







linux目录及文件操作
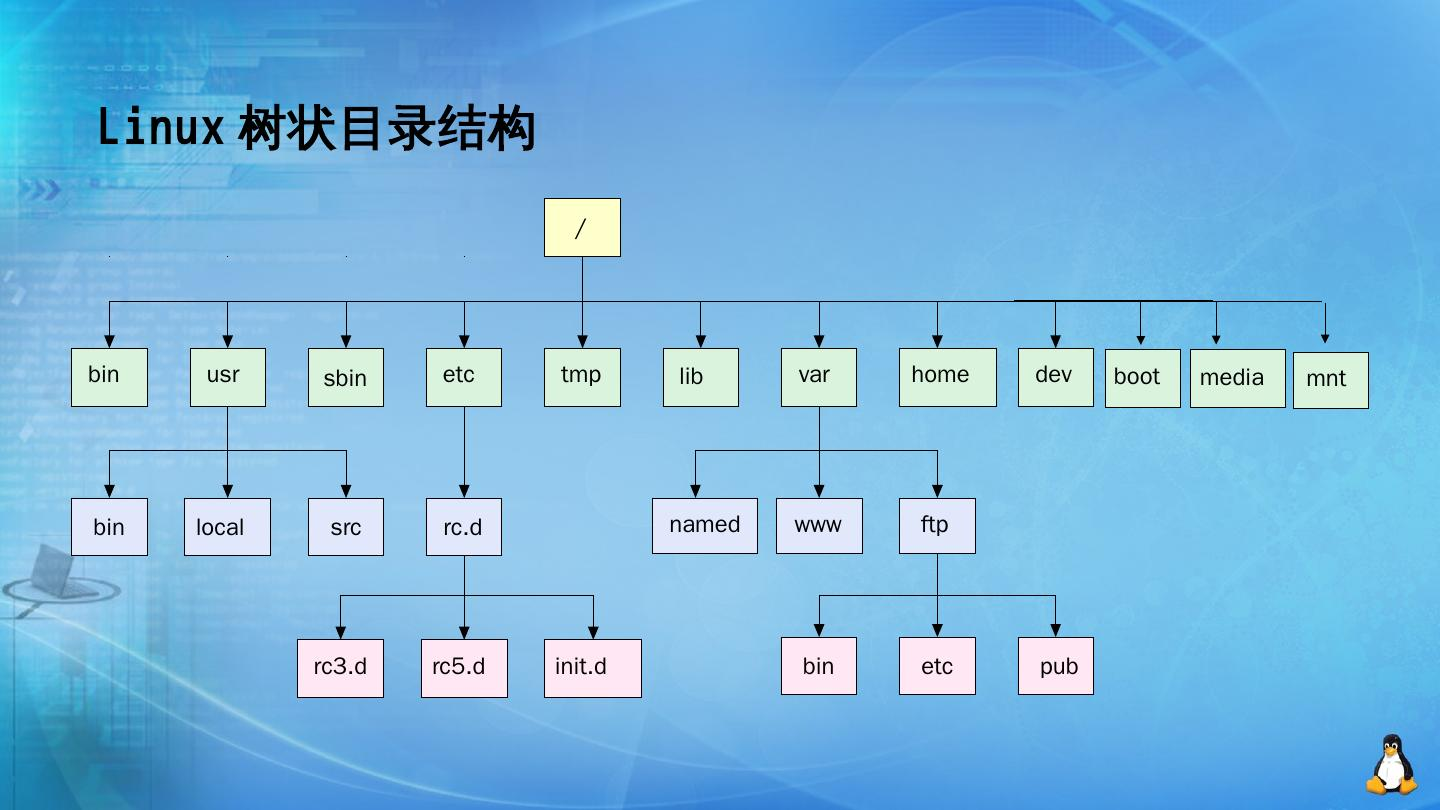
linux文件目录分布
Windows
采用
DOS
命令
Linux
采用
Shell
命令
常用的Linux指令:
cd+
文件夹名字
:
访问某个文件夹
ls
: 显示当前所在目录的文件
touch+
文件名: 创建文件
rm+
文件名: 删除文件
mkdir+
目录名: 创建目录
rm -rf +
目录名: 删除目录
TAB
键: 补全
sudo +
命令: 用管理员权限执行命令
pwd:
显示当前目录的绝对路径
vi编辑器
vi是一种方便的代码编辑器,Linux系统一般是自带的
vi
和
vim
的区别:
vim
是
vi
的升级版,基础功能两者一致,不过在嵌入式开发板中
只有
vi
没有
vim
,但是在
Ubuntu
上我们可以使用
vim
编辑器,它的功能更加丰富。
这里只讲解
vi
编辑器基础用法,如果使用
vim
编辑器需要手动安装
vim
编辑器:
sudo apt‐get install vim
vi +
文件名 用
vi
打开
/
创建某个文本文件
vi
常用的两种模式
1.
