






一:MySQL的数据类型(常见)
1.数据值类型
| 类型 | 大小 | 说明 | |
|---|---|---|---|
| TINYINT | 1byte |
| |
| INT | 4byte |
| |
| BIGINT | 8byte |
| |
| DECIMAL | 动态 |
|
2.字符串类型
| 类型 | 说明 | |
|---|---|---|
| CHAR |
| |
VARCHAR |
| |
| TEXT |
| |
| BINARY |
| |
| VARBINARY |
| |
| BLOB |
|
3.日期类型
| 类型 | 大小 | 说明 | ||
|---|---|---|---|---|
| DATETIME | 8bytes |
| ||
| DATE | 3bytes |
|
二:MySQL表的基本操作
在MySQL中对表的操作之前需要使用use + 库名 的语句来对应该库中的相应表


2.1 查看所有表
语法:
show tables;
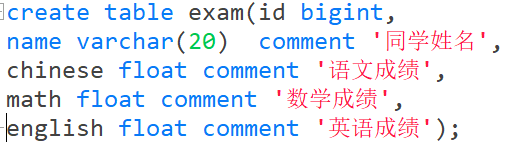
2.2 创建表
语法:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
field datatype [约束] [comment '注解内容']
[, field datatype [约束] [comment '注解内容']] ...
) [engine 存储引擎] [character set 字符集] [collate 排序规则];
注意事项:
1.field:列名
2.datatype:数据类型
3.comment:对列的描述或说明
4. engine:存储引擎,不指定则使⽤默认存储引擎
5. character set:字符集,不指定则使⽤默认字符集
6. collate:排序规则,不指定则使⽤默认排序规则
7.TEMPORARY: 表⽰创建的是⼀个临时表
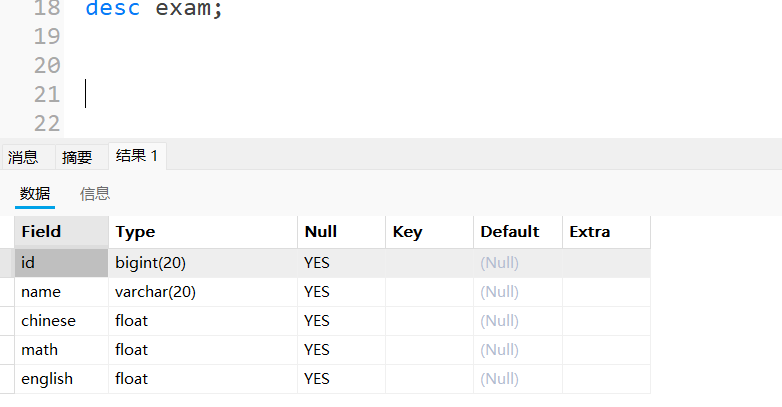
2.3查看表的结构
语法:
desc 表名;
实例:
2.4修改表
语法:
ALTER TABLE tbl_name [alter_option [, alter_option] ...];
alter_option: {
table_options
| ADD [COLUMN] col_name column_definition [FIRST | AFTER col_name]
| MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name]
| DROP [COLUMN] col_name
| RENAME COLUMN old_col_name TO new_col_name
| RENAME [TO | AS] new_tbl_name
1.tbl_name:要修改的表名
2.ADD:向表中添加列
3.MODIFY:修改表中现有的列
4.DROP:删除表中现有的列
5.RENAME COLUMN:重命名表中现有的列
6.RENAME [TO | AS] new_tbl_name:重命名当前的表
示例:
1.向表中添加一列:
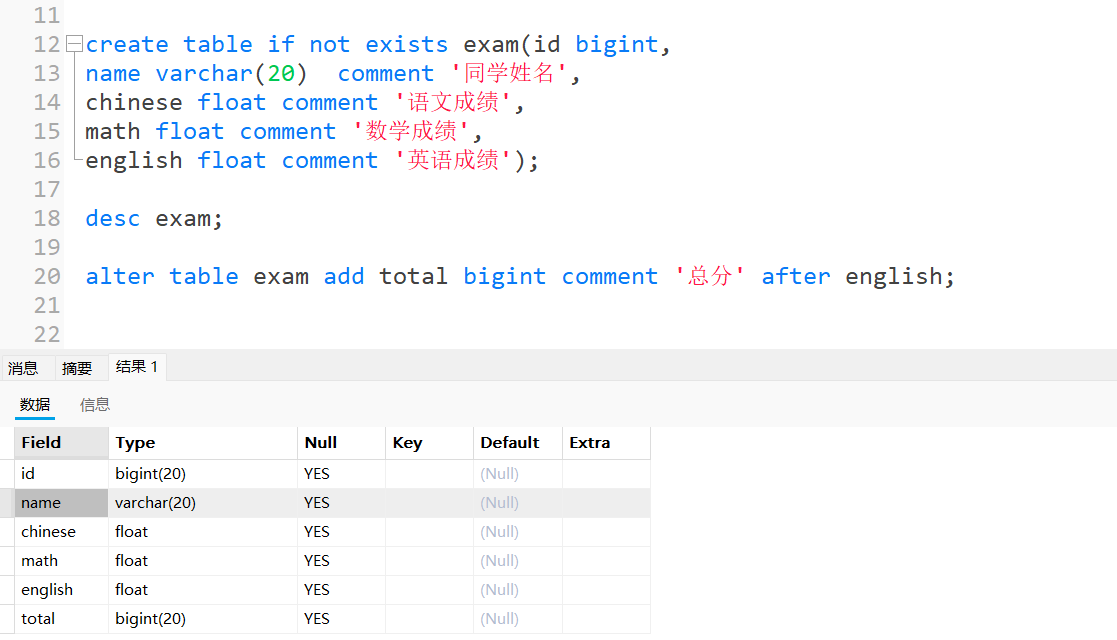
alter table exam add total bigint comment '总分' after english;
解释:向english列后面添加一列total。
2.修改某列的长度:
alter table exam modify name varchar(30);
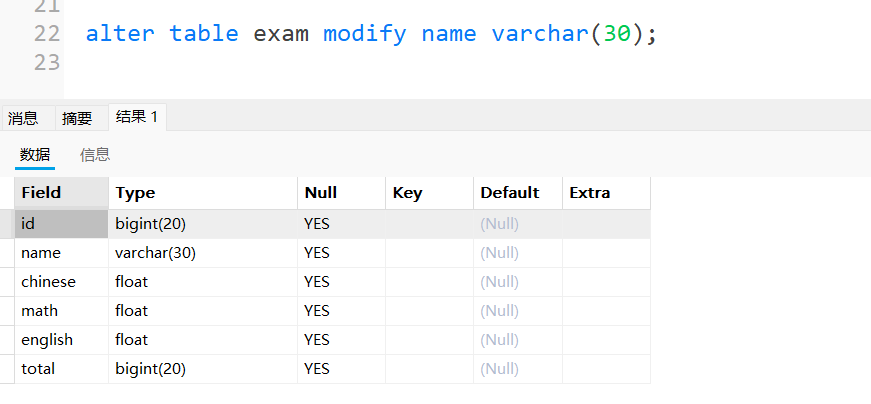
解释:name那一列varchar的值变为30.
