







AI搜索在搜索领域的革命性突破
关键词:AI搜索、自然语言处理、语义搜索、向量数据库、大语言模型、搜索算法、知识图谱
摘要:本文深入探讨AI搜索技术如何颠覆传统搜索范式。我们将分析从关键词匹配到语义理解的转变过程,剖析大语言模型在搜索领域的创新应用,并详细介绍向量搜索、多模态搜索等前沿技术。文章包含丰富的技术实现细节、数学模型和实际案例,帮助读者全面理解AI搜索的核心原理和未来发展方向。
文章目录
1. 背景介绍
1.1 目的和范围
本文旨在系统性地阐述AI搜索技术的最新进展,包括其核心技术原理、实现方法以及在各个领域的应用场景。我们将重点关注2018年以来的技术突破,特别是大语言模型与搜索技术的融合。
1.2 预期读者
- 搜索技术工程师和架构师
- 自然语言处理研究人员
- 产品经理和技术决策者
- 对AI搜索感兴趣的技术爱好者
1…3 文档结构概述
文章首先介绍AI搜索的演进历程,然后深入技术细节,包括算法原理和数学模型,接着通过实际案例展示应用效果,最后探讨未来发展趋势。
1.4 术语表
1.4.1 核心术语定义
- 语义搜索:基于查询意图而非字面匹配的搜索方式
- 向量嵌入:将文本转换为高维向量的技术
- RAG(Retrieval-Augmented Generation):检索增强生成技术
- ANN(Approximate Nearest Neighbor):近似最近邻搜索算法
1.4.2 相关概念解释
- 倒排索引:传统搜索引擎使用的索引结构
- BERT:Google开发的预训练语言模型
- Faiss:Facebook开发的向量相似度搜索库
1.4.3 缩略词列表
- NLP:自然语言处理
- LLM:大语言模型
- KNN:K最近邻算法
- BM25:经典的相关性评分算法
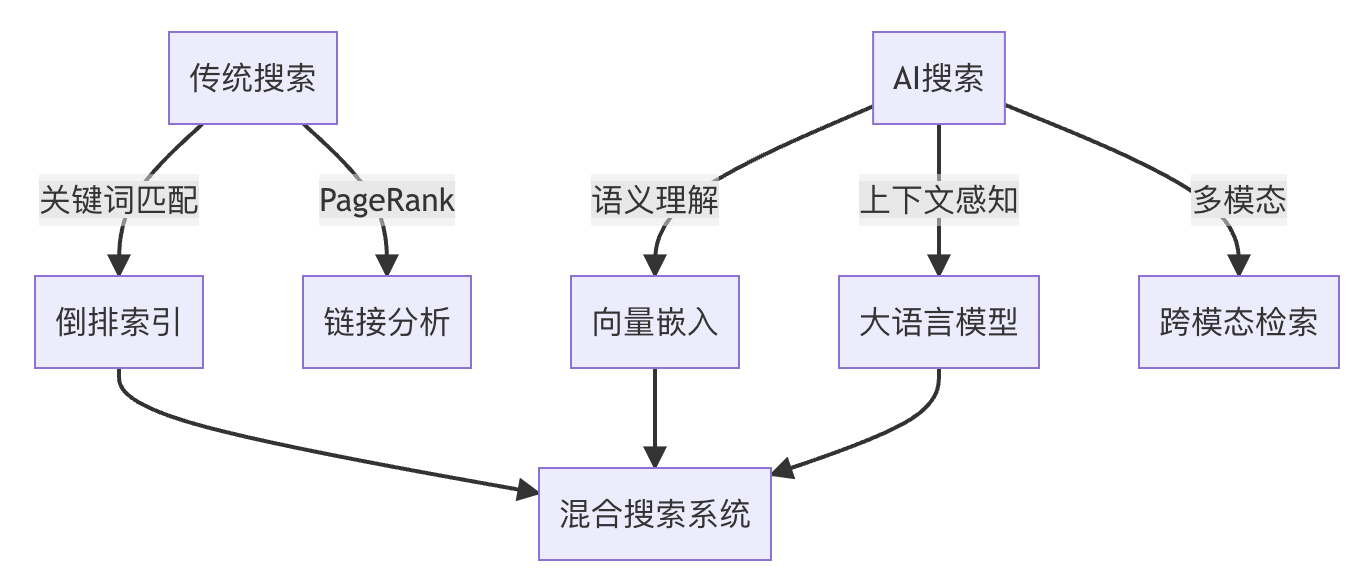
2. 核心概念与联系
现代AI搜索系统通常采用混合架构,结合传统搜索的精确性和AI搜索的语义理解能力。核心组件包括:
- 查询理解层:使用NLP技术解析用户意图
- 检索层:混合使用倒排索引和向量搜索
- 排序层:应用深度学习模型进行结果重排
- 生成层:LLM生成摘要或直接答案
3. 核心算法原理 & 具体操作步骤
3.1 语义向量化
文本嵌入模型将查询和文档映射到同一向量空间:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
query = "如何学习深度学习"
doc = "深度学习入门教程"
query_embedding = model.encode(query)
doc_embedding = model.encode(doc)
similarity = cosine_similarity(query_embedding, doc_embedding)
3.2 混合检索算法
结合BM25和向量相似度的混合评分:
def hybrid_score(bm25_score, vector_score, alpha=0.5):
return alpha * normalize(bm25_score) + (1-alpha) * normalize(vector_score)
3.3 查询扩展
使用LLM生成相关查询:
def query_expansion(original_query):
prompt = f"生成与'{original_query}'相关的5个搜索查询:"
response = llm.generate(prompt)
return parse_expanded_queries(response)
4. 数学模型和公式
4.1 向量相似度计算
余弦相似度公式:
similarity = cos ( θ ) = A ⋅ B ∥ A ∥ ∥ B ∥ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ∑ i = 1 n B i 2 \text{similarity} = \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}} similarity=cos(θ)=∥A∥∥B∥A⋅B=∑i=1nAi2∑i=1nBi2∑i=1nAiBi
4.2 注意力机制
Transformer中的多头注意力计算:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
4.3 近似最近邻搜索
HNSW(Hierarchical Navigable Small World)算法的复杂度:
O ( ( d + d log n ) / ϵ 2 ) O((d + d \log n)/\epsilon^2) O((d+dlogn)/ϵ2)
其中 d d d为维度, n n n为数据点数量, ϵ \epsilon ϵ为近似因子。
