataStream数据流处理-环境
创建一个执行环境,表示当前执行程序的上下文
如果程序是独立调用的,则此方法返回本地执行环境
如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说,getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式

②DataStream数据流处理-Source
目前Flink支持的Source:
(1)从集合中读取数据
(2)从消息队列中读取数据
(3)从文件中读取数据
(4)自定义数据读取
③DataStream数据流处理-Transformation
Flink在处理DataStream数据流任务时,具有很多功能强大的算子
KeyBy算子:
(1)数据类型转换:DataStream -> KeyedStream
(2)逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的
滚动聚合算子(Rolling Aggregation)
· 滚动聚合算子可以针对Keyedstream的每一个支流做聚合 -> sum(),min(),max(),minBy(),maxBy()
④DataStream数据流处理-Sink
Flink没有类似于spark中foreach方法,让用户进行迭代的操作。虽有对外的输出操作都要利用sink完成。最后通过类似如下方式完成整个任务最终输出操作
官方提供了一部分的框架的sink。除此以外,需要用户自定义实现sink,目前经常定义的Sink为:
(1)Kafka Sink
(2)ElasticSearch Sink
(3)Redis Sink
(4)JDBC Sink
12. Flink的API
①表API
Table API是集成查询API,允许以非常直观的方式组合来自关系运算符的查询,例如选择,过滤和连接。支持Scala和Java语言
下面示例显示了一个Table API程序。程序扫描Orders表格。它过滤空值,规范化String类型的字段,并计算每小时和产品a的平均计费金额b

②SQL API
SQL查询是使用sqlQuery()方法指定的TableEnvironment。该方法返回SQL查询的结果为Table。Flink支持标准的ANSI SQL,不支持DDL语句
支持的SQL操作:from、where、UDF函数、group by、order by 、join、时间窗口、insert等
13. Flink的CEP
①Flink CEP介绍
Flink CEP是在Flink中实现的复杂事件处理(CEP)库
CEP允许在无休止的事件流中检测事件模式。通过一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据
②Flink CEP模式
处理事件的规则,被叫做“模式”(Pattern)
Flink CEP提供了Pattern API,用于对输入流数据进行复杂事件规则定义,用来提取符合规则的事件序列
每个Pattern都应该包含几个步骤,或者叫做state。从一个state到另一个state,通常我们需要定义一些条件
Scala语言版本的CEP

14. Flink SQL-Hive Streaming
