







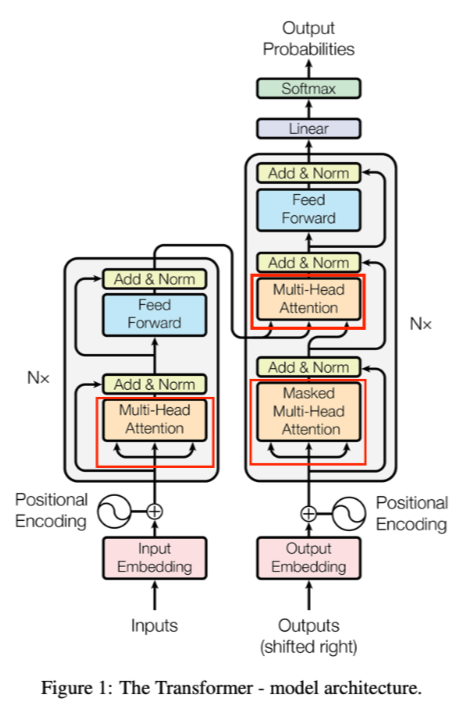
| 1 | 【大模型技术】Attention注意力机制详解一 |
| 2 | 【大模型技术】Attention注意力机制详解二 |
| 3 | 【大模型技术】Attention注意力机制详解三 |
Attention的本质是通过点积来衡量q和k之间相关性并进行加权求和,由于输入的不同,可分为自注意力和交叉注意力机制
为什么需要Attention
在nlp领域,输入的序列较长,如文本、音频和视频等等,传统的RNN方法在处理较长序列时会出现梯度消失或梯度爆炸,一种专门用于训练推理专用模型以实现。
Attention就是在模型处理当前时间步时候,可以自适应地关注序列中更重要的部分,通过显式地计算每个位置的相关性,并加权求和来获取上下文信息。
Attention机制可以让模型动态分配注意力权重,使得生成某个词的时候,可以侧重参考输入序列的相应语义部分, 捕捉长距离依赖方面更出色。
注意力机制的核心目标是:识别上下文对词义的调整和影响。
- 输入是一组词向量,这些词向量已经包含基础语义(来自词典),但这种语义是客观、静态的。
- 真正赋予文本主观语义的是词序和上下文组织方式。
- 比如“美女”在不同语境中可能表达完全不同的含义。
所以,注意力机制的关键在于:捕捉上下文如何修改原本的客观词义。
注意力机制计算
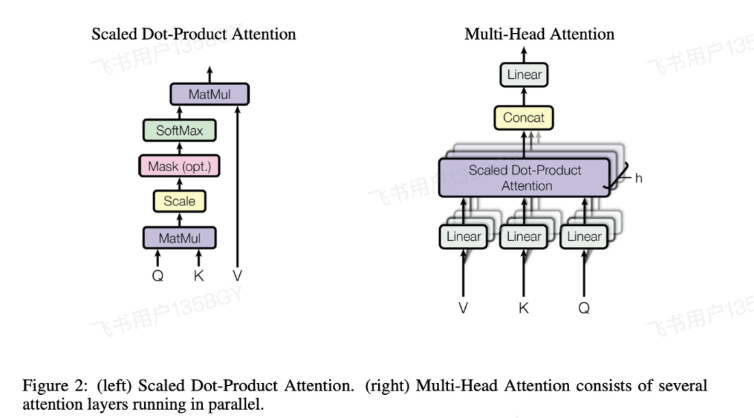
以transformer经典的Scaled Dot-Product Attention计算为例,我们需要先了解Q,K,V
- Q(Query):是当前需要关注的信息,用于寻找相关信息。
- K(Key):是每个元素的标识或特征,用于与Query比较。
- V(Value):是每个元素的实际内容,用于生成最终输出。
词嵌入已经解决了单个词单个token语义的问题了,注意力机制要解决的就是许多词组合在一起之后,整体体现出来的那个语义。
你只有把一句话里多个词同时输入到模型里面,前面说的那一点才能体现出来,所以接下来讲解输入部分,就不考虑只输入一个词的情况了,而是考虑输入一组值的情况。 这个时候这组值向量就组成了一个数据矩阵。假如说输入的是一个T行的矩阵,输出它也是一个T行矩阵。 至于输出的列数,也就是一个词向量它的维度的个数,我们把token变成词向量。
为什么 Q 和 K 的内积能体现上下文关系?
