






在大数据处理领域,Hive 作为基于 Hadoop 的数据仓库工具,凭借其强大的 SQL 查询能力和可扩展性备受青睐。但随着数据量的增长,性能问题逐渐凸显。今天,我就手把手教你从七个关键方向优化 Hive,让你的查询效率起飞!
一、开启本地模式:小数据的极速通道
当你的数据量较小时,开启 Hive 本地模式能显著提升执行效率。本地模式会将任务在本地文件系统中执行,避免了 Hadoop 集群的资源开销和网络传输延迟。
配置方法
在hive-site.xml文件中添加或修改以下配置:
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>开启本地模式</description>
</property>
<property>
<name>hive.exec.mode.local.auto.inputbytes.max</name>
<value>52428800</value> <!-- 输入数据大小阈值,默认50MB -->
<description>设置本地模式下输入数据的最大大小</description>
</property>当输入数据量小于hive.exec.mode.local.auto.inputbytes.max指定的值时,Hive 就会自动启用本地模式。
二、explain 解析 SQL 语句:摸清查询执行计划
explain命令是 Hive 性能调优的 “透视镜”,它能让你清晰了解 SQL 语句的执行计划,帮助你了解SQL的执行顺序并发现潜在的性能瓶颈,从而动态调整SQL语句。
使用方法
在 SQL 语句前加上explain关键字即可,例如:
explain select count(*) from your_table;执行后,Hive 会输出该 SQL 语句的执行计划,包括表的扫描方式、JOIN 类型、排序操作等详细信息。
以下是MySQL当中的explain效果图
执行计划分析
通过分析执行计划,我们可以判断是否存在全表扫描、不合理的 JOIN 顺序等问题,从而针对性地优化 SQL 语句。其代表含义如下:
1)stage 相当于一个job,一个stage可以是limit、也可以是一个子查询、也可以是group by等。
2)hive默认一次只执行一个stage,但是如果stage之间没有相互依赖,将可以并行执行。
3)任务越复杂,hql代码越复杂,stage越多,运行的时间一般越长。
三、修改 Fetch:减少不必要的 MapReduce 任务
Hive 的 Fetch 抓取机制允许在某些简单查询场景下,直接从 HDFS 读取数据返回结果,避免启动 MapReduce 任务,从而提升查询效率。
配置修改
在hive-site.xml中配置hive.fetch.task.conversion参数:
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>开启更多的Fetch优化</description>
</property>more模式会启用更多的 Fetch 优化,例如针对SELECT、WHERE、LIMIT等简单查询,直接返回结果,无需启动 MapReduce。
一句话总结便是修改hive中fetch操作为more,减少不必要的mr操作。
四、开启严格模式:规避危险操作
Hive 的严格模式能限制一些可能导致全表扫描或数据倾斜的危险操作,降低性能风险和资源浪费,提高了安全性。
开启方式
在hive-site.xml中设置:
<property>
<name>hive.mapred.mode</name>
<value>strict</value>
<description>开启严格模式</description>
</property>起主要作用是防止写的烂sql影响集群,比如 select * from emp;
开启严格模式以后,以下情况多报SQL错误!
1)分区表不使用分区过滤
select * from emp where day='20231001'
2) 使用order by没有limit过滤
3) 笛卡尔积不允许出现 select * from emp,dept ;
五、开启 JVM 重用:减少资源开销
在 Hive 执行 MapReduce 任务时,默认情况下,一个JVM最多可以执行1个task,但是这样的话,JVM效率就比较低。开启 JVM 重用可以避免每个任务都重新启动 JVM,从而减少资源初始化开销,提升整体性能。
配置步骤
在mapred-site.xml中添加配置:
<property>
<name>mapreduce.job.jvm.numtasks</name>
<value>10</value> <!-- 一个JVM可执行的任务数,根据实际情况调整 -->
<description>启用JVM重用</description>
</property>六、分区分桶:加速数据查询
分区分桶是 Hive 优化数据查询的重要手段。分区根据数据的某个维度(如时间、地域)将数据划分到不同目录,桶则是在分区的基础上进一步细分,通过哈希函数将数据打散到不同文件中。
分区表创建
CREATE TABLE your_table (
id INT,
name STRING
)
PARTITIONED BY (date STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';分桶表创建
CREATE TABLE your_table (
id INT,
name STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';通过分区分桶,查询效率得到了显著提升。
七、压缩:减少存储和传输开销
数据压缩能有效减少数据的存储空间和网络传输量,从而提升 Hive 的性能。
常见的压缩类型如下:
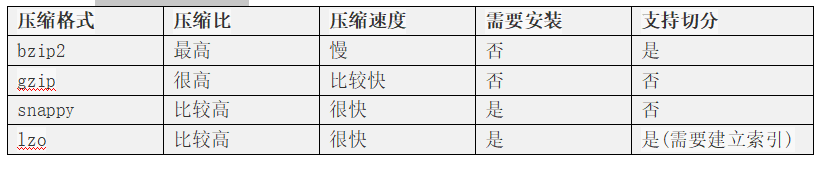
对应的压缩编码器为:
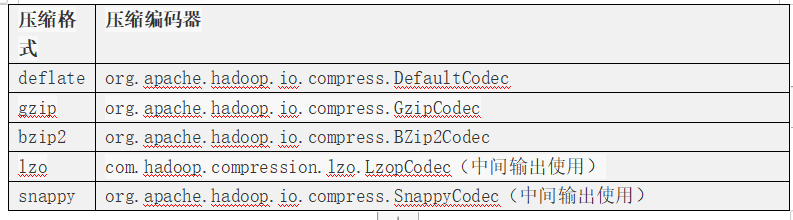
配置压缩
在hive-site.xml中配置:
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
<description>启用输出压缩</description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>设置压缩编码</description>
</property>选择合适的压缩格式需要根据实际场景权衡压缩比和压缩 / 解压缩速度。
以上就是 Hive 性能优化的七大核心技巧,每一项都经过大量实践验证。合理运用这些方法,能让你的 Hive 查询性能实现质的飞跃!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