命令行模式:按Esc进入,在这个模式下,可以输入常用命令
: +
行号:跳转到某一行
G
:跳转到文本末尾
yy:
复制某一行,复制的位置由光标所在位置决定
yx
:复制若干行,
x
代表行数,输入
2
,就是复制当前行和它下面的两行(总共三行),复制的位置由光标所在位置决定。
p
:把刚刚复制的内容进行粘贴,粘贴的位置由光标所在位置决定
:+wq
保存文本并退出
:+q
正常退出文本
:+q!
强制退出文本
:set nu
程序显示行号
:
dd
删除一行
ESC: gg=G
自动整理代码
2.
文本输入模式,按i进入
进入文本输入模式,即可编辑代码,注意只能键盘操作, 鼠标不行。
安装
gcc linux
编译器:
sudo apt‐get install gcc
写完的程序:
test.c
我们要将写完的程序 进行编译:gcc test.c
生成二进制文件:a.out(
编译完之后默认生成的文件)
指定生成的文件名
gcc test.c -o hello
linux文件
Linux
自带的工具:
man
手册:
man 1
是普通的
shell
命令,比如
ls
man 2
是系统调用函数,比如
open
,
write
说明
Linux
文件权限
Linux
系统中采用三位十进制数表示权限,如
0755
,
0644.
7 1+2+4
5 1+4
5 1+4
ABCD
A- 0
, 表示十进制
B
-用户
C
-组用户
D
-其他用户
‐‐‐ ‐> 0 (no excute , nowrite ,no read)
‐‐x ‐> 1 excute, (nowrite, no read)
‐w‐ ‐> 2 write
r‐‐ ‐> 4 read
‐wx ‐> 3 write, excute
r‐x ‐> 5 read, excute
rw‐ ‐> 6 read, write
rwx ‐> 7 read, write , excute
r:表示可读,w:表示可写,x:表示可执行
例如7:可读可写可执行
比如执行ls -l 指令后
-rw-rw-r-- 1 cc cc 41 May 2 06:53 1q
-rw-rw-r-- 1 cc cc 13 May 2 05:53 a.c
-rw-rw-r-- 1 cc cc 42 May 2 06:54 add.c
-rw-rw-r-- 1 cc cc 1232 May 2 06:54 add.o
-rw-r--r-- 1 cc cc 363 May 2 05:31 cat.c
-rwxrwxr-x 1 cc cc 8656 May 2 02:04 demo
例如文件a.c:用户的权限是:可读可写,组用户的权限是:可读可写,其他用户的权限是:可读
1.open函数
在
Linux
系统库的定义:
//包含的头文件:
#include <sys/types.h>//这里提供类型pid_t和size_t的定义
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags); /*比较常用*/
int open(const char *pathname, int flags, mode_t mode);
返回值:
成功,返回句柄,我们后面对于文件的读写,关闭等都通过句柄来操作。
失败,返回
-1
参数说明:
pathname