2020年7月7日,Flink 1.11版本发布,与 1.10版本相比,1.11版本最为显著的一个改进是Hive Integration显著增强,也就是真正意义上实现了基于Hive的流批一体
Flink 1.11的 Hive Streaming功能大大提高了Hive数仓的实时性,对ETL作业非常有利,同时还能够满足流式持续查询的需求,具有一定的灵活性
通过Flink SQL可以更简单的对Hive表中的数据进行读写等操作
(4) Structured Streaming
1. Structured Streaming的简介
Structured Streaming是构建在Spark SQL引擎上的流式数据处理引擎,使用Scala编写具有容错功能
2. Structured Streaming的两种处理模式
Structured Streaming包括两个处理模型,微批处理模型和持续处理模型,默认是微批处理模型
· 微批处理模型:流计算引擎在处理上一批次数据结束后,再对新数据进行批量查询。在下一个微批处理之前,要将数据的偏移范围保存在日志中。所以,当前到达的数据需要在上一批次处理完,同时偏移范围记录到日志后,才能下一个批次数据继续处理,因此会有一定的延迟
· 持续处理模型:可以实现毫秒级延迟。启动一系列的连续读取、处理和写入结果任务。对于偏移范围的记录异步写入日志,以达到连续处理,避免高延迟。但这是建立在牺牲一致性为代价上的,低延迟下会丢失数据
3. Structured Streaming的程序执行过程
①导入相关依赖模块
②创建Spark Session对象
③创建输入数据源
④定义流计算过程
⑤启动流计算并计算输出结果
4. 程序模型
Structured Streaming的核心是将流式的数据看成一张不断增加的数据库表,这种流式的数据处理模型类似于数据块处理模型,可以把静态数据库表的一些查询操作应用在流式计算中,Spark运行这些标准的SQL查询,从不断增加的无边界表中获取数据
每一条查询的操作都会产生一个结果集Result Table。每一个触发间隔(比如说1秒当新的数据新增到表中,都会最终更新Result Table。无论何时结果集发生了更新,都能将变化的结果写入一个外部的存储系统(OutPut)
· OutPut可以定义不同的存储方式
(1)Complete Mode:整个更新的结果集都会写入外部存储。整张表的写入操作将由外部存储系统的连接器Connector操作
(2)Append Mode:当时间间隔触发时,只有在Result Table中新增加的数据行会被写入到外部存储。这种方式只适用于结果集中已经存在的内容(不希望发生改变的情况下),如果已经存在的数据会被更新,不适合适用此种方式
(3)Update Mode:当时间间隔触发时,只有在Result Table中被更新的数据才会被写入到外部存储系统(在Spark2.x中暂时尚未可用)
5. 时间窗口
Structured Streaming支持处理时间和事件时间,同时支持watermark机制处理滞后数据
· 处理时间:处理时间是指每台机器的系统时间,当流程序采用处理时间时,将使用各个实例的机器时间
· 事件时间:是指事件在其设备上发生的时间,这个时间在事件进入Structured Streaming之前已经嵌入事件,然后Structured Streaming可以提取该时间
6. Structured Streaming的触发器