3.重命名某列:
alter table exam rename column total to overall;
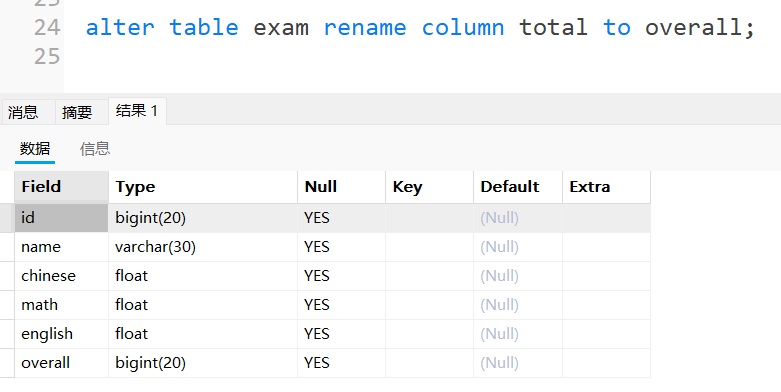
解释:将total列的列名改为overall
4.删除某列:
alter table exam drop overall;
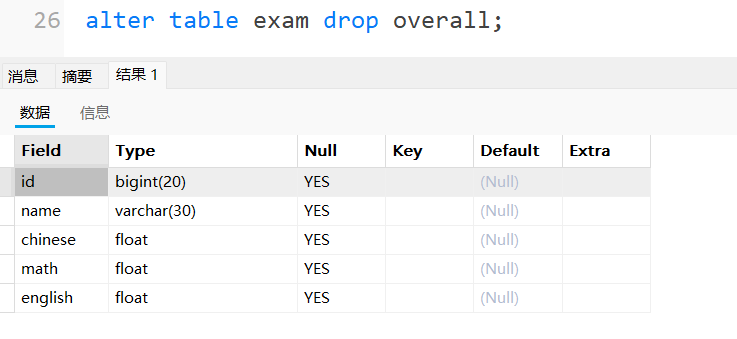
解释:overall列被删除
5.修改表名:
alter table exam rename Grades;
解释:将表名改为Grades。
2.4删除表
语法:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
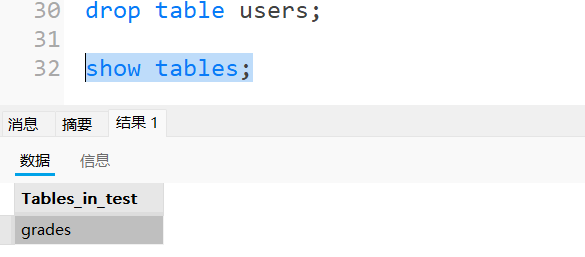
解释:删除了表users。
三:增删改查操作
1.insert增加
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES
(value_list) [, (value_list)] ...
value_list: value, [, value] ...
1 2 3 4 5
3.1.1单行数据全列插入:
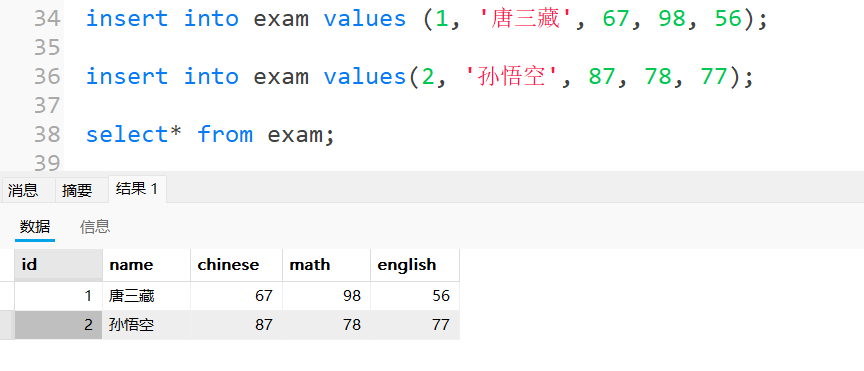 3.1.2单行数据指定列插入:
3.1.2单行数据指定列插入:
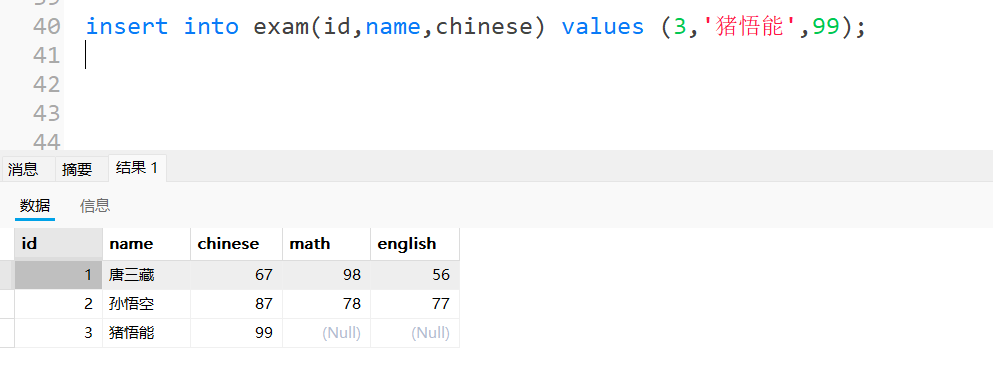
3.1.3多⾏数据指定列插⼊:
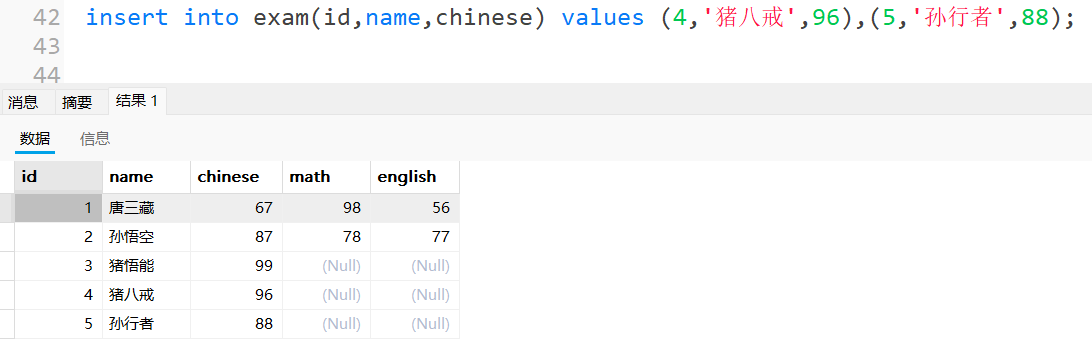
2.select查询
3.2.1全列查询:
select* from 表名
3.2.2指定列查询:
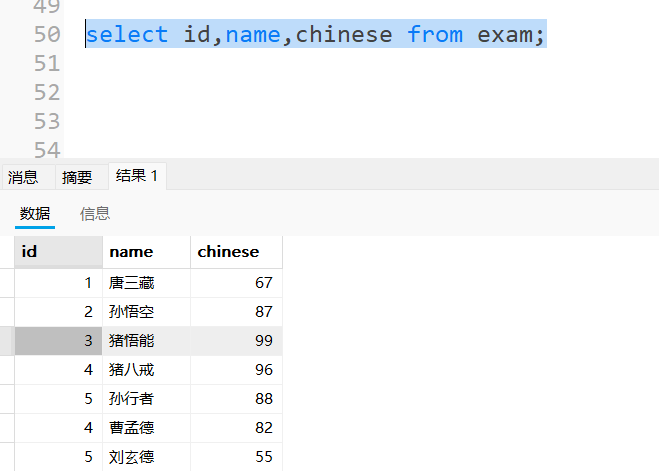
3.2.3查询字段为表达式:
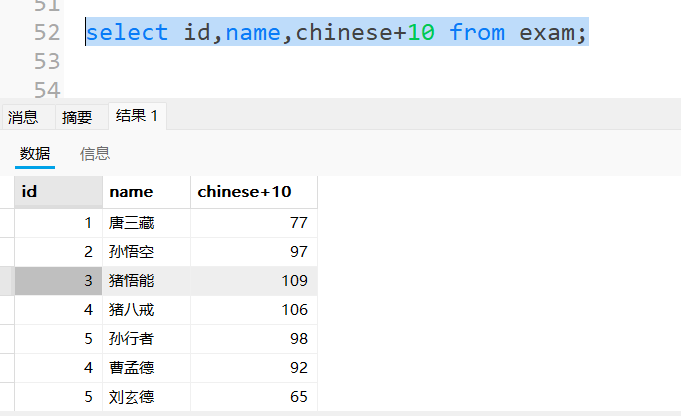
1.计算所有人的语文成绩都加10
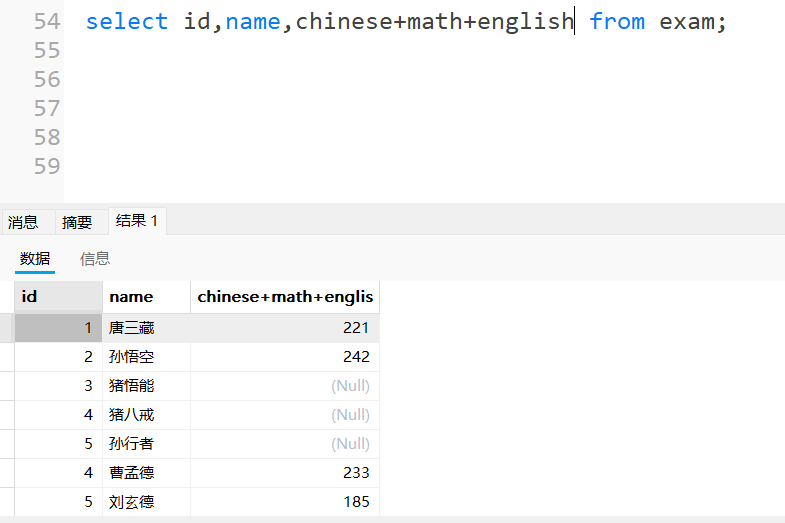
