







一、前言
大家好,这里是matlab图像处理毕设系列文章!
各位同学对毕设这一块有任何疑问都可以联系咨询交流。https://user.qzone.qq.com/3249726188
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大,一些同学在毕业设计上,耗费时间长、精力耗费多,最后折腾一番还达不到要求,吃力不讨好。希望这些系列的文章对各位同学的思考能带来一点帮助。
系列文章均以案例为基础,简要概述算法原理和具体代码算法流程,话不多说,今天要分享的新项目是
基于傅里叶描述子和KNN的水果识别系统。
二、识别原理
在图像处理领域,传统图像识别方法的核心是手工设计特征并结合分类器进行模式识别。其流程可分为特征提取与分类两大部分,以下是具体原理和关键技术:
(1)特征提取
传统方法通过人工设计的特征描述图像内容,主要类型包括:
1. 颜色特征
颜色直方图:统计图像中颜色的分布,对旋转和平移不敏感。
颜色矩:通过颜色均值和方差等统计量描述颜色分布。
颜色空间转换:如RGB转HSV,增强颜色区分度。
2. 纹理特征
LBP(局部二值模式):通过局部像素灰度对比描述纹理,对光照变化鲁棒。
Haralick特征:基于灰度共生矩阵(GLCM)提取纹理的统计特性(如对比度、相关性)。
Gabor滤波器:模拟人类视觉系统,通过多尺度、多方向的滤波器组提取纹理。
3. 形状特征
HOG(方向梯度直方图):统计局部区域的梯度方向分布,常用于行人检测。
SIFT(尺度不变特征变换):检测关键点并生成具有尺度、旋转不变性的描述子。
边缘检测:如Canny算法提取轮廓,结合形状上下文(Shape Context)描述形状。
4. 关键点与局部特征
SURF(加速稳健特征):SIFT的加速版本,通过Hessian矩阵检测关键点。
ORB(Oriented FAST and Rotated BRIEF):结合FAST关键点检测与BRIEF描述子,效率高。
(2)分类器
提取的特征向量作为输入,常用分类器包括:
1. 支持向量机(SVM)
通过核函数(如线性、RBF)将特征映射到高维空间,寻找最大间隔超平面进行分类。
适用场景:小样本、高维特征(如HOG+SVM用于行人检测)。
2. K近邻(K-NN)
基于距离度量(如欧氏距离)找到训练集中最近的K个样本,通过多数投票分类。
特点:简单但计算复杂度高,需特征归一化。
3. 随机森林(Random Forest)
集成多棵决策树,通过投票或平均提升鲁棒性,适合高维特征。
4. Adaboost
结合多个弱分类器(如Haar特征+决策树),通过加权投票增强分类效果,常用于人脸检测。
(3)完整流程
预处理:灰度化、归一化、去噪(如高斯滤波)、直方图均衡化。
特征提取:根据任务选择颜色、纹理、形状等特征,组合成特征向量。
特征处理:降维(如PCA)或特征选择,去除冗余信息。
训练分类器:使用标注数据训练模型(如SVM)。
测试与推理:对新图像提取相同特征,输入分类器得到结果。
三、核心算法介绍
(1)傅里叶描述子(Fourier Descriptors)