Structured Streaming触发器定义了流数据处理的计时。共有四种选项:
①没有指定触发器设置,默认为查询以微批处理模式执行,前一个微批处理结束后,进行下一个微批处理
②Trigger.ProcessingTime(“n seconds”),固定间隔时间开启微批处理,若上一个微批处理在间隔时间内结束,则等到时间间隔后再开启下一个,若上一个在时间内还没结束,则下一个在上一个完成后立即开始
③Trigger.Once()一次微批处理所有数据,用来节省成本,集群开启,微批处理一次,然后结束,关闭集群
④rigger.Continuous(“1 second”),连续处理模式
7. 流连接
Spark2.x支持流与流的连接。在两个数据流之间生成连接结果的挑战是,在任何时间点数据集的视图对于连接的两侧都是不完整的,这使得在输入流之间找到匹配的数据更加困难。一个输入流接收的任何行都可以与另一个来自未来的、尚未接收的输入流中的任何行进行匹配。因此,对于两个输入流,Structured Streaming可以将过去的输入流缓冲为流状态,以便将每个未来输入流与过去的输入流相匹配,从而生成连接结果
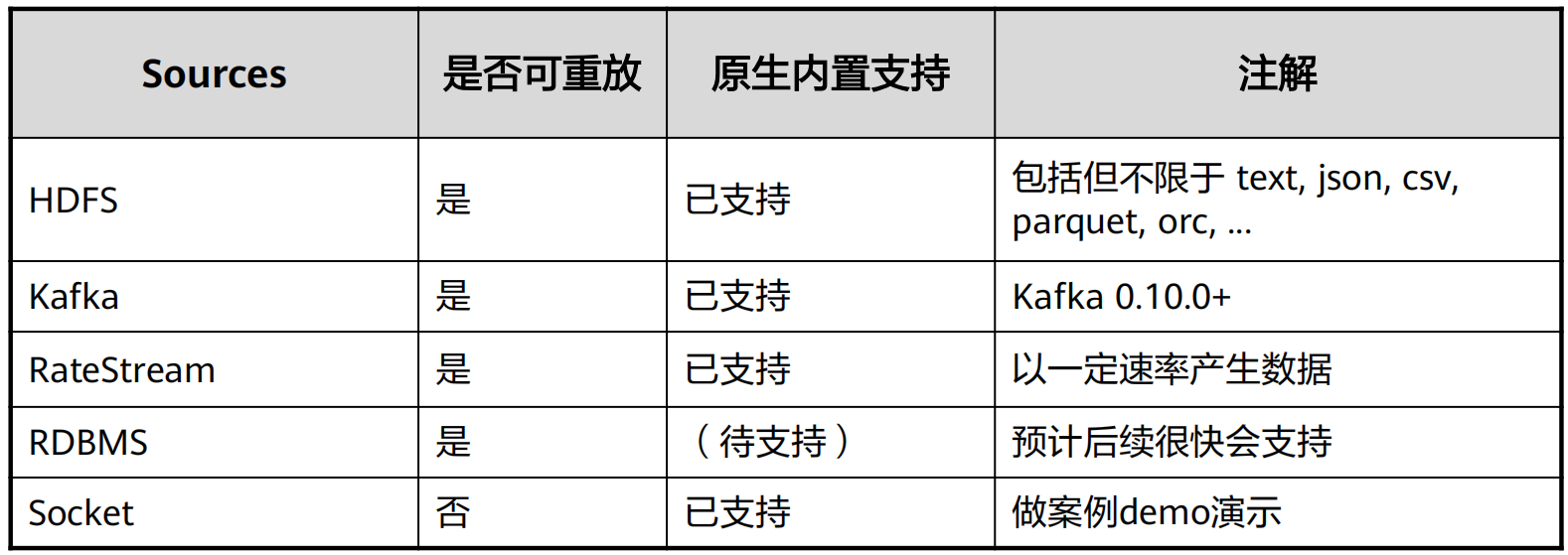
8. Source数据源
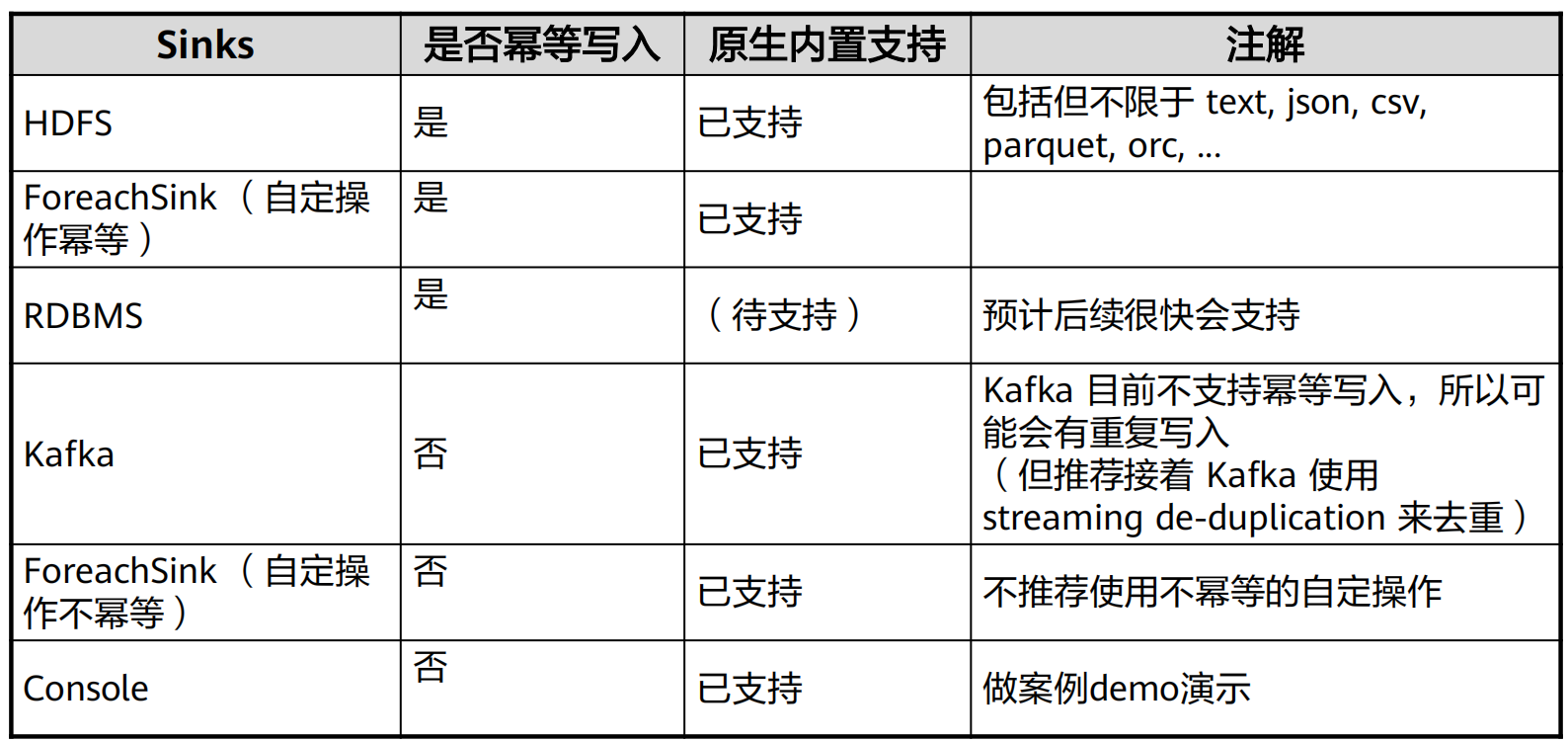
9. Sink输出源
(5) Redis
1. Redis的简介
Redis是一个高性能key-value内存数据库
Redis支持在服务器端计算集合的并、交和补集等,还支持多种排序功能
Redis使用场景有如下几个特点:
①高性能
②低时延
③数据类型丰富
④支持持久化
2. Redis的应用场景介绍
Redis提供了灵活多变的数据结构和数据操作,主要应用于如下场景:
①取最新N个数据的操作,比如获取某网站的最新文章
②排行榜应用,取TOP N操作。这个需求与上面需求的不同之处在于,前面操作以时间为权重这个是以某个条件为权重,比如按点击的次数排序
③需要精准设定过期时间的应用,如用户会话信息
④计数器应用,比如记录用户访问网站次数
⑤构建队列系统,例如消队列
⑥缓存,如缓存关系数据库中的频繁访问的表数据
⑦发布/订阅功能,pub/sub
⑧手机验证码,使用expire设置验证码失效时间
3. Redis的架构
无中心自组织的结构,节点之间使用Gossip协议来交换节点状态信息
各节点维护Key -> Server的映射关系
Client可以向任意节点发起请求,节点不会转发请求,只是重定向Client
如果在Client第一次请求和重定向请求之间,Cluster拓扑发生改变,则第二次重定向请求将被再次重定向,直到找到正确的Server为止
4. Redis的特性-多数据库
· 多数据库
每个数据库对外都是以一个从0开始的递增数字命名,不支持自定义的
Redis默认支持16个数据库,可以通过修改databases参数来修改这个默认值
Redis默认选择的是0号数据库
多个数据库之间并不是完全隔离的
· 数据库操作
SELECT 数字:可以切换数据库
flushall:清空Redis实例下所有数据库的数据
flushdb:清空当前数据库的数据
5. Redis的基础命令
①获得符合规则的键名称:keys 表达式(?,*,[ ],\?)