2.计算总成绩
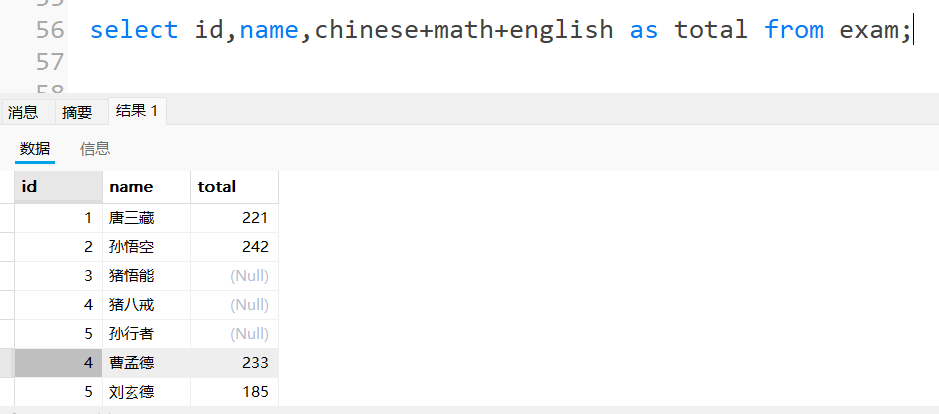
3.2.4为查询结果指定别名
语法:
SELECT column [AS] alias_name [, ...] FROM table_name;
注释:AS可以省略
3.2.5结果去重查询
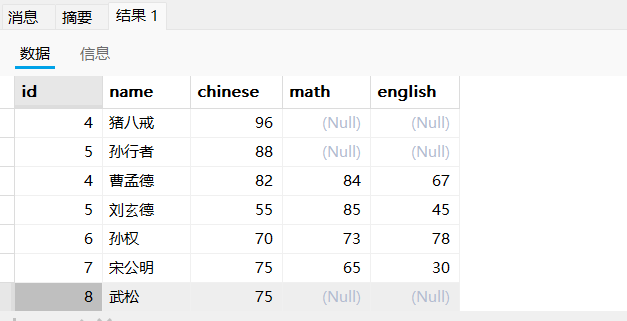
可以观察到id为7和8的语文成绩都为75,下面我们可以为结果进行一个去重处理,即利用distinct。
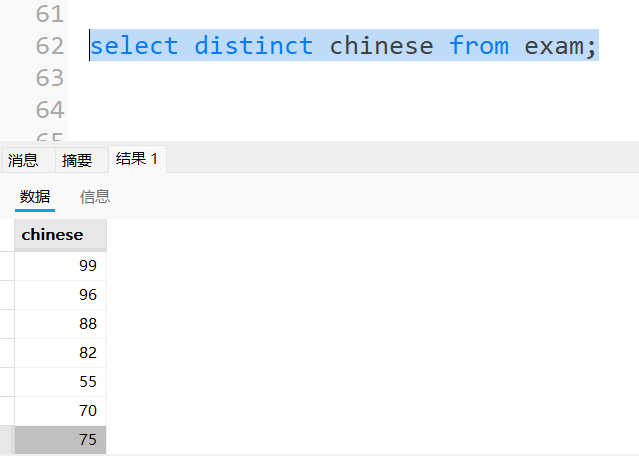
可以观察到75只有一个了。
使⽤DISCTINCT去重时,只有查询列表中所有列的值都相同才会判定为重复
注意:
• 查询时不加限制条件会返回表中所有结果,如果表中的数据量过⼤,会把服务器的资源消耗殆尽
• 在⽣产环境不要使不加限制条件的查询
3.2.6条件查询
在介绍条件查询之前我们先来认识一下MySQL中的运算符
比较运算符:
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | ⼤于,⼤于等于,⼩于,⼩于等于 |
| = | 等于,对于NULL的⽐较不安全,⽐如NULL = NULL结果还是NULL |
| <=> | 等于,对于NULL的⽐较j是安全的,⽐如NULL <=> NULL结果是TRUE(1) |
| !=,<> | 不等于 |
| value BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果a0 <= value <= a1,返回TRUE或1,NOT BETWEEN则取 反 |
| value IN (option, ...) | 如果value 在optoin列表中,则返回TRUE(1),NOT IN则取反 |
| IS NULL | 是null |
| IS NOT NULL | 不是null |
| LIKE | 模糊匹配,% 表⽰任意多个(包括0个)字符;_ 表⽰任意⼀个字符,NOT LIKE则取反 |
