






引言:为什么Transformer改变了AI格局?
2017年,Google发表论文《Attention is All You Need》,提出了Transformer架构。这一模型不仅终结了RNN/LSTM在序列建模中的统治地位,更成为当今NLP、CV甚至跨模态任务的基石(如BERT、GPT、Vision Transformer)。本文将深入解析其核心思想与实现细节。
一、Transformer的核心设计理念
1.1 传统序列模型的瓶颈
-
RNN/LSTM:顺序计算导致训练效率低,长程依赖难以捕捉
-
CNN:局部感受野限制全局信息交互
-
Transformer的突破:完全基于注意力机制,实现并行化与全局建模
1.2 核心组件总览
-
Encoder-Decoder架构:非对称设计处理输入输出映射
-
多头自注意力(Multi-Head Attention):多视角捕捉依赖关系
-
位置编码(Positional Encoding):注入序列顺序信息
二、Transformer架构深度拆解
2.1 Encoder层堆叠
python
# PyTorch风格伪代码
class EncoderLayer(nn.Module):
def __init__(self):
self.self_attn = MultiHeadAttention()
self.ffn = PositionwiseFFN()
self.norm1 = LayerNorm()
self.norm2 = LayerNorm()
def forward(self, x):
attn_out = self.self_attn(x, x, x) # Q=K=V
x = self.norm1(x + attn_out)
ffn_out = self.ffn(x)
x = self.norm2(x + ffn_out)
return x关键技术点:
1.自注意力计算
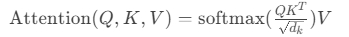
(缩放点积注意力,缓解梯度消失)
2.多头机制
将Q/K/V拆分为hh个头,独立计算后拼接:
python
# 多头拆分示例(h=8)
batch_size, seq_len, d_model = x.shape
d_k = d_model // h
x = x.view(batch_size, seq_len, h, d_k).transpose(1,2)3.位置前馈网络(FFN)
两层全连接+ReLU,提供非线性变换:
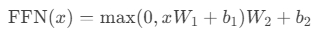
2.2 Decoder的独特设计
-
Masked Multi-Head Attention:防止当前位置“窥视”未来信息
-
Encoder-Decoder Attention:Q来自Decoder,K/V来自Encoder输出
三、关键技术创新解析
3.1 位置编码(Positional Encoding)
-
目的:为无顺序的注意力机制添加位置信息
-
实现方式:
(可学习的位置编码也在后续模型中被采用)
3.2 残差连接与LayerNorm
-
残差结构:缓解深层网络梯度消失
-
LayerNorm:对每个样本独立归一化,适合变长输入
四、Transformer的PyTorch实现核心代码
python
class Transformer(nn.Module):
def __init__(self, n_layers, d_model, h, dropout):
super().__init__()
self.encoder = nn.ModuleList([EncoderLayer(d_model, h, dropout)
for _ in range(n_layers)])
self.decoder = nn.ModuleList([DecoderLayer(d_model, h, dropout)
for _ in range(n_layers)])
def encode(self, src, src_mask):
for layer in self.encoder:
src = layer(src, src_mask)
return src
def decode(self, tgt, memory, tgt_mask, memory_mask):
for layer in self.decoder:
tgt = layer(tgt, memory, tgt_mask, memory_mask)
return tgt五、Transformer的进化与应用
5.1 衍生模型
| 模型 | 创新点 | 应用领域 |
|---|---|---|
| BERT | 双向Transformer Encoder | 文本理解 |
| GPT系列 | 单向Transformer Decoder | 文本生成 |
| ViT | 图像分块+Transformer | 计算机视觉 |
5.2 最新进展
-
稀疏注意力(Sparse Transformer):降低计算复杂度
-
线性注意力(Linear Attention):O(n)复杂度实现
-
跨模态架构(CLIP、DALL·E):多模态信息融合
六、总结与思考
Transformer通过全局注意力机制与并行化设计,解决了传统序列模型的根本缺陷。其成功启示我们:
-
模型架构创新可能比参数规模更重要
-
注意力机制具有普适性,可推广到非NLP任务
-
开源社区的持续优化(如HuggingFace库)加速了技术落地
讨论:你认为Transformer会被新一代架构取代吗?欢迎在评论区留言探讨!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