②判断一个键是否存在:exists key
③删除键:del key / del key1 key2
④获得键值的数据类型type:返回值可能是这五种类型(string,hash,list,set,zset)
注意:Redis的命令不区分大小写
6. Redis的数据类型
①Redis数据类型之String
字符串类型是Redis中最基本的数据类型,它能存储任何形式的内容,包含二进制数据甚至是一张图片(二进制内容)。一个字符串类型的值存储的最大容量是1GB
命令:set/get( setnx),mset/mget,incr/decr/incrby/decrby/incrbyfloat,append,strlen
②Redis数据类型之Hash
Hash类型的值存储了字段和字段值的映射,字段和字段值只能是字符串,不支持其他数据类型Hash类型的键至多可以存储232-1个字段
Hash类型适合存储对象
Redis可以为任何键增减字段而不影响其他键
命令:

③Redis数据类型之List
List是一个有序的字符串列表,列表内部实现是使用双向链表(linked list)实现的。list还可以作为队列使用
一个列表类型的键最多能容纳232-1个元素
命令:

④Redis数据类型之Set
Set集合中的元素都是不重复的,无序的,一个集合类型键可以存储至多232-1个元素
命令:

⑤Redis数据类型之Sorted set
有序集合,在集合类型的基础上为集合中的每个元素都关联了一个分数,这样可以很方便的获得分数最高的N个元素(topN)
命令:
· zadd/zscore/zrange/zrevrange/
· zrangebyscore(默认是闭区间,可使用"("使用开区间)
· zincrby/zcard/zcount(获取指定分数范围的元素个数,默认是闭区间,可使用"("使用开区间)
· zrem/zremrangebyrank/zremrangebyscore(默认是闭区间,可使用"("使用开区间 )
· 扩展:+inf(正无穷) -inf(负无穷)
7. Redis中键的生存时间-expire
Redis中可以使用expire命令设置一个键的生存时间,到时间后Redis会自动删除它:
①expire:设置生存时间(单位/秒)
②Pexpire:设置生存时间(单位/毫秒)
③ttl/pttl:查看键的剩余生存时间
④Persist:取消生存时间
⑤expireat [key]:unix时间戳1351858600