:文件的路径名,如果只写文件名,就默认当前目录,如果在文件名加上路径,就按照绝对路径来打开文件
示例:
const char *file_path = "/home/user/test.txt";
flags
:表示打开文件后用的操作
含义:这是一个整数类型的参数,用于指定文件的打开方式和行为。它可以是一个或多个标志位的按位或组合(使用 | 运算符)。以下是一些常见的标志位:
访问模式标志:
O_RDONLY:以只读模式打开文件。
O_WRONLY:以只写模式打开文件。
O_RDWR:以读写模式打开文件。
其他常用标志:
O_CREAT:如果文件不存在,就创建该文件。当使用这个标志时,需要提供第三个参数 mode 来指定文件的权限。
O_EXCL:和 O_CREAT 一起使用时,如果文件已经存在,open() 调用会失败。
O_TRUNC:如果文件已经存在并且以写模式打开,会将文件截断为长度为 0。
O_APPEND:每次写操作都会将数据追加到文件末尾。
示例:
// 以只读模式打开文件
int fd1 = open("/home/user/test.txt", O_RDONLY);
// 如果文件不存在则创建它,以读写模式打开
int fd2 = open("/home/user/new_file.txt", O_RDWR | O_CREAT, 0666);2.close函数
#include <unistd.h>//包含的头文件
int close(int fd);参数是文件的句柄,功能就是简单的关闭文件
3.write函数
write()会把参数buf所指的内存写入count个字节到参数fd所指的文件内
#include <unistd.h>
ssize_t write (int fd,const void * buf, size_t count);参数说明:
fd: 文件描述符
*buf:
写入的数据的首地址
count:
写入数据个数
返回值:
如果顺利
write()
会返回实际写入的字节数(
len
),当有错误发生时则返回
-1
,错误代码存入
errno
中
4.read函数
从打开的fd设备或文件中读取count个字节到buf中
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
参数说明:
fd: 文件描述符
*buf:
读入数据的首地址
count:
读入数据的个数
返回值:
成功返回读取的字节数,出错返回
-1
并设置
errno
,如果在调
read
之前已到达文件末尾,则这次
read返回0
main函数参数
int main(int argc,char *argv[])
{
return 0;
}
C
语言规定了
main
函数的参数只能有两个,一个是
argc,
一个是
argv
并且,
argc
只能是整数,第二个必须是指向字符串的指针数组
由于main函数不能被其它函数调用, 因此不可能在程序内部取得实际值。那么,在何处把实参值赋予main 函数的形参呢? 实际上,main函数的参数值是从操作系统命令行上获得的。当我们要运行一个可执行文件时, 在DOS提示符下键入文件名,再输入实际参数即可把这些实参传送到main的形参中去。DOS提示符下命令行 的一般形式为:
C:>
可执行文件名 参数 参数
……;
但是应该特别注意的是,
main
的两个形参和命令行中的参数在 位置上不是一一对 应的。