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意⼀个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
条件查询的语法:
SELECT
select_expr [, select_expr] ... [FROM table_references]
WHERE where_condition
1.基本查询
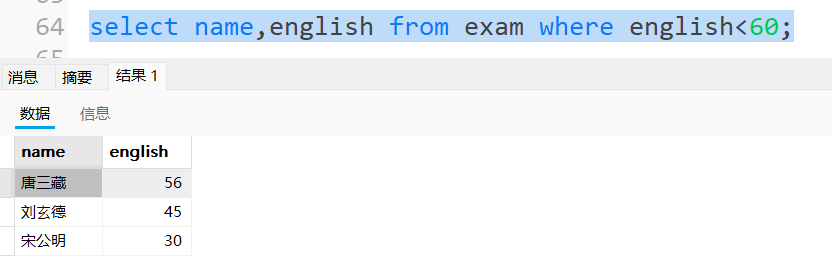
查询英语不及格的同学及英语成绩 ( < 60 )
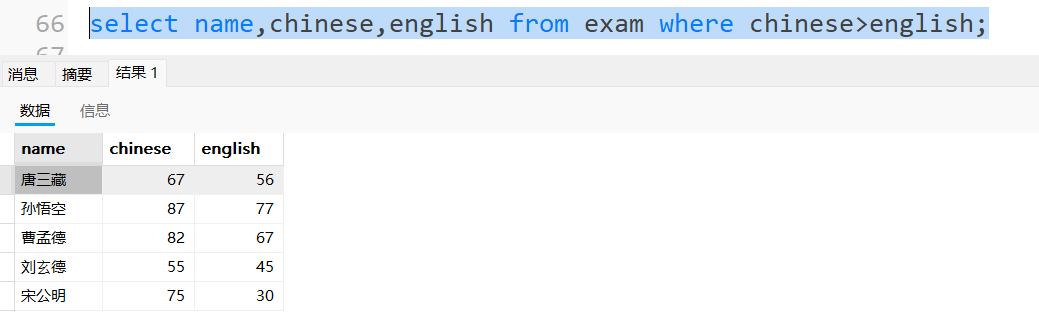
查询语文成绩高于英语成绩的同学
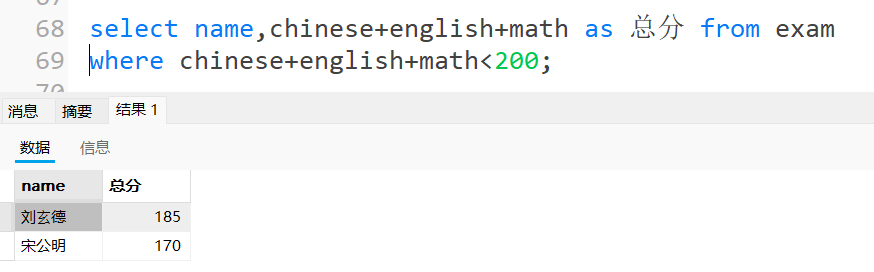
总分在 200 分以下的同学
2.AND和OR
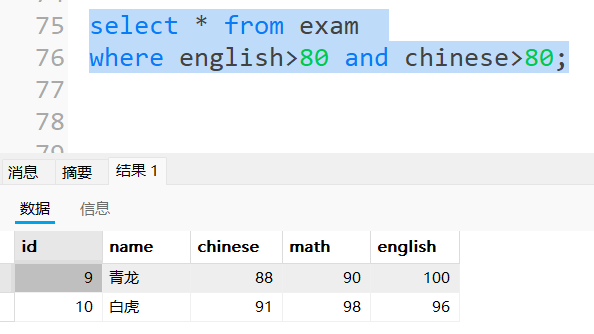
查询语文成绩大于80分且英语成绩大于80分的同学
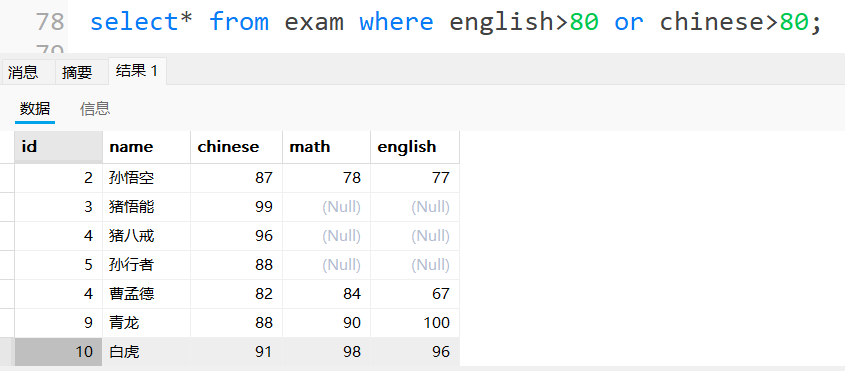
查询语⽂成绩⼤于80分或英语成绩⼤于80分的同学
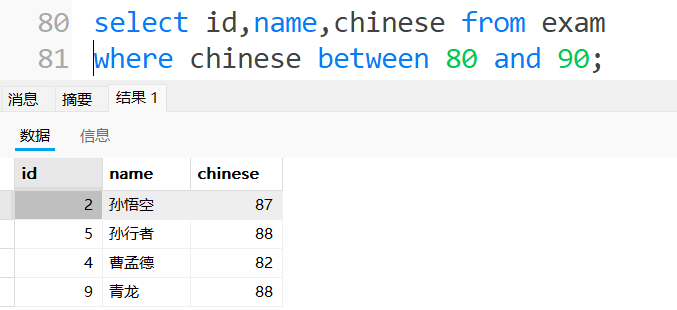
3.范围查询
语⽂成绩在 [80, 90] 分的同学及语⽂成绩
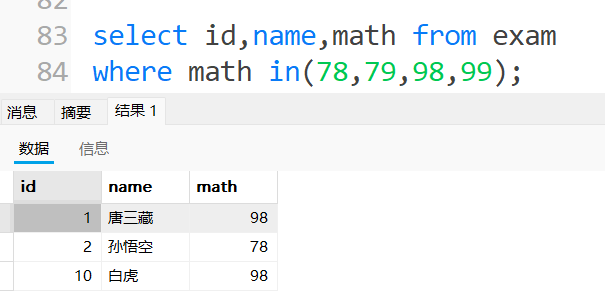
数学成绩是 78 或者 79 或者 98 或者 99 分的同学及数学成绩
4.模糊查询
查询所有姓孙的同学
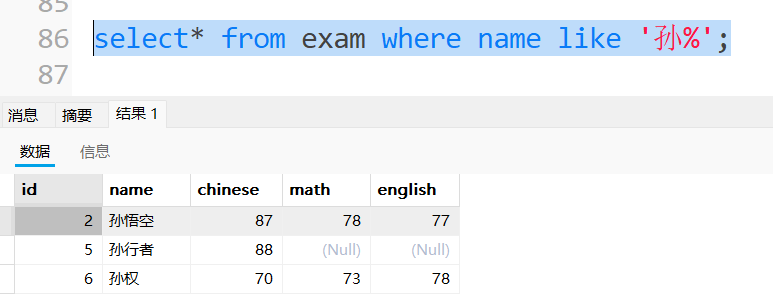
查询姓孙且姓名共有两个字同学
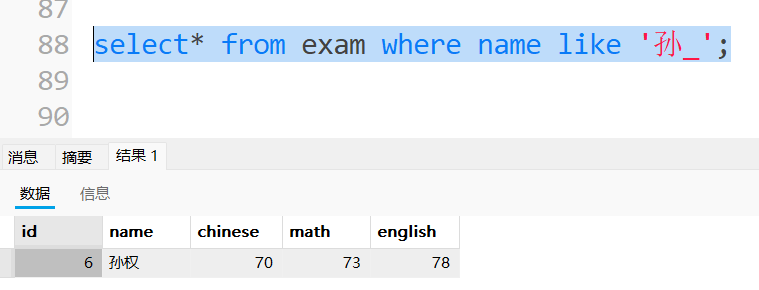
5.NULL的查询
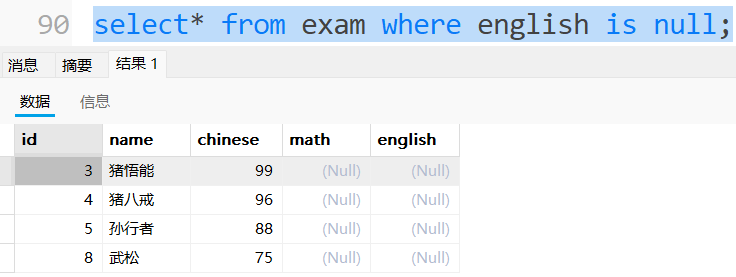
查询英语成绩为NULL的记录
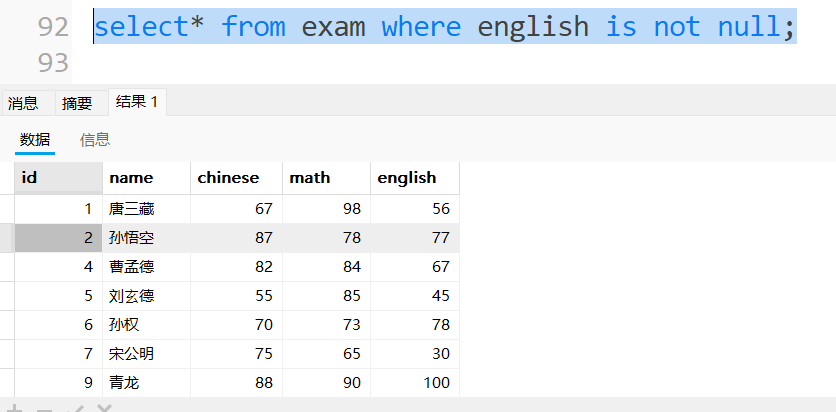