1. 基本思想
傅里叶描述子是一种基于傅里叶变换的形状特征提取方法,用于描述物体轮廓的几何特性。其核心思想是将闭合轮廓的坐标序列(如二维边界点)转换为频域表示,通过保留低频分量来捕捉形状的主要特征,同时具有对平移、旋转、尺度变化的鲁棒性。
2. 数学原理
轮廓表示
假设物体轮廓由 NN 个有序点组成,每个点坐标为 (xk,yk)(xk,yk),其中 k=0,1,...,N−1k=0,1,...,N−1。
将坐标转换为复数形式:
zk=xk+iyk(i为虚数单位)zk=xk+iyk(i为虚数单位)
傅里叶变换
对复数序列 {zk}{zk} 进行离散傅里叶变换(DFT),得到频域系数:
Zn=1N∑k=0N−1zke−i2πnk/N(n=0,1,...,N−1)Zn=N1k=0∑N−1zke−i2πnk/N(n=0,1,...,N−1)
其中,ZnZn 是第 nn 个傅里叶系数。
特征提取
- 低频分量:∣Z0∣∣Z0∣ 表示轮廓的质心位置(平移信息)。
- 高频分量:∣Zn∣∣Zn∣(n≥1n≥1)描述细节特征(如尖角、弯曲)。
鲁棒性处理:
- 平移不变性:忽略 Z0Z0(去除质心影响)。
- 旋转不变性:取系数的模值 ∣Zn∣∣Zn∣。
- 尺度不变性:归一化系数(如除以 ∣Z1∣∣Z1∣)。
3. 关键特点
- 抗噪性:高频噪声对应高频分量,可通过截断高频系数实现去噪。
- 紧凑性:仅需保留前 MM 个低频系数(M≪NM≪N)即可近似重建形状。
- 不变性:对平移、旋转、缩放具有理论上的不变性(需归一化处理)。
4. 应用场景
形状匹配:比较不同形状的傅里叶描述子相似度(如欧氏距离)。
轮廓压缩:用少量系数存储复杂形状。
医学图像分析:如细胞形态识别、器官轮廓分类。
(2)K最近邻算法(K-Nearest Neighbors, KNN)
1. 基本思想
KNN是一种基于实例的监督学习算法,核心假设是“相似样本在特征空间中彼此靠近”。其分类或回归结果由最近的 KK 个邻居的投票(分类)或加权平均(回归)决定。
2. 算法流程
输入:
- 训练集 {(x1,y1),(x2,y2),...,(xN,yN)}{(x1,y1),(x2,y2),...,(xN,yN)},其中 xixi 为特征向量,yiyi 为标签。
- 测试样本 xtestxtest。
- 参数 KK(邻居数量)和距离度量方式(如欧氏距离)。
- 计算距离:
计算 xtestxtest 与所有训练样本 xixi 的距离:di=distance(xtest,xi)di=distance(xtest,xi)
- 选择邻居:
选取距离最小的前 KK 个样本,记其标签为 {y(1),y(2),...,y(K)}{y(1),y(2),...,y(K)}。
决策规则:
- 分类任务:多数投票法,即统计 KK 个邻居中各类别出现次数,选择最多者。
- 回归任务:取 KK 个邻居标签的均值。
3. 关键参数与优化
距离度量:
- 欧氏距离:d(x,y)=∑i=1n(xi−yi)2d(x,y)=∑i=1n(xi−yi)2(最常用)。
