






从Infra角度回答一下,作为 Encoder-Decoder 架构的代表模型:T5 为什么没落了以及为什么T5最大的模型只有11B。
虽然 GLM-130B 不是 Decoder-Only 架构,但是 GLM-3 及以后(现在是 GLM-4)的 GLM 系列模型都改为Decoder-Only 的架构了。就连GLM 自己的团队都抛弃了原有的架构,Follow LLaMa 了。
实际在HuggingFace上可以尝试GLM-130B的Playground,即使仅从 Foundation-Model 的角度评价,效果也很糟糕。至此 2023 年下半年之后的所有 LLM(可以被用户使用的 Chat 模型)均为Decoder-Only架构。
至此2023 年下半年之后的所有 LLM(可以被用户使用的 Chat 模型)均为 Decoder-Only 架构。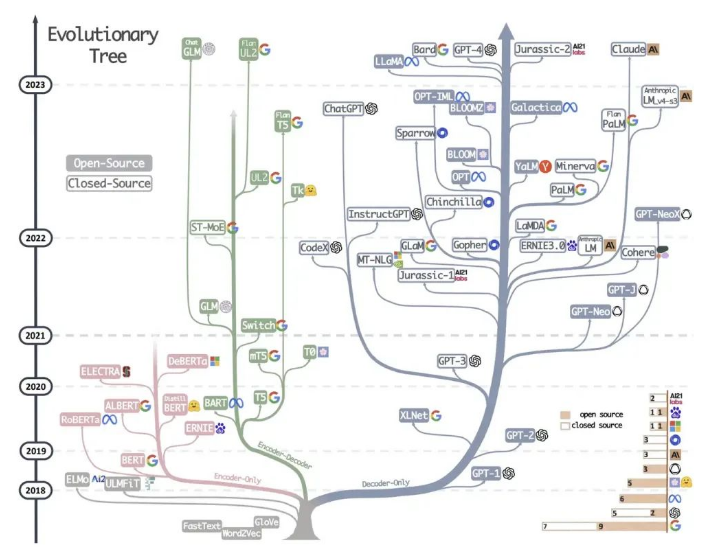
LLM 发展树
Decoder-Only 架构的 Infra 优势
个人觉得 Decoder-Only 的架构最核心的优势是非常方便于 Scale Up,基于 Scaling Laws 的实际训练成本最低。Scaling Laws 是 LLM 时代最为重要的规律发现,因此有以下的暴论:
在 LLM 时代,如果你提出的新的算法结构可能有 5% 的效果提升,但是引入了额外 50% 的训练成本(计算时间 or 通信量) 的话,那这个新的算法一定是一个负优化。因为这 50% 的训练成本,基于Scaling Laws我可以在原模型上多训练 50% 的 tokens,或者训练大一半的模型,带来的最终提升都远大于新算法的 5%。因此,新的算法研究必然在探索阶段就需要引入 Infra 因素的考量。
比较Encoder-Only、Encoder-Decoder、Decoder-Only 三者架构:
-
• 相同参数量的训练效率上:Decoder-Only > Encoder-Only > Encoder-Decoder
-
• 现行分布式并行策略下,可以扩展的参数量上限和分布式集群规模的上限:Decoder-Only Encoder-Only Encoder-Decoder
-
• Encoder-Only 其实并不太适合做 NLP 的生成式任务(Chat),目前在 CV 领域应用的比较多(ViT),输入/输出通常是固定像素大小的图片,token 之间没有非常强的先后依赖关系,因此先排除 BERT。
下面仅讨论两种架构的代表模型:Encoder-Decoder 架构的 T5 和 Decoder-Only 的 GPT。
去年 8 月在一次交流中,有位算法研究者就表示 T5 是一个非常优美的模型,且如果继续做下去应该比 GPT 更有前途。我当时表示 T5 很难扩展到千亿参数规模,Infra 很难做,对方表示那这个是 Infra 的问题应该 Infra 来解决,而不是算法的问题。我其实并不认同这个观点。
T5 很难 Scale Up 的核心原因是T5 很难使用 Pipeline Parallelism。 可能 T5 的理论计算量只是 GPT 的不到 2 倍,但实际在 千卡集群、千亿参数量 的情况下,GPT 的 MFU 可能是 T5 的十倍以上。
实际上 Megatron 是支持 T5 训练,并开启 Pipeline Parallelism 的,但是效果非常非常差,实测可能增加一倍 GPU,开启 PP 反而会让总吞吐下降。
参见:
https://github.com/NVIDIA/Megat[2]
流水并行是千卡以上分布式训练中最重要的特性
流水并行 (Pipeline Parallelism ) 是 LLM 分布式训练扩展到千卡集群以上的一个核心 feature,具体可以参考我三年前写的文章:
OneFlow —— 让每一位算法工程师都有能力训练 GPT[3]
NVIDIA在3076张A100集群上训练的1T参数量LLM使用的并行方式是:
-
• Data Parallel Size = 6
-
• Tensor Parallel Size = 8
-
• Pipeline Parallel Size = 64
可见并行度最高的是流水并行,超过 DP 和 TP 十倍左右。为什么在三千卡集群上最主要的并行方式是流水并行?