查询英语成绩不为NULL的记录
注意:
1.WHERE条件中可以使⽤表达式,但不能使⽤别名
2.AND的优先级⾼于OR,在同时使⽤时,建议使⽤⼩括号()包裹优先执⾏的部分
3.过滤NULL时不要使⽤等于号(=)与不等于号(!= , <>)
4.NULL与任何值运算结果都为NULL
3.2.7Order by 排序
语法:
-- ASC 为升序(从⼩到⼤)
-- DESC 为降序(从⼤到⼩)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY {col_name | expr } [ASC |
DESC], ... ;
按数学成绩从低到⾼排序(升序)
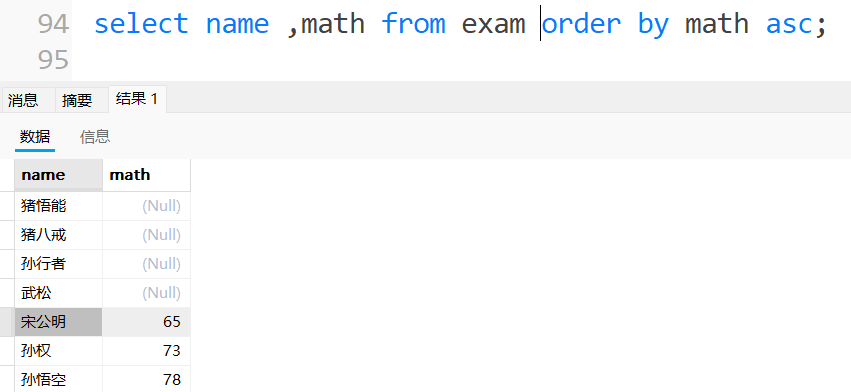
把结果为null的排除
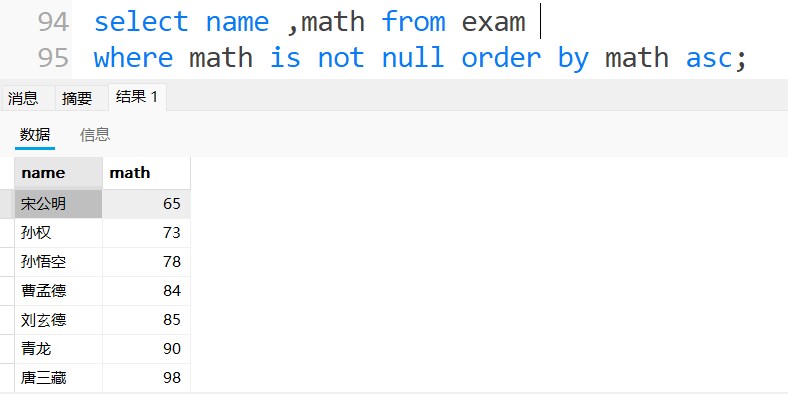
注意:
• 查询中没有ORDER BY ⼦句,返回的顺序是未定义的,永远不要依赖这个顺序
• ORDER BY ⼦句中可以使⽤列的别名进⾏排序
• NULL 进⾏排序时,视为⽐任何值都⼩,升序出现在最上⾯,降序出现在最下⾯
3.2.8分页查询
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num;
-- 从 start 开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT start, num;
-- 从 start 开始,筛选 num 条结果,⽐第⼆种⽤法更明确,建议使⽤
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num OFFSET start;
查询第⼀页数据
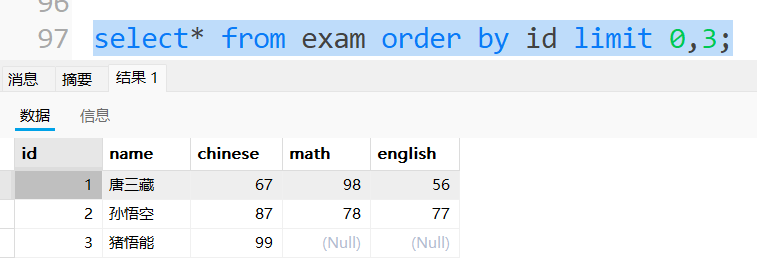
3.update修改
语法:
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET assignment [, assignment] ...