argc:
参数表示命令行中参数的个数(注意 文本名本身也是一个参数),a
rgc
的值是在输入命令行时由系统按 实际参数的个数自动赋予的。
argv
:参数是字符串指针数组,其各元素值为命令行中各字符串
(
参数均按字符串处理
)
的首地址。 指针数组 的长度即为参数个数。数组元素初值由系统自动赋予。
下面实现cp指令来理解main函数的参数:
编写demo.c:
include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main(int argc,char *argv[])
{
int src_fd;
int des_fd;
char sendBuffer[128]={0};
int ByteNum = 0;
src_fd = open(argv[1],O_RDWR);
if(src_fd < 0)
{
printf("open file %d failed\n",src_fd);
return -2;
}
des_fd = open(argv[2],O_RDWR|O_CREAT,0755);
if(des_fd <0)
{
printf("open file %d failed\n",des_fd);
return -1;
}
while(1)
{
ByteNum = read(src_fd,&sendBuffer[0],128);
if(ByteNum<128)
break;
write(des_fd,&sendBuffer[0],ByteNum);
memset(sendBuffer,0,128);
}
write(des_fd,sendBuffer,ByteNum);
close(src_fd);
close(des_fd);
return 0;
}
此时在命令行编译demo.c生成可执行文件a.out后
在命令行输入./a.out demo.c demo1.c即可实现cp demo.c demo1.c 的效果
此时main函数的参数argc的值为3,数组argv[0]存放的是./a.out,argv[1]存放的是demo.c,argv[2]存放的是demo1.c
5.lseek函数
off_t lseek(int fd, off_t offset, int whence);//设置光标偏移量
参数说明:
fd :
文件描述符
Offset
:偏移量
Whence :
SEEK_SET:
参数
offset
即为新的读写位置
SEEK_CUR:
以目前的读写位置往后增加
offset
个偏移量
SEEK_END:
将读写位置指向文件尾后再增加
offset
个位移量,当
whence
值为
SEEK_CUR
或
SEEK_END
时,参数offset
允许负值的出现。
返回值: 文件读写距离文件开头的字节大小,出错返回
-1
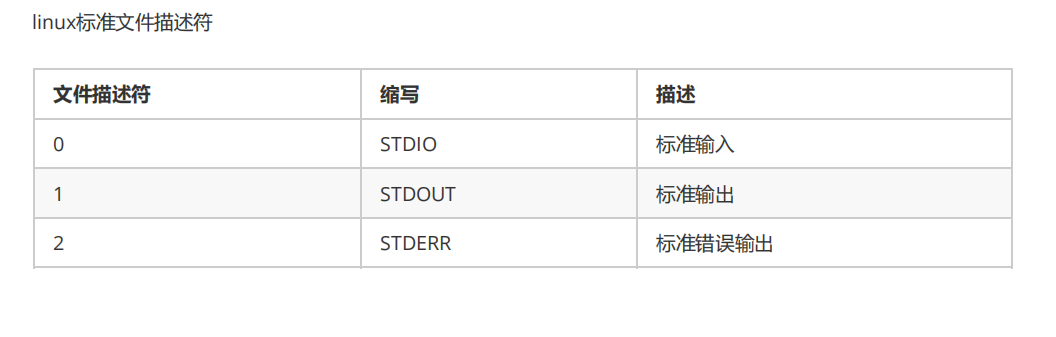
文件IO和标准IO
概念层面
- 文件 I/O:也被称为低级 I/O 或者系统调用 I/O,它直接使用操作系统提供的系统调用来进行文件操作,如在 Unix/Linux 系统中的
open、read、write、lseek和close等函数。这些系统调用是操作系统内核的一部分,提供了对文件最基本的访问方式。 - 标准 I/O:又称为高级 I/O,它是基于 C 标准库实现的一套文件操作接口,如
