






日常生活中,不管是办签证、报名考试还是入职提交材料,我们总少不了要用到证件照。
可不同的场合对照片的尺寸、背景颜色甚至着装要求都不一样,自己拍照不仅麻烦,还常常不符合规范。
之前我也为这个事头疼,直到遇到一款真正好用、无使用次数限制的证件照生成工具——HivisionIDPhotos,亲测实用,操作简单,效果也很清晰。
它属于绿色软件,不需要安装,双击就能运行。
打开之后保持后台不关闭,在浏览器输入 127.0.0.1:7860,就可以开始使用了。
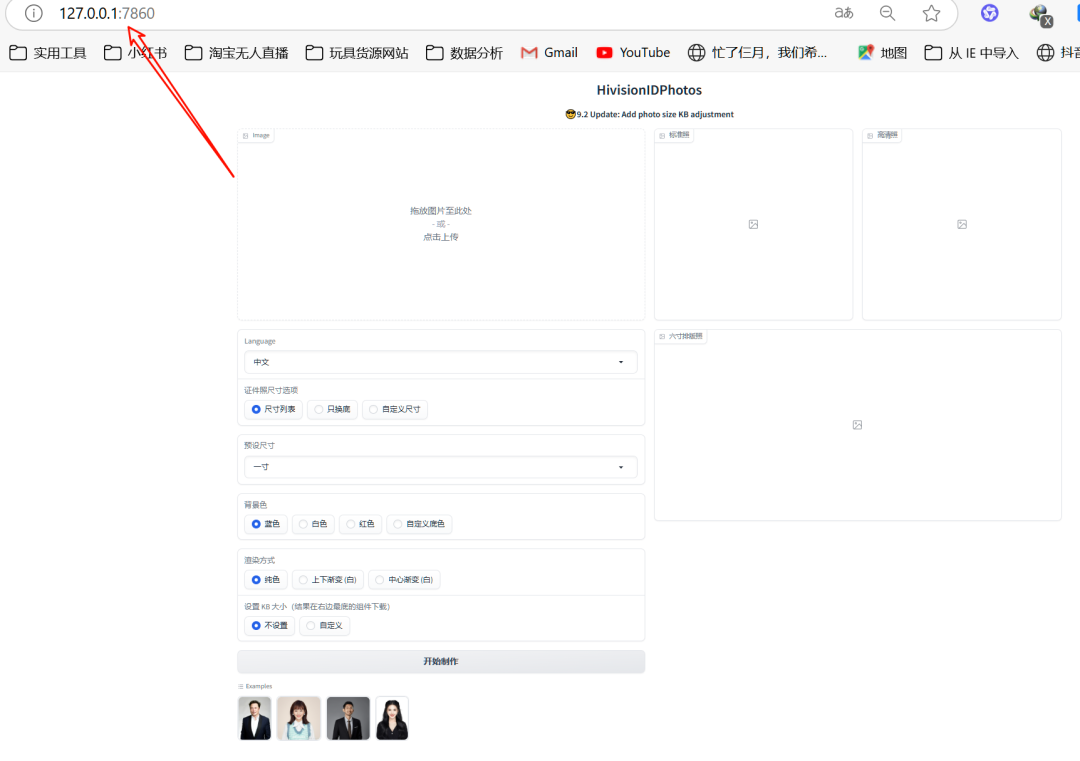
使用方法非常直观:把手机或相机拍的照片拖进左侧区域,选择你需要的证件照尺寸。
再设置背景颜色(比如常用的白色、蓝色、红色),选择渲染方式和打印尺寸,点击“开始制作”,几秒钟就能处理好。
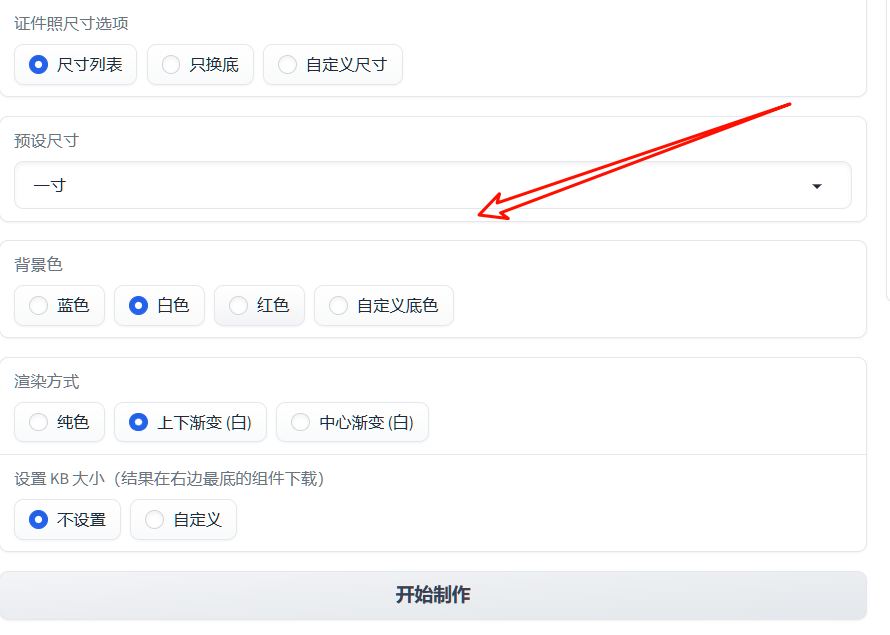
生成的照片清晰度高,右上角有下载按钮,保存之后无论是打印还是线上提交,效果都很到位。
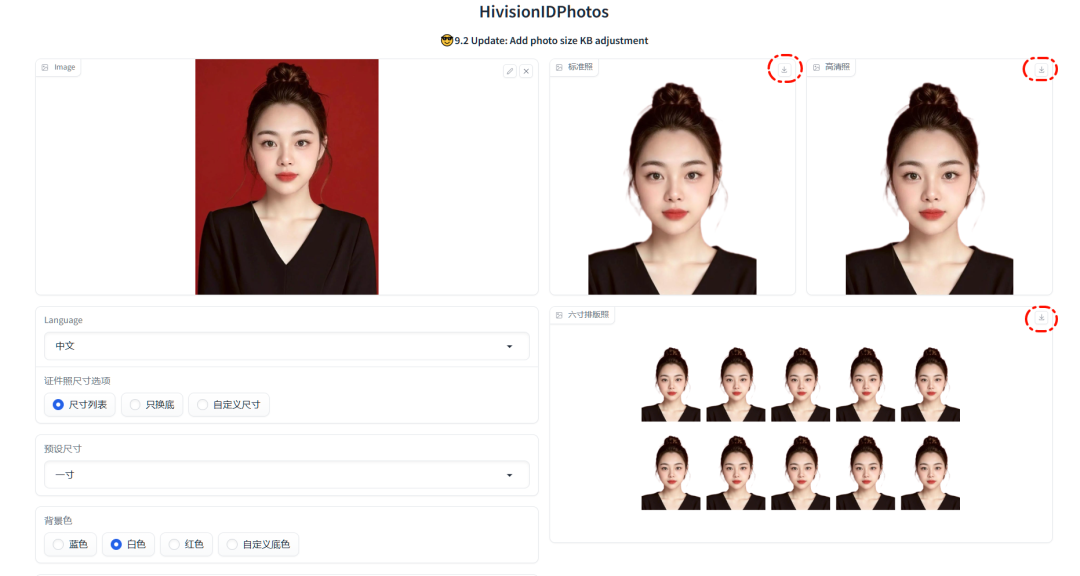