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
将孙悟空同学的数学成绩变更为 80 分
先查询:
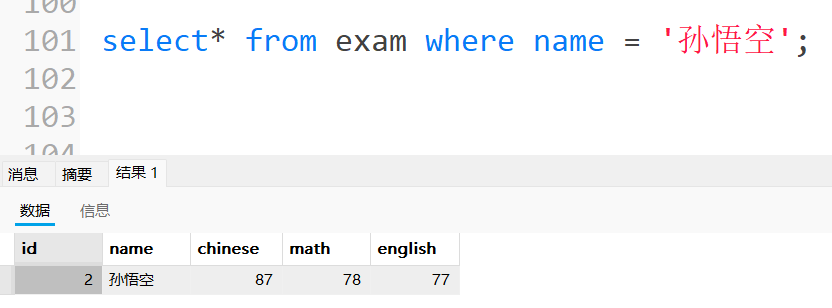
修改后:
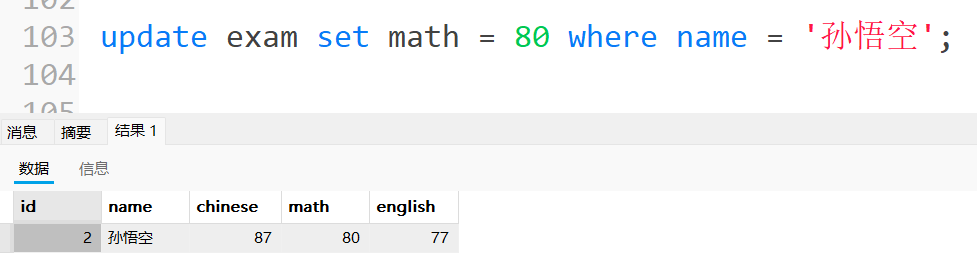
Update 注意事项:
• 以原值的基础上做变更时,不能使⽤math += 30这样的语法
• 不加where条件时,会导致全表数据被列新,谨慎操作
4.Delete 删除
语法:
DELETE FROM tbl_name [WHERE where_condition] [ORDER BY ...] [LIMIT row_count]
删除孙悟空同学的考试成绩
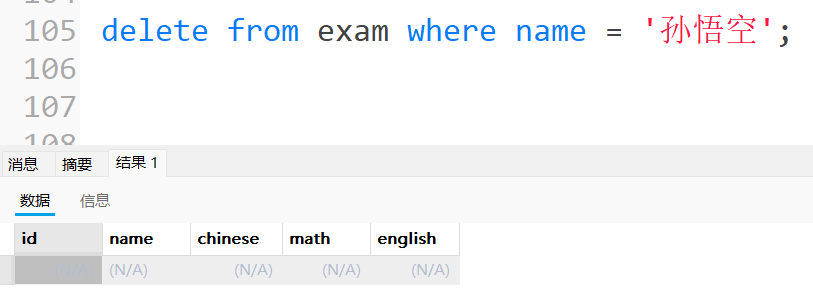
执⾏Delete时不加条件会删除整张表的数据,谨慎操作
四:聚合函数
1.常用函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最⼤值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最⼩值,不是数字没有意义 |
查询到数据的总数
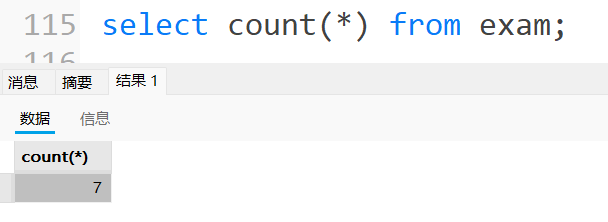
4.1.1 COUNT函数的使用
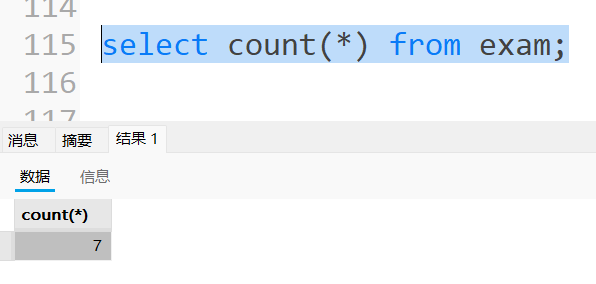
统计exam表中有多少记录
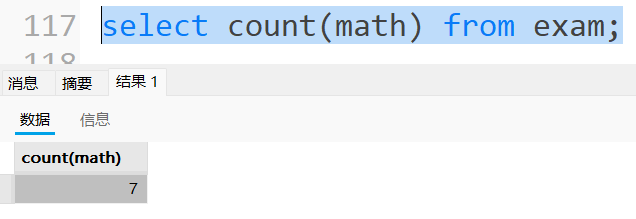
统计有多少学⽣参加数学考试
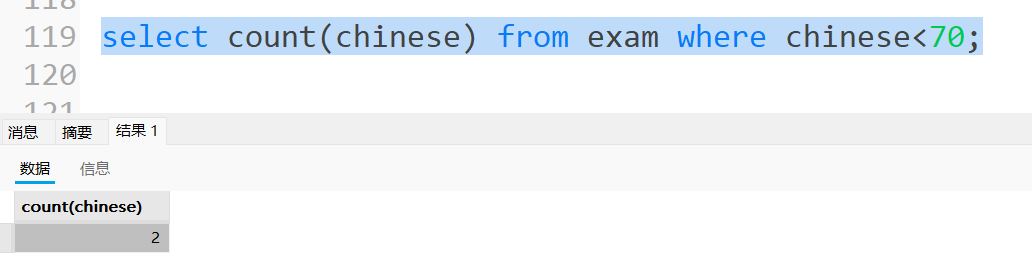
统计语⽂成绩⼩于70分的学⽣个数
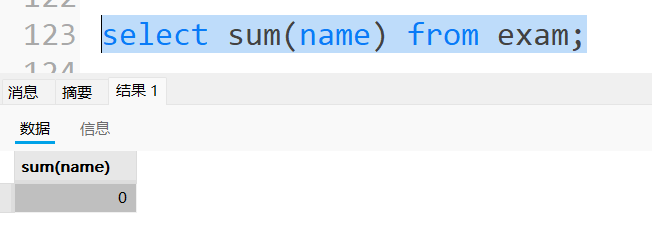
4.1.2 SUM函数的使用
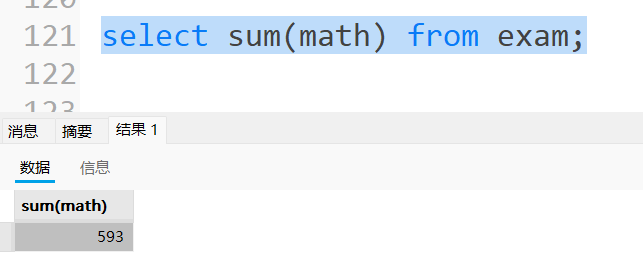
统计所有学⽣数学成绩总分
不能统计⾮数值的列
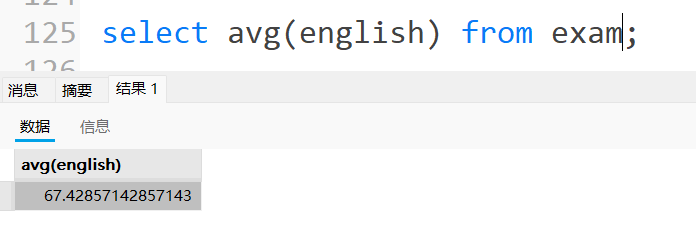
4.1.3 AVG函数的使用
统计英语成绩的平均分
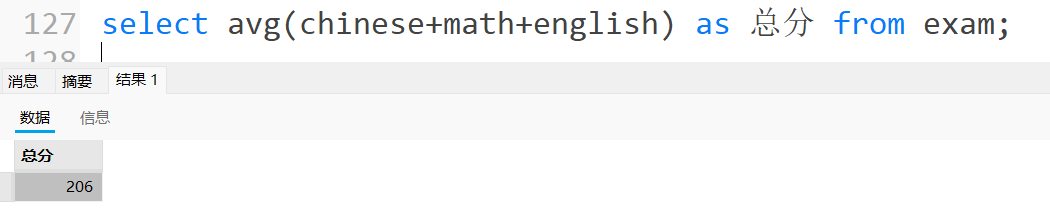
统计平均总分
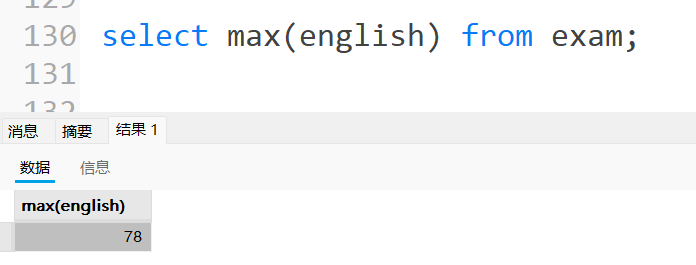
4.1.4 MAX
4.1.5 MIN
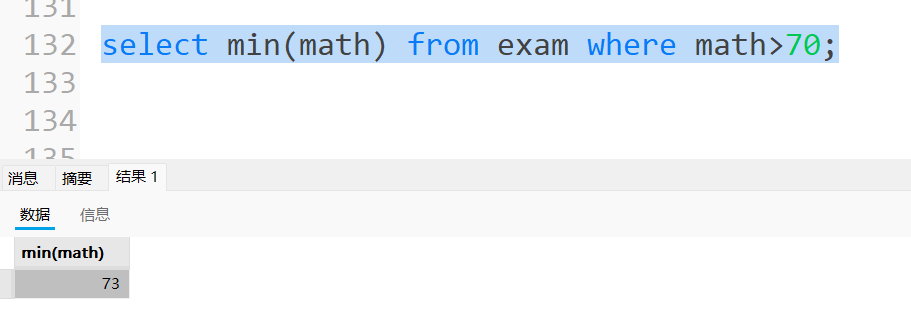
查询 > 70 分以上的数学最低分
2.Group by 分组查询
GROUP BY ⼦句的作⽤是通过⼀定的规则将⼀个数据集划分成若⼲个⼩的分组,然后针对若⼲个分组进⾏数据处理,⽐如使⽤聚合函数对分组进⾏统计。