fopen、fread、fwrite、fseek和fclose等函数。标准 I/O 库对底层的文件 I/O 系统调用进行了封装,提供了更方便、更高级的文件操作功能。
缓冲机制
- 文件 I/O:通常是无缓冲或者使用内核缓冲。无缓冲意味着每次调用
read或write函数时都会直接进行系统调用,与磁盘或其他设备进行数据交互,这可能会导致频繁的系统调用,从而影响性能。内核缓冲由操作系统内核管理,应用程序无法直接控制。 - 标准 I/O:使用用户空间的缓冲区,标准 I/O 库会在内存中为每个文件流分配一个缓冲区。当调用
fread或fwrite函数时,数据会先被读写到缓冲区中,只有当缓冲区满或者调用fflush函数时,才会将缓冲区中的数据实际写入磁盘或从磁盘读取数据到缓冲区。这种缓冲机制可以减少系统调用的次数,提高 I/O 性能。
可移植性
- 文件 I/O:不同的操作系统提供的文件 I/O 系统调用可能有所不同,因此使用文件 I/O 编写的代码可移植性较差。例如,Windows 系统和 Unix/Linux 系统的文件 I/O 接口存在差异。
- 标准 I/O:C 标准库定义了一套统一的标准 I/O 接口,这些接口在不同的操作系统和编译器上具有较好的可移植性。只要是支持 C 标准库的系统,都可以使用标准 I/O 函数进行文件操作。
错误处理
- 文件 I/O:文件 I/O 系统调用通常通过返回值和
errno变量来进行错误处理。返回值可以表示操作的结果,如open函数返回 -1 表示打开文件失败,而errno变量可以进一步指示具体的错误类型。 - 标准 I/O:标准 I/O 函数通常通过返回值来表示操作的结果,如
fopen函数返回NULL表示打开文件失败。同时,标准 I/O 库还提供了ferror和feof等函数来检查文件流的错误和结束状态。
操作灵活性
- 文件 I/O:文件 I/O 提供了对文件操作的底层控制,例如可以直接设置文件偏移量、指定读写的字节数等,适合对文件进行底层的、精细的操作。
- 标准 I/O:标准 I/O 提供了更高级的功能,如格式化输入输出(
fprintf和fscanf)、行缓冲等,适合进行更方便、更复杂的文件操作。
文件
IO
:是直接调用内核提供的系统调用函数
,
头文件是
unistd.h
标准
IO
:是间接调用系统调用函数,头文件是
: stdio.h
之前学过:输入输入相关的函数
,
都是和标准的输入(键盘),标准的输出(显示器)
getchar(),putchar() ‐‐‐‐
一个字符
gets(buf),puts(buf) ‐‐‐‐
一串字符
scanf(),printf() ‐‐‐‐
一个字符,一串字符都可以
与一些普通文件的读写没有关系,即这些函数不能读写普通文件。
标准
IO
中的相关函数,不仅可以读写普通文件,也可以向标准的输入或标准的输出中读或写。
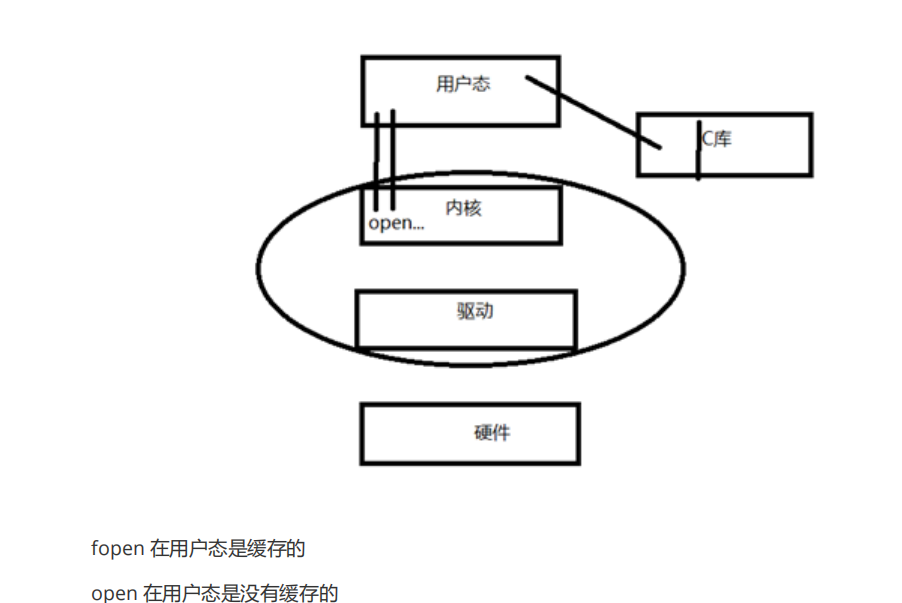
缓存的概念
1.
我们的程序中的缓存,就是你想从内核读写的缓存(数组)
----
用户空间的缓存
2.
每打开一个文件,内核在内核空间中也会开辟一块缓存,这个叫内核空间的缓存
文件
IO
中的写即是将用户空间中的缓存写到内核空间的缓存中。
文件
IO
中的读即是将内核空间的缓存写到用户空间中的缓存中。
3.