流水并行的核心优势就是用比较少的 Pipeline Bubble 代价 (当 gradient accumulation step 很大时可以忽略不计),较少的 Tensor Buffer 显存代价,以及非常低的通信开销,将大模型分割在不同的 Group 中。大幅减少了单张 GPU 上的 weight tensor 大小(数量) 和 Activation tensor 大小(数量)。
同时,跟Tensor Parallel相比,Pipeline Parallel的通信代价很低且可以被 overlap,Tensor Parallel 虽然也能切分模型大小,但是需要全量的数据(没有减少 Activation tensor 大小),另外极高的通信频率和通信量使得 Tensor Parallel 只能在机器内 8 张卡用 NVLink 等高速互联来实现,跨机的 TP 会严重拖慢速度。
不仅如此,Pipeline Parallel还将Data Parallel 的模型更新限定在一个很小的范围内(比如六台机器),DP所需的AllReduce通信会随着机器数量增多而变慢。PP也让DP所需同步的模型梯度大小变小了,大大减缓了模型更新对于训练速度的影响。
因此Pipeline Parallel是让模型可以达到千亿、集群可以扩充到千卡以上的一个最重要的特性。
然而流水并行有很重要的约束条件:需要一个规整对称的、线性顺序的网络结构。GPT 就是这样一个典型的网络结构:完全一样的 Transformer Layer 顺序堆叠,没有分叉和不对称情况,当均匀切分 Layer 时,各个 Stage 的前向/反向计算时间均一致。流水并行训练时的 time line 参考如下: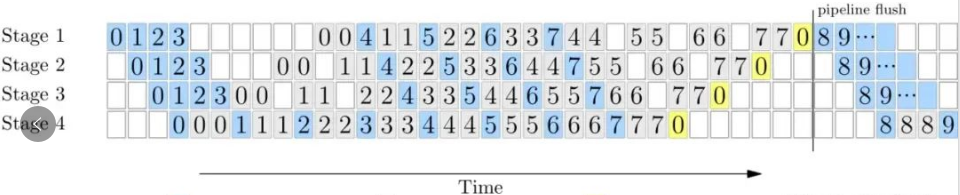

流水并行实际的 time line 参考如下 (反向的计算时间是前向的两倍)
整个集群最高效的训练时间段是step 4、5、6、7的前向和step 0、1、2、3 的反向同时在所有 stage 上并行计算的时候,这个时候集群没有空闲,全部都在并行执行。当我们增加 acc step (比如从8增加到64)时,中间部分完美并行的时间段占比就会更长,bubble time 的占比就会越来越小。
但T5的网络结构比GPT要复杂很多,T5是Encoder-Decoder 架构,整个网络分为两大块,且Encoder 和Decoder的Transformer Layer参数大小、Attention 计算量、Context Length 等均不一致,导致 Encoder 的理论计算量要比 Decoder 大很多 (整个网络不是均匀对称的)。 更要命的是, T5 Encoder 的输出要发给每个 Decoder Layer,网络结构不是线性而是有大量的分叉,前向反向之间包含了复杂的数据依赖关系, 会导致流水并行中,各个 Stage 之间会产生大量的、非对称的、间隔跨多个 Stage 的数据依赖, 更加剧了流水并行的 load balance 问题。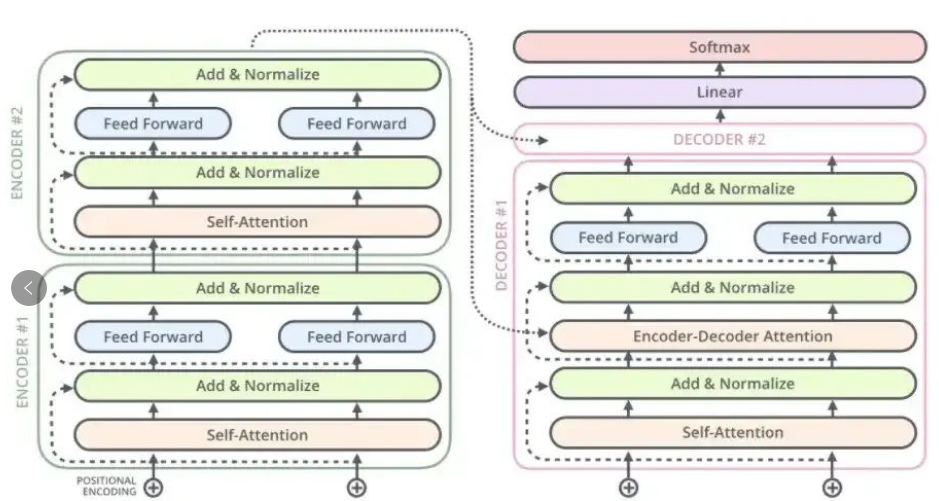