⑥pexpireat [key]::unix时间戳(亳秒)1351858700000
应用场景:
①限时的优惠活动信息
②网站数据缓存(对于一些需要定时更新的数据,例如:积分排行榜)
③限制网站访客访问频率(例如:1分钟最多访问10次)
8. Redis管道-pipeline
Redis的pipeline(管道)功能在命令行中没有,但是Redis是支持管道的,在Java的客户端(jedis)中是可以使用的
测试发现:
· 不使用管道方式,插入1000条数据耗时328毫秒

· 使用管道方式,插入1000条数据耗时37毫秒

9. Redis的持久化
①Redis持久化之RDB
rdb方式的持久化是通过快照完成的,当符合一定条件时Redis会自动将内存中的所有数据执行快照操作并存储到硬盘上,默认存储在dump.rdb文件中
redis进行快照的时机(在配置文件redis.conf中):
· save 900 1:表示900秒内至少一个键被更改则进行快照
· save 300 10
· save 60 10000
手动执行save或者bgsave命令让redis执行快照
· 两个命令的区别在于,save是由主进程进行快照操作,会阻塞其它请求。bgsave是由redis执行fork函数复制出一个子进程来进行快照操作
②Redis持久化之AOF
AOF方式的持久化是通过日志文件的方式。默认情况下Redis没有开启AOF,可以通过参数appendonly开启
· appendonly yes
Redis写命令同步的时机:
(1)appendfsync alaway:每次都会执行
(2)appendfsync everysec:默认 每秒执行一次同步操作(推荐,默认)
(3)appendfsync no:不主动进行同步,由操作系统来做,30秒一次
③动态切换Redis持久方式,从RDB切换到AOF (支持Redis 2.2及以上)
CONFIG SET appendonly yes
CONFIG SET save ""(可选)
注意:当Redis启动时,如果RDB持久化和AOF持久化都打开了,那么程序会优先使用AOF方式来恢复数据集,因为AOF方式所保存的数据通常是最完整的。如果AOF文件丢失了,则启动之后数据库内容为空
注意:如果想把正在运行的Redis数据库,从RDB切换到AOF,建议先使用动态切换方式再修改配置文件(不能自己修改配置文件,重启数据库,否则数据库中数据就为空了)