标准
IO
的库函数中也有一个缓存,这个缓存称为
----
库缓存
缓冲类型
标准 C 库有三种缓冲类型:
- 无缓冲(Unbuffered):在无缓冲模式下,每次进行 I/O 操作都会立即调用底层的系统调用,数据不会在用户空间的缓冲区中停留。标准错误输出流
stderr通常就是无缓冲的,这样能保证错误信息及时输出,方便用户及时发现程序问题。 - 行缓冲(Line-buffered):行缓冲模式下,数据会先被存储在用户空间的缓冲区,直到遇到换行符
\n或者缓冲区满了,才会调用底层系统调用将缓冲区中的数据写入内核。标准输入流stdin和标准输出流stdout在与终端交互时一般采用行缓冲模式,以确保用户输入的一行数据能及时处理,程序输出的一行信息能及时显示。 - 全缓冲(Fully-buffered):全缓冲模式下,数据会被存放在用户空间的缓冲区,直至缓冲区被填满,才会调用底层系统调用将数据写入内核。磁盘文件默认使用全缓冲模式,通过减少系统调用次数来提高 I/O 性能。
验证缓冲机制:
#include "stdio.h"
int main()
{
char buf[]="hello linux";
printf("%s",buf);
while(1);
return 0;
}此时buf的内容不会打印到显示器上面
6.fopen函数
fopen fwrite fread fclose ...
属于标准
C
库,都具有缓冲机制
函数原型
#include <stdio.h>
FILE *fopen(const char *pathname, const char *mode);
/*
* @description : 打开一个文件
* @param ‐ pathname : 指定文件路径,如:"./test.txt"
* @param ‐ mode :指定文件的打开方式,如下:
* @return : 成功,返回指向该文件的文件指针; 若失败,返回 NULL
*/
参数说明:
第一个参数为欲打开文件的文件路径及文件名,第二个参数表示对文件的打开方式
返回值:
文件打开了,返回一个指向该打开文件的指针
(FILE
结构
)
;文件打开失败,错误上存
errorcode(
错误代码
)
mode有以下值:
r
:只读方式打开,文件必须存在
r+
:可读写,文件必须存在
rb+
:打开二进制文件,可以读写
rt+:
打开文本文件,可读写
w:
只写,文件存在则文件长度清
0
,文件不存在则建立该文件
w+:
可读写,文件存在则文件长度清
0
,文件不存在则建立该文件
a:
附加方式打开只写,不存在建立该文件,存在写入的数据加到文件尾,
EOF
符保留
a+
:附加方式打开可读写,不存在建立该文件,存在写入的数据加到文件尾,
EOF
符不保留
wb
:打开二进制文件,只写
wb+:
打开或建立二进制文件,可读写
wt+:
打开或建立文本文件,可读写
at+:
打开文本文件,可读写,写的数据加在文本末尾
ab+:
打开二进制文件,可读写,写的数据加在文件末尾
7.fread函数
从文件中读取数据到指定地址中
#include <stdio.h>
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
/*
* @description :对已打开的流进行数据读取
* @param ‐ ptr :指向 数据块的指针
* @param ‐ size :指定读取的每个数据项的字节数
* @param ‐ nmemb : 指定要读取的数据项的个数
* @param ‐ stream :要读取的文件流
* @return : 返回实际读取数据项的个数;
*/
参数说明:
第一个参数为接收数据的指针
(buff),
也即数据存储的地址
第二个参数为单个元素的大小,即由指针写入地址的数据大小,注意单位是字节
第三个参数为元素个数,即要读取的数据大小为
size
的元素个素
第四个参数为提供数据的文件指针,该指针指向文件内部数据
返回值:
读取的总数据元素个数
8.fwrite函数
#include <stdio.h>
size_t fwrite(const void *ptr, size_t size, size_t nmemb,FILE *stream);
/*
* @description :对已打开的流进行写入数据块
* @param ‐ ptr :指向 数据块的指针
* @param ‐ size :指定写入的每个数据项的字节数,如调用sizeof(char)
* @param ‐ nmemb :指定写入的数据项的个数
* @param ‐ stream :要写入的文件流
* @return : 返回实际写入的数据项的个数
*/
fread()
──
从
fp
所指向文件的当前位置开始,一次读入
size
个字节,重复nmemb
次,并将读入的数据存放 到从buffer
开始的内存中;
buffer
是存放读入数据的起始地址(即存放何处)