- 把 Q 和 K 看作一组向量。
- 它们的乘法本质是两两之间的内积计算。
- 内积表示一个向量在另一个上的投影,反映的是相关性。
- 所以,QK^T 就是在衡量:每个词与其他词在语义上的相关程度。
矩阵运算可以从多个角度理解:
- 一种是看作空间变换(线性代数视角);
- 另一种是看作向量集合之间的关系(语义交互视角);
在注意力机制中,我们选择后者,因为它更符合语言理解和模型设计的初衷。
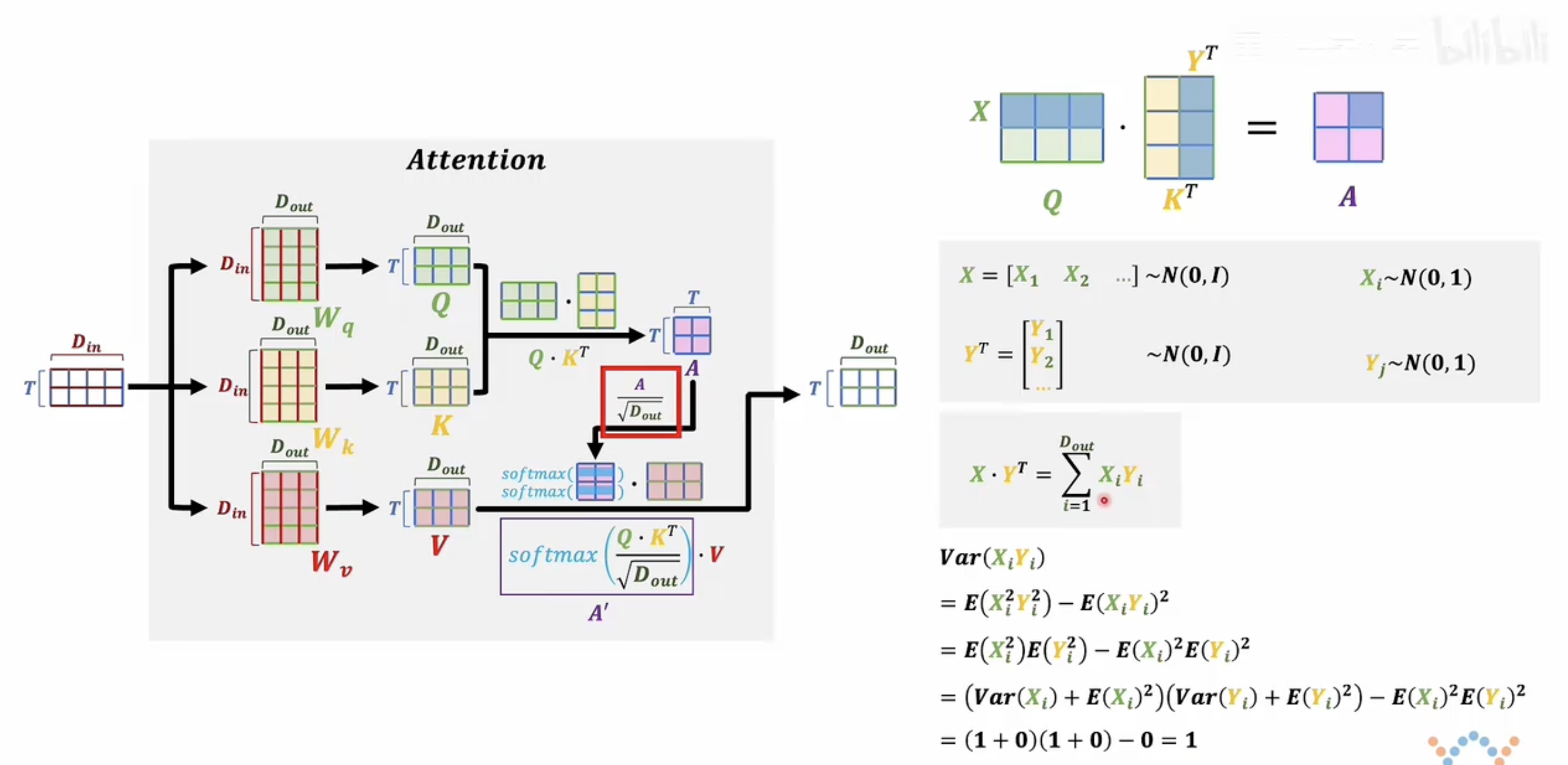
在注意力机制中,输入的词向量矩阵首先会分别与三个可学习参数矩阵 W_Q、W_K、W_V 相乘,得到对应的 Q、K、V 矩阵。这一步本质上是完成了从原始词向量空间到新空间的线性变换。
真正体现注意力机制核心的是后续操作:
-
计算注意力得分矩阵 A:
将 Q 与 K 的转置相乘(也可以理解为 K 与 Q 的转置相乘,本质相同),得到一个的矩阵 A,其中每个元素表示两个位置之间的相关性或注意力强度。
-
缩放操作:
对 A 中的每一个元素除以(
是 K 的维度),这个步骤称为“缩放(scaling)”,目的是防止点积结果过大导致 softmax 进入饱和区,影响梯度传播。
为什么要这样做?我们可以从概率的角度来解释:
- 假设 Q 和 K 的每一行都服从标准正态分布(均值为0,方差为1),并且各分量之间相互独立。
- 那么 Q 的一行与 K 的一列做点积后,其结果是一个期望为0、方差为 dₖ 的高斯分布。
- 因此,为了使该分布重新变为标准正态分布(方差为1),我们对结果除以
。
这样处理后,softmax 的输入数据更稳定,训练过程也更加平稳有效。
Q 与 K 相乘后再除以
注意力机制中缩放操作的概率解释
我们重点分析注意力得分矩阵 中的一个元素。该元素由 Q 的一行与 K 的一列相乘得到,即:
假设 Q 和 K 的每个元素都服从标准正态分布(均值为 0,方差为 1),并且相互独立。
分析单个乘积项的方差
对于每一项 :
- 期望:
- 方差:
当我们将所有 $ d_k $ 项累加后,整体的方差变为:
缩放操作的意义
为了使 重新恢复为标准正态分布,我们需要对其除以标准差
:
这样处理后, 的期望仍为 0,方差为 1,更适合后续的 softmax 操作。
- Q、K、V 是输入词向量经过线性变换后的表示
- Q 与 K 相乘得到注意力得分矩阵 A