10. Redis的Java操作
通过指定集群中一个或多个实例的IP跟端口号,创建Jediscluster实例
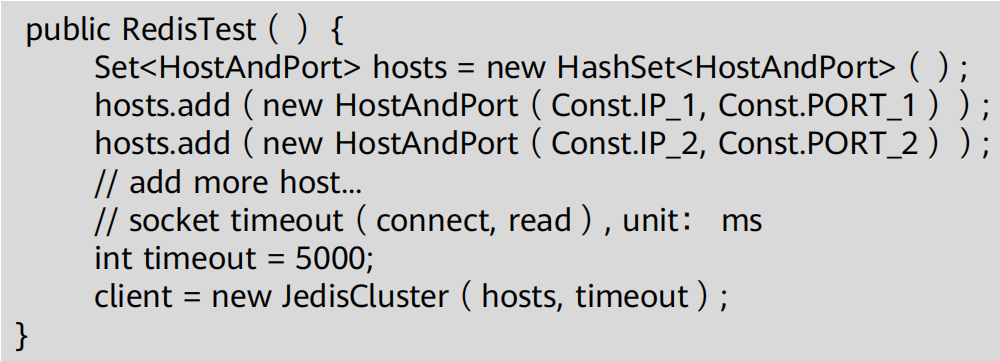
Set操作

大数据实时流处理项目实战
项目技术架构

四、大模型迁移方法论
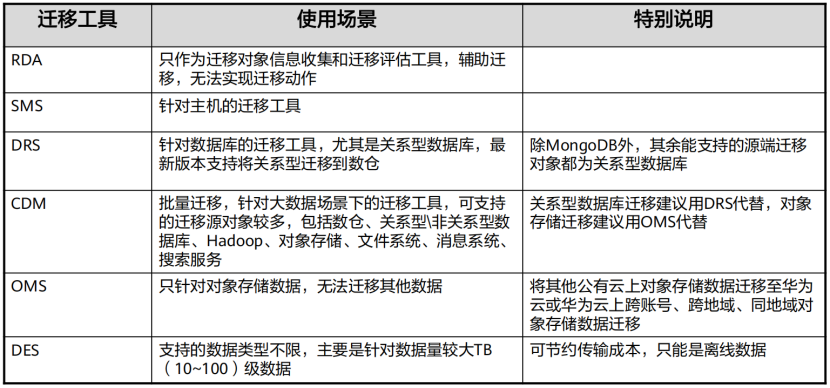
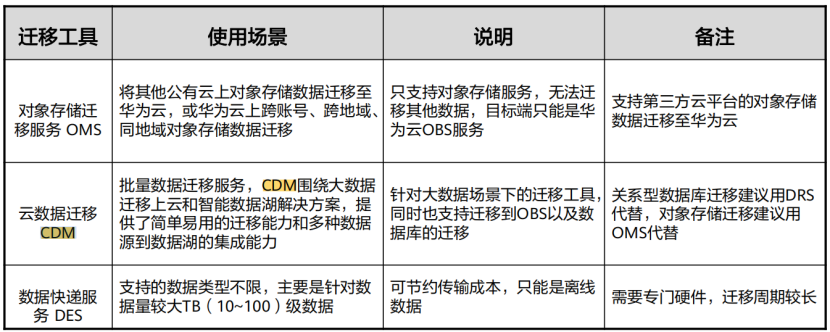
(1) 迁移工具使用场景汇总
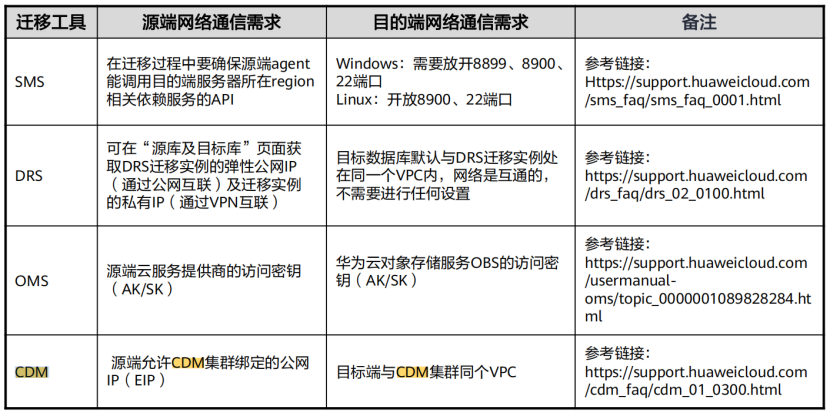
(2) 安全策略放通-常用迁移工具安全策略
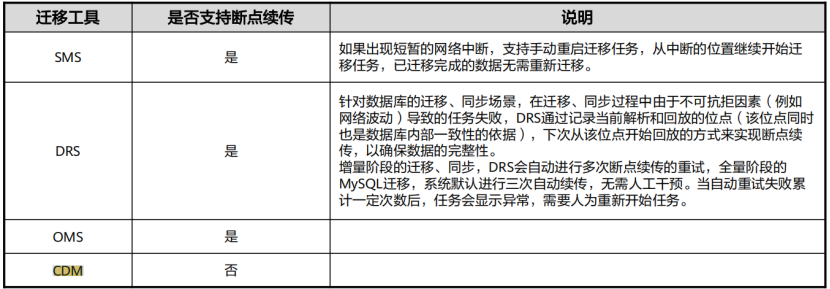
(3) 网络迁移注意事项-支持断点续传
(4) 华为云存储迁移工具对比
迁移过程中如果因网络不稳定或其他未知因素导致数据传输中断,迁移任务失败或数据丢失及数据不一致,因此所使用的迁移工具最好能支持断点续传,将大大提升迁移的效率和迁移的成功率,省时省心
五、CDM的使用
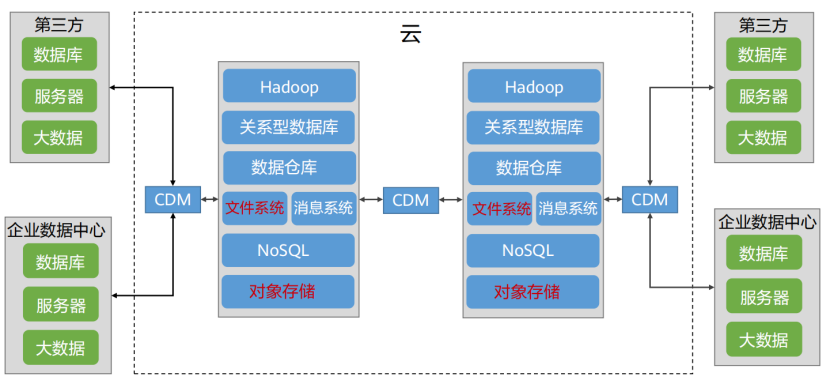
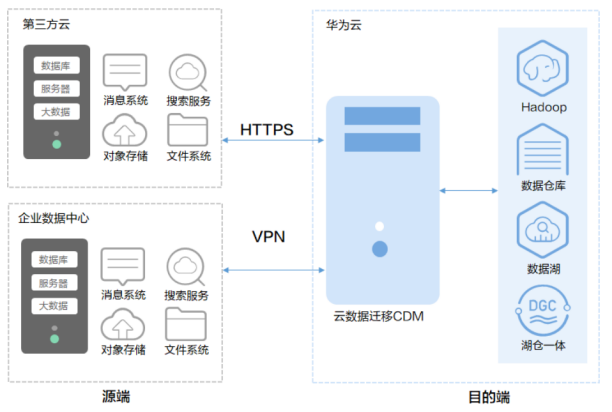
(1) 大数据迁移工具-CDM
CDM基于分布式计算框架,实现数据高效批量迁移。提供云上和云下端到端数据迁移解决方案,满足大数据场景下的各种数据迁移诉求
①增量数据迀移:支持文件增量迁移、关系型数据库增量迁移,HBase/CloudTable增量迁移,以及使用Where条件配合时间变量函数实现增量数据迁移
②事务模式迁移:支持当CDM作业执行失败时,将数据回滚到作业开始之前的状态,自动清理目的表中的数据
③字段转换:支持去隐私、字符串操作、日期操作等常用字段的数据转换功能
④文件加密:在迁移文件到文件系统时,CDM支持对写入云端的文件进行加密
⑤MD5校验一致性:支持使用MD5校验,检查端到端文件的一致性,并输出校验结果
⑥脏数据归档:支持将迁移过程中处理失败的、被清洗过滤掉的、不符合字段转换或者不符合清洗规则的数据单独归档到脏数据日志中便于用户查看。并支持设置脏数据比例闽值,来决定任务是否成功
(2) CDM功能特性
与DRS区别,CDM迁移数据库是迁移表数据,不涉及索引、视图等,针对数据库迁移选择DRS工具
(3) 云数据迁移-CDM