- 曼哈顿距离:d(x,y)=∑i=1n∣xi−yi∣d(x,y)=∑i=1n∣xi−yi∣。
- 余弦相似度:cosθ=x⋅y∥x∥∥y∥cosθ=∥x∥∥y∥x⋅y(适合高维稀疏数据)。
K值选择:
- 小K(如K=1):模型复杂,易过拟合(对噪声敏感)。
- 大K(如K=N):模型简单,易欠拟合(忽略局部特征)。
- 交叉验证:通过实验选择使验证集误差最小的K值。
数据预处理:
- 归一化:消除特征量纲差异(如Min-Max标准化)。
- 降维:对高维数据使用PCA等方法减少计算量。
(3)傅里叶描述子与KNN的结合
流程示例:
使用傅里叶描述子提取图像轮廓特征(低频系数)。
将特征向量输入KNN分类器,计算与训练样本的距离。
根据最近邻的类别标签进行形状分类。
优势:
傅里叶描述子提供平移/旋转不变的形状表示。
KNN无需复杂模型训练,适合小样本场景。
局限性:
对轮廓提取的准确性依赖较高。
高维傅里叶系数可能加剧KNN的维数灾难问题。
(4)总结
傅里叶描述子通过频域分析捕捉形状本质特征,是传统图像分析中的重要工具。
KNN以简单直观的方式实现分类与回归,但需注意计算效率和维度问题。
两者结合可构建轻量级图像识别系统,适用于资源受限或可解释性要求高的场景。
四、代码仿真效果呈现
(1)训练图库



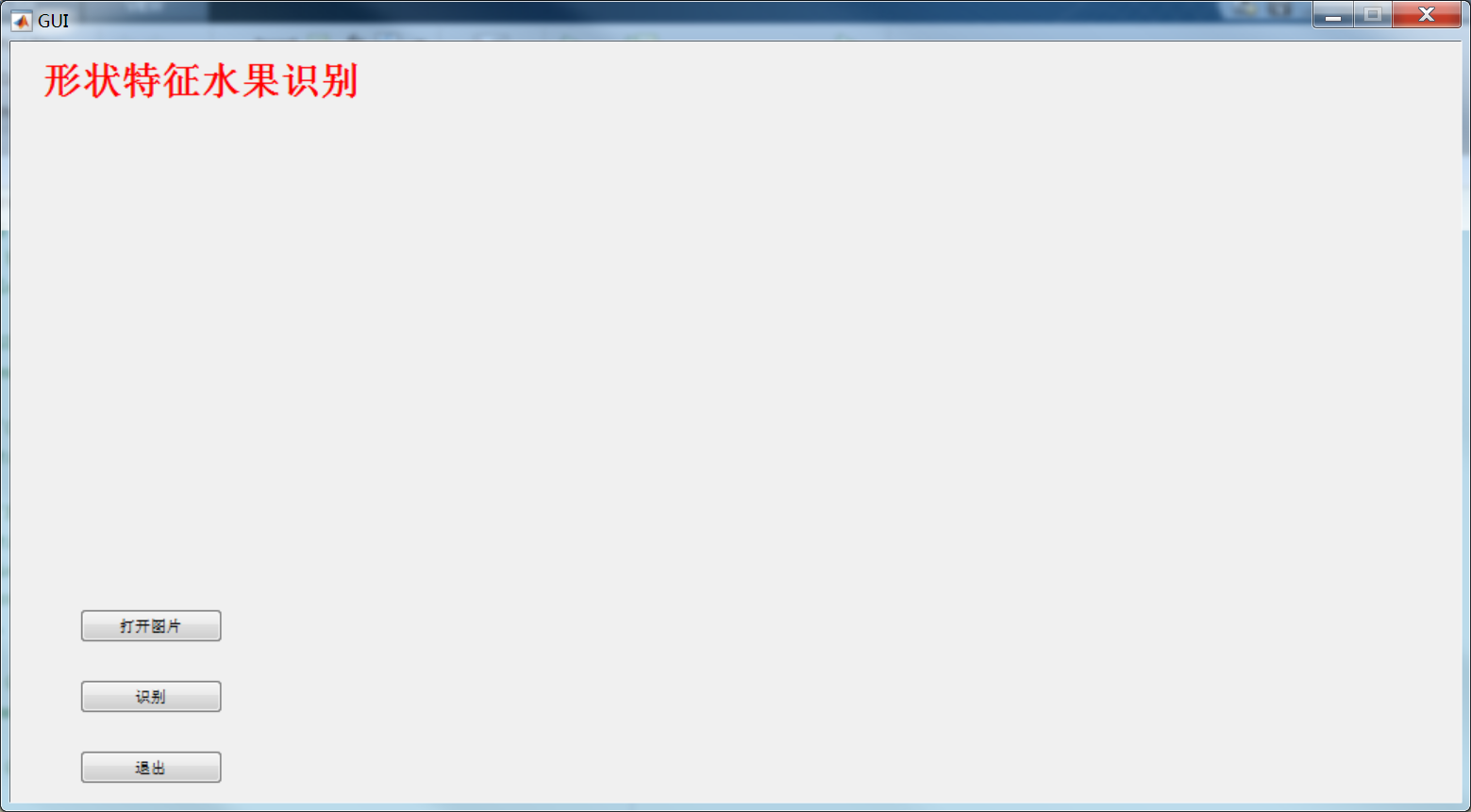
(2)GUI效果展示

(3)部分关键代码
完整项目代码可以联系博主。
clear
clc
close all
%%
% 识别部分代码
%
%% 读取图片部分
% 读取图像
[filename,pathname,filter] = uigetfile({'*.jpg;*.jpeg;*.bmp;*.gif;*.png'},'选择图片');
if filter == 0
return
end
str = fullfile(pathname,filename);
img_filename=str;
I=imread(str);
I_source=I;
% 显示
figure
imshow(I);
title('输入的原图');
%% 载入数据库
load mydatabase
% 获取图片数,database_pic
[database_pic,N]=size(mydatabase);
%% 提取图片特征
fprintf('正在计算图片的特征...\n');
% 生成傅里叶描述子特征
Feature_fourier=My_fourier_feature(I);
% 生成形状特征
[T]=Feature_fourier';
% 生成特征
Feature=T;
%% 距离计算部分
fprintf('与数据库进行比对识别...\n');
dist=zeros(1,database_pic);
for i=1:database_pic
dist(i)=sum(abs(mydatabase(i,:)-Feature));
end
















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