5. 项目实战:代码实际案例和详细解释说明
5.1 开发环境搭建
conda create -n ai_search python=3.9
conda activate ai_search
pip install sentence-transformers faiss-cpu pyserini transformers
5.2 完整实现示例
import faiss
from pyserini.search import SimpleSearcher
from sentence_transformers import SentenceTransformer
class HybridSearcher:
def __init__(self, bm25_index, vector_model, faiss_index):
self.bm25_searcher = SimpleSearcher(bm25_index)
self.vector_model = SentenceTransformer(vector_model)
self.faiss_index = faiss.read_index(faiss_index)
def search(self, query, top_k=10, alpha=0.4):
# BM25检索
bm25_hits = self.bm25_searcher.search(query, k=top_k*3)
# 向量检索
query_vec = self.vector_model.encode(query)
D, I = self.faiss_index.search(query_vec.reshape(1,-1), top_k*3)
# 结果融合
combined = self._combine_results(bm25_hits, I[0], D[0], alpha)
return sorted(combined, key=lambda x: x['score'], reverse=True)[:top_k]
5.3 代码解读
- 初始化时加载三种索引:BM25倒排索引、Sentence Transformer模型和Faiss向量索引
- 搜索时并行执行两种检索
- 使用线性加权融合两种结果
- 返回按综合评分排序的最终结果
6. 实际应用场景
6.1 电商搜索
- 解决"描述性查询"问题(如"适合夏天穿的透气衬衫")
- 基于图像和文本的多模态搜索
6.2 企业知识库
- 自然语言查询技术文档
- 跨文档的关联信息检索
6.3 学术搜索
- 按研究概念而非关键词检索论文
- 发现相关但术语不同的研究
7. 工具和资源推荐
7.1 学习资源推荐
7.1.1 书籍推荐
- 《Neural Information Retrieval》 by Cambridge University Press
- 《Search Engines: Information Retrieval in Practice》 by W. Bruce Croft
7.1.2 在线课程
- Stanford CS276: Information Retrieval and Web Search
- DeepLearning.AI的向量搜索专项课程
7.1.3 技术博客和网站
- Pinecone的向量数据库博客
- Weaviate的技术文档
7.2 开发工具框架推荐
7.2.1 核心工具
- Faiss: 高效的向量相似度搜索库
- Sentence-Transformers: 预训练语义模型
- Pyserini: Python中的IR工具包
7.2.2 完整解决方案
- Elasticsearch with vector插件
- Milvus/Pinecone等向量数据库
8. 总结:未来发展趋势与挑战
8.1 趋势
- 多模态搜索的普及
- 实时学习的用户个性化
- 端到端的神经搜索系统
8.2 挑战
- 计算资源需求
- 可解释性问题
- 长尾查询处理
9. 附录:常见问题与解答
Q: AI搜索会完全取代传统搜索吗?
A: 短期内不会,两者将长期共存形成混合系统。传统搜索在精确匹配和结构化数据查询上仍有优势。
Q: 向量搜索的计算成本如何?
A: 通过量化、降维和近似算法,现代系统已能在毫秒级完成百万级向量的搜索。
10. 扩展阅读 & 参考资料
- Google Research的"REPLUG: Retrieval-Augmented Black-Box Language Models"
- Facebook AI的"Embedding-based Retrieval in Facebook Search"
- ACM SIGIR近三年的最佳论文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