T5 的网络结构, Encoder 的输出会发送给多个 Decoder 的输入
所以你如果直接使用 Megatron 跑 T5 的 Pipeline Parallelism,会从 nsys prof 时间线上看到大量的缝隙,各个 Stage 之间在互相等待,无法真正流水并行起来。
Megatron 的T5 PP并不是一个最佳实践, 所以理论上可以开发一个针对于 T5 的 PP 版本,通过比较复杂的工程实践优化重叠效果来提升性能。但即使可以开发出来,也肯定比GPT的训练效率低。
如果我们不用 Pipeline Parallelism 来训练T5,那么只能借助:DP、TP 和 ZeRO 来进行并行优化了,这就约束了T5的所有 Layer 都必须放在每一个 GPU 上,这种方式在 13B 量级的模型上是 OK 的,但是再往上扩展到 100B、1T量级就不work了。同时由于TP只能开到 8(跨机器也会慢几倍), 在千卡GPU集群以上,大量的DP带来的通信变慢的影响也很严重(ZeRO-2/3 会大幅加剧这种通信开销)。所以我们才说,虽然 T5 的理论计算量相较于 GPT 没有增加很多,但是在千亿参数、千卡集群以上规模的时候,T5 的实际训练效率比GPT慢很多倍。
即使到现在,也没有一个超过 11B 的 T5 模型发布, 而 11B 恰好是一个不借助 PP,仅通过 ZeRO + TP 就可以训练的模型大小, 避免了 T5 的模型结构非对称性对于 PP 的灾难性影响。
https://github.com/google-resea[4]
总结
T5 Scale up 到100B、500B的难度很大,训练成本的增加远远高于GPT。因此也许100B 的T5训练10T tokens的模型能力比100B的GPT更强,但为此要支付的算力/时间成本远大于 100B GPT 训练 10T tokens,以至于:
-
• 没有公司愿意支付这样的代价
-
• 我还不如支付相同的代价,让 GPT 多训练更多倍的 Tokens;或者训练一个参数量大很多的 GPT
在 Scaling Laws 还没有看到失效的迹象的今天,我们的 LLM 算法演化一定要考虑模型结构的调整对于实际训练效率的影响,否则可能一切花里胡哨的 idea 都只是“玩具”,不值得企业为其付出上千万美金的训练成本。
如果你还想学习更多的AI大模型知识,这里我也贴心的为大家准备了一份学习资料。无偿分享给大家,VX扫描以下二维码即可领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