- 对 A 缩放是为了控制其方差,使其更适配 softmax
- Softmax 从概率角度对注意力得分进行归一化
- 最终输出是对 V 的加权求和,权重由注意力得分决定
注意力机制中为什么要除以 ?
在 Transformer 的注意力机制中,计算注意力得分时会执行如下操作:
其中 是输入词向量分别与三个可学习矩阵相乘得到的查询(Query)、键(Key)和值(Value)向量。
我们重点分析为什么要对 除以
,即所谓的“缩放”操作。
一、点积的统计特性分析
1. 假设条件(标准正态分布)
设:
其中:
- 每个
- 每个
- 所有 和
彼此独立
那么注意力得分定义为:
2. 单项乘积的期望与方差
对于每一项 :
-
期望:
-
方差:
由于 ,
有: -
同理
所以:
3. 整体点积的期望与方差
现在来看整体的 :
-
期望:
-
方差:
因此,注意力得分服从以下分布:
二、标准化:除以 的数学意义
我们现在对注意力得分进行标准化:
根据方差的线性变换性质:
同时期望仍为零:
因此,标准化后:
三、Softmax 的影响与数值稳定性
Softmax 函数定义如下:
当数值过大时,指数函数会导致数值溢出或梯度消失。例如:
- 若
,则 softmax 输出集中在接近 1 或 0 的位置,形成“尖峰”
- 若
,softmax 输出更平滑,有助于模型学习合理的权重分配
因此,通过除以 ,我们可以让 softmax 输入处于一个“良好”的区间内,提升训练稳定性。
在注意力机制中,将 QKᵀ 除以
转换为标准正态分布
,从而适配 softmax 操作,提升模型稳定性和表达能力。
计算流程
-
输入 输入为一个形状为
的矩阵(
表示序列长度,
) 表示输入维度 )。
-
线性变换
- 通过权重矩阵
(形状为
)对输入进行线性变换,得到
(Query),形状为
。
- 通过权重矩阵
(形状为
)对输入进行线性变换,得到
(Key),形状为
- 通过权重矩阵
(形状为
(Value),形状为
- 通过权重矩阵
-
计算注意力分数
- 计算
与
的矩阵乘积,得到注意力分数矩阵
,形状为
。
- 对
,得到缩放后的注意力分数。
- 计算
-
归一化 使用 softmax 函数对缩放后的注意力分数进行归一化,得到概率分布矩阵
。
-
计算输出 将归一化后的矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