①云数据迁移(CDM),是提供同构/异构数据源之间批量数据迁移服务,帮助客户实现数据自由流动。支持文件系统,关系数据库,数据仓库NoSQL,大数据云服务和对象存储等数据源,无论是客户自建还是公有云上的数据源
②CDM服务基于分布式计算框架,利用并行化处理技术,支持用户稳定高效地对海量数据进行移动,实现不停服数据迁移,快速构建所需的数据架构
③CDM围绕大数据迁移上云和智能数据湖解决方案,提供了简单易用的迁移能力和多种数据源到数据湖的集成能力,降低了客户数据源迁移和集成的复杂性,有效的提高数据迁移和集成的效率
④针对数据库类型,支持的数据源有数据仓库、关系数据库、NoSQL
(4) 云数据迁移定位
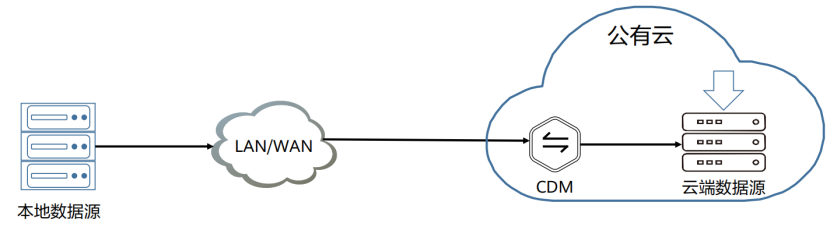
(5) 云数据迁移场景-企业数据迁移到云上
①本地数据是指存储在用户自建或者租用的IDC中的数据,或者第三方云环境中的数据,包括关系型数据库、NoSQL数据库、OLAP数据库、文件系统等
②本场景是用户利用云上的计算和存储资源,需要先将本地数据迁移上云。该场景下,需要保证本地网络与云上网络是连通的
③优势:
(1)多种数据源支持:支持关系型数据库、大数据、文件、NoSQL多种数据源
(2)简单易用:向导式任务管理,即开即用,轻松上手
(3)安全高效:全托管服务,高安全
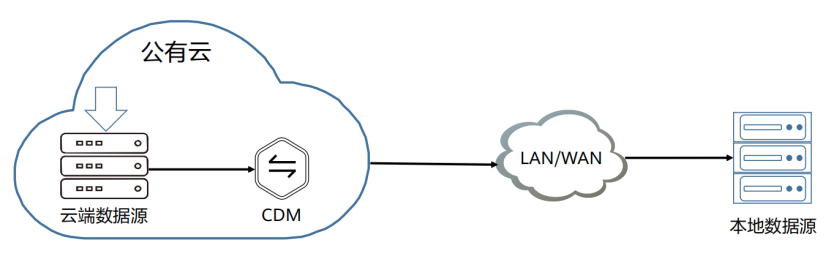
(6) 云数据迁移场景-云上数据回迁到本地
本场景是用户在使用云上计算资源对海量数据进行处理后,将结果数据回流到本地业务系统,主要是各种关系型数据库和文件系统。该场景下,需要保证本地环境的网络与云上网络是连通的
优势:
(1)多种回流系统支持:支持分析结果回流到本地数据库或文件系统
(2)简单易用:向导式任务管理,即开即用,轻松上手
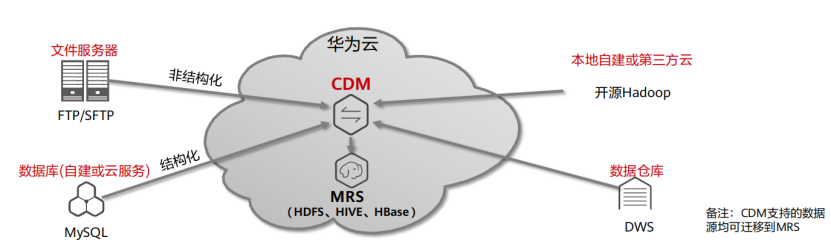
(7) 云数据迁移场景-汇聚数据到大数据平台MRS
①场景需求
(1)将各类数据汇聚到大数据平台MRS做数据分析、机器学习
(2)将非结构化文件从文件服务器、OBS等同步到MRS HDFS,将数据库、数据仓库数据同步到MRS Hive和Hbase
(3)将自建Hadoop集群中的数据迁移到MRS集群
②关键技术特性
(1)开发周期大幅缩短
(2)数据迁移系统建设成本大幅降低
(3)CSV、JSON格式支持
③已知限制
(1)可以支持开源Hadoop到MRS的迁移,暂不支持MRS到MRS的迁移