语法:
SELECT {col_name | expr} ,... ,aggregate_function (aggregate_expr)
FROM table_references
GROUP BY {col_name | expr}, ...
[HAVING where_condition]
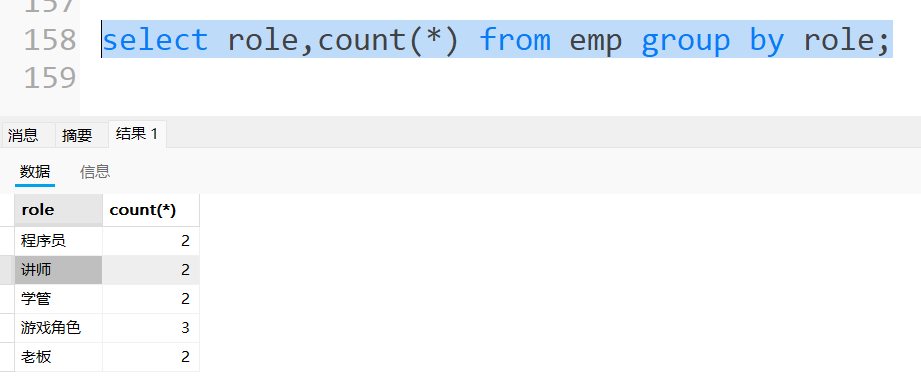
统计每个角色的人数
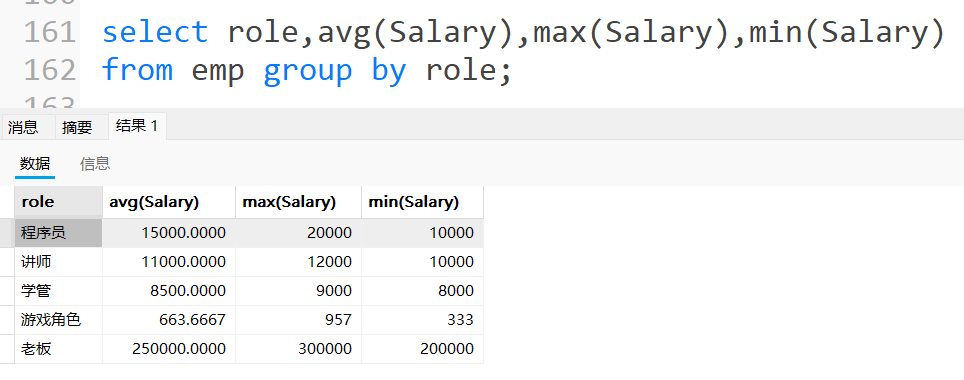
统计每个⻆⾊的平均⼯资,最⾼⼯资,最低⼯资
3. Having 子句
使⽤GROUP BY 对结果进⾏分组处理之后,对分组的结果进⾏过滤时,不能使⽤ WHERE ⼦句,⽽要使用HAVING子句
显⽰平均⼯资低于1500的⻆⾊和它的平均⼯资
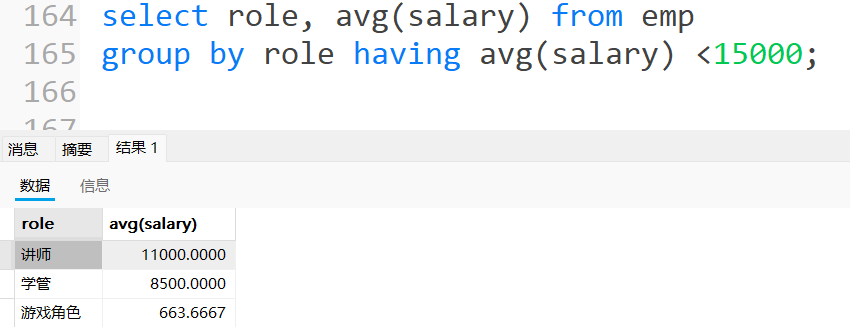
Having 与Where 的区别
• Having ⽤于对分组结果的条件过滤
• Where ⽤于对表中真实数据的条件过滤
4.内置函数
4.4.1 日期函数
| 函数 | 说明 |
|---|---|
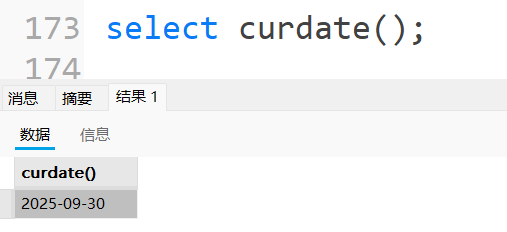
| CURDATE() | 返回当前⽇期,同义词 CURRENT_DATE , CURRENT_DATE() |
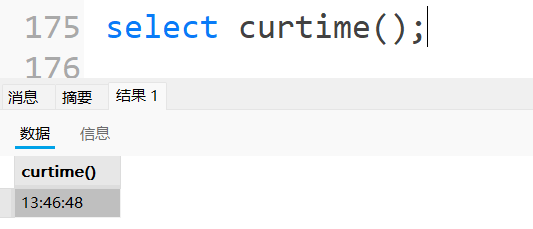
| CURTIME() | 返回当前时间,同义词 CURRENT_TIME , CURRENT_TIME([fsp]) |
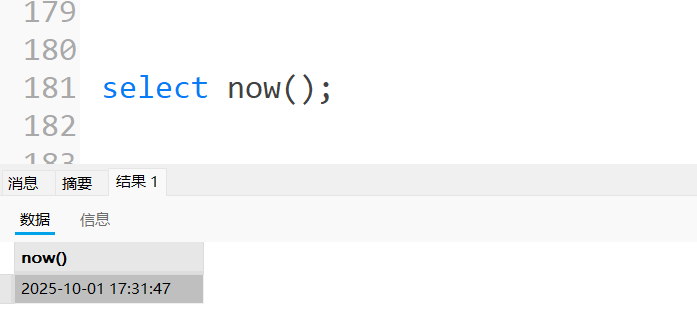
| NOW() | 返回当前⽇期和时间,同义语 CURRENT_TIMESTAMP , |
| DATE(data) | 提取date或datetime表达式的⽇期部分 |
| ADDDATE(date,INTERVAL expr unit) | 向⽇期值添加时间值(间隔),同义词 DATE_ADD() |
| SUBDATE(date,INTERVAL expr unit) | 向⽇期值减去时间值(间隔),同义词 DATE_SUB() |
| DATEDIFF(expr1,expr2) | 两个⽇期的差,以天为单位,expr1 - expr2 |
获取当前日期
获取当前时间
获取当前⽇期和时间
4.4.2字符串函数
|
函数 | 说明 |
|---|---|
| CHAR_LENGTH(str) | 返回给定字符串的⻓度,同义词 CHARACTER_LENGTH() |
| LENGTH(str) | 返回给定字符串的字节数,与当前使⽤的字符编码集有关 |