我自己试过切换不同尺寸、换背景、换照片,响应很快,全程没有广告,也不加水印,确实很良心。
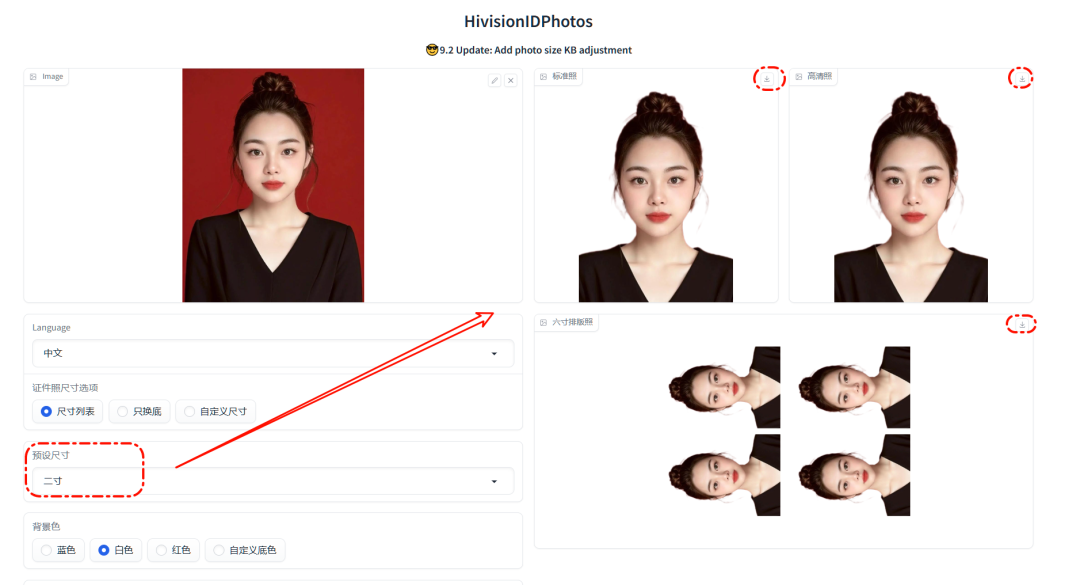
这是直接导出的一张二寸照效果,大家可以参考:

如果你平时也需要自己处理证件照,或者不想总跑照相馆,可以试试这个工具,亲测好用。
另外,最近我也在自学C4D设计,发现了一套很实用的功能讲解视频——《C4D R20新增功能:平滑滤镜和调整外形滤镜》,里面详细演示了如何借助新滤镜优化模型细节和外观调整,对做三维设计或者视频包装的同学来说特别有帮助。
如果你也需要,我通过夸克网盘分享给你。复制整段内容后打开夸克APP即可保存观看。
C4D R20新增滤镜:https://pan.quark.cn/s/0911cb11132e
工具和教程都准备好了,愿大家处理图片、提升技能之路更顺畅。
免责声明:本工具及资源仅供个人学习与交流使用,请勿用于商业行为。请在下载后24小时内删除,建议购买官方版本支持开发者。

















 3097
3097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