(2)一个CDM只能和一个MRS集群绑定
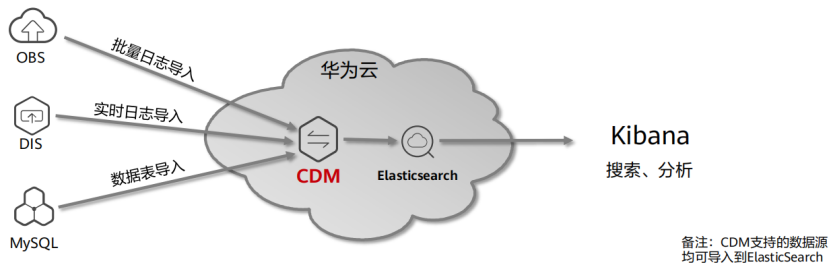
(8) 云数据迁移场景-日志数据周期性导入ElasticSearch
①场景需求
(1)将日志文件周期性导入到ElasticSearch,用于后续搜索和分析
(2)从DIS接入实时日志信息导入
(3)将关系数据库中的数据表周期性导入
②关键技术特性
(1)半结构化转结构化:正则表达式日志解析功能
(2)丰富的字段转换表达式,比如时间格式转换、脱敏、字符串转换
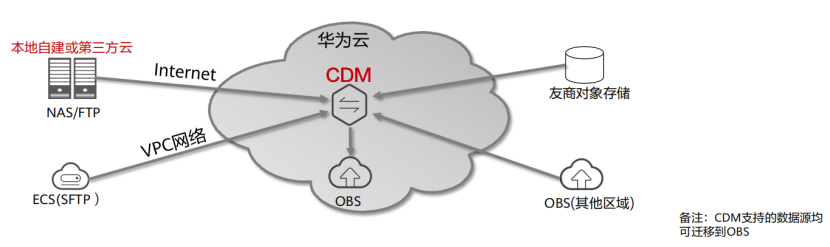
(9) 云数据迁移场景-文件备份到OBS
①场景需求
(1)将本地数据中心中NAS文件系统中的数据备份到云端OBS
(2)将ECS上的数据同步到OBS
(3)OBS跨地域的数据同步
(4)友商对象存储迁移到OBS
②增量文件同步
(1)CIFS/SMB协议支持
(2)OBS跨区域数据同步
(3)关键技术特性
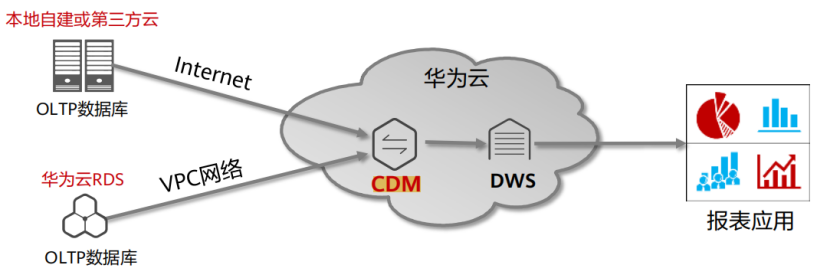
(10) 云数据迁移场景-定期采集数据到数据仓库DWS
①场景需求
(1)使用MySQL/Oracle等数据库作为OLTP数据库,然后使用数据仓库云服务DWS做数据分析和报表
(2)需要定期从MySQL同步数据到DWS
②关键技术特性
(1)支持DWS快速数据导入接口,比IDBCInsert快10x
(2)异构数据源之间数据类型转换
(3)整库迁移支持DWS自动建表
③已知限制
(1)导入到DWS快速接口,对于无法兼容的数据,会置为NULL
(2)仅支持周期性批量从数据库同步,不支持实时增量同步。Where语句+时间戳变量,可对电商、物流订单等场景实现增量数据同步
(11) CDM使用限制(针对数据库)
①CDM以批量迁移为主,仅支持有限的数据库增量迁移,不支持数据库实时增量迁移,推荐使用数据复制服务(DRS)来实现数据库增量迁移到RDS
②CDM支持的数据库整库迁移,仅支持数据表迁移,不支持存储过程、触发器、函数、视图等数据库对象迁移。CDM仅适用于一次性将数据库迁移到云上的场景,包括同构数据库迁移和异构数据库迁移,不适合数据同步场景,比如容灾、实时同步
所需图片信息均源自华为官方技术文档

















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