| CONCAT(str1,str2,...) | 返回拼接后的字符串 |
| CONCAT_WS(separator,str1,s | 返回拼接后带分隔符的字符串 |
| LCASE(str) | 将给定字符串转换成⼩写,同义词 LOWER() |
| UCASE(str) | 将给定字符串转换成⼤写,同义词 UPPER() |
| HEX(str), HEX(N) | 对于字符串参数str, HEX()返回str的⼗六进制字符串表⽰形式,对于数字参数N, HEX()返回⼀个⼗六进制字符串表⽰形式 |
| INSTR(str,substr) | 返回substring第⼀次出现的索引 |
| INSERT(str,pos,len,newstr | 在指定位置插⼊⼦字符串,最多不超过指定的字符数 |
| SUBSTR(str,pos) | 返回指定的⼦字符串,同义词 SUBSTRING(str,pos) ,SUBSTRING(str FROM pos FOR len) |
| REPLACE(str,from_str,to_str) | 把字符串str中所有的from_str替换为to_str,区分⼤⼩写 |
| STRCMP(expr1,expr2) | 逐个字符⽐较两个字符串,返回 -1, 0 , 1 |
| LEFT(str,len) ,RIGHT(str,len) | 返回字符串str中最左/最右边的len个字符 |
| LTRIM(str) , RTRIM(str) ,TRIM(str) | 删除给定字符串的前导、末尾、前导和末尾的空格 |
| TRIM([{LEADING | TRAILING| BOTH } [remstr] FROM] | 删除给定符串的前导、末尾或前导和末尾的指定字符串 |
4.4.3数学函数
| 函数 | 说明 |
|---|---|
| ABS(X) | 返回X的绝对值 |
| CEIL(X) | 返回不⼩于X的最⼩整数值,同义词是 CEILING(X) |
| FLOOR(X) | 返回不⼤于X的最⼤整数值 |
| CONV(N,from_base,to_base) | 不同进制之间的转换 |
| FORMAT(X,D) | 将数字X格式化为“#,###,###”的格式。##',四舍五⼊到⼩数点后D位,并以字符串形式返回 |
| RAND([N]) | 返回⼀个随机浮点值,取值范围 [0.0, 1.0) |
| ROUND(X), ROUND(X,D) | 将参数X舍⼊到⼩数点后D位 |
| CRC32(expr) | 计算指定字符串的循环冗余校验值并返回⼀个32位⽆符号整数 |

















 8067
8067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