fwrite()
──
从
buffer
开始,一次输出
size个字节,重复nmemb次,并将输出的数据存放到fp
所指向的文件 中。buffer
是要输出数据在 内存中的起始地址(即从何处开始输出)
一般用于二进制文件的处理
9.fseek函数
重定位文件内部的指针
int fseek(FILE *stream,long offset,int framewhere)
参数:第一个为文件指针,第二个是指针的偏移量,第三个是指针偏移起始位置
返回值:重定位成功返回
0
,否则返回非零值
说明:执行成功,则
stream
指向以
fromwhere
为基准,偏移
offset
个字节的位置。执行失败
(
比方说
offset
偏移的位 置超出了文件大小)
,则保留原来
stream
的位置不变
起始位置:
SEEK_SET
既
0
文件开头
SEEK_CUR
既
1
文件当前位置
SEEK_END
既
2
文件结尾
例如:
1. fseek(fp,100L,SEEK_SET);
把
fp
指针移动到离文件开头
100
字节处;
2. fseek(fp,100L,SEEK_CUR);
把
fp
指针移动到离文件当前位置
100
字节处;
3. fseek(fp,-100L,SEEK_END);
把
fp
指针退回到离文件结尾
100
字节处。
10.fclose函数
关闭一个文件流,使用fclose就可以把缓冲区内最后剩余的数据输出到磁盘文件中,并释放文件指针和有关 的缓冲区
#include <stdio.h>
int fclose(FILE *stream);
/*
* @description :关闭一个已打开的流
* @param ‐ stream :文件指针(流)
* @return : 成功,返回0; 若失败,返回EOF
*/
11.fgets和fputs
char *fgets (char *s, int size,FILE *stream)
第一个参数:缓存,即读到哪里去
第二个参数:读多少个字节
第三个参数:从什么地方读
返回值:若成功则为
s
(缓存的地址),若已处文件尾端或出错则为
null
int fputs(const char *s,FILE *stream);
第一个参数:缓存,即写什么内容
第二个参数:写到哪里去
返回值:若成功则为非负值,若出错则为
EOF -1
gets
与
fgets
的区别:
gets()
时不能指定缓存的长度,这样就可能造成缓存越界(如若该行长于缓存长度),写到缓存之后的存储空间中,从而产生不可预料的后果;
gets()
只能从标准输入中读;
gets()
与
fgets()
的另一个区别是
:gets()
并不将新行符存入缓存中
, fgets
将新行符存入缓存中
;
puts
与
fputs
的区别:
puts()
只能向标准输出中写;
puts()
与
fputs()
的另一个区别是
: puts
输出时会添加一个新行符,
fputs
不会添加;
12.刷新缓存函数
把库函数中的缓存内容强制写到内核中。
ffluash(FIFE *fp)13.调整读写位置指针函数
fseek()
参数与
lseek
是一样的但是返回值不一样
lseek
的返回值是:当前文件的位置指针值;
fseek()
的返回值是:成功返回
0
,失败返回
-11
;
rewind(FILE *fp)
用于设定流的文件位置指示为文件开始,该函数调用成功无返回值。
rewind()
等价于
(void)fseek(fp 0, SEEK_SET)
;
ftell(FILE *fp) 用于取得当前的文件位置,调用成功则为当前文件位置指示,若出错则为-1L
;
14.fprintf、printf、sprintf
int fprintf(FILE *stream,”
字符串格式
”)
fprintf
可以输出到文件中,也可输出到显示器,
printf
只能输出到显示器中。
intsprintf(str *, “
字符串格式
”) 输出内容到一个字符串中
15.fgetc和fputc
int fgetc(FILE *fp)
功能:从文件中读取一个字符;
参数:文件流
返回值:正确为读取的字符,到文件结尾或出错时返回
EOF
。
int fputc(int c, FILE *fp)
功能:写一个字符到文件中
参数:第一个参数为要写的字符,第二个参数为文件流
返回值:成功则返回输入的字符,出错返回EOF。
int feof(FILE *stream)
功能:判断是否已经到文件结束
参数:文件流
返回值:到文件结束,返回为非
0
,没有则返回
0
int ferror(FILE *stream);
功能:判断是否读写错误
参数:文件流
返回值:是读写错误,返回为非
0
,不是则返回
0
void clearerr(FILE *stream);
功能:清除流错误
参数:文件流
实现cat指令
#include <stdio.h>
int main(int argc,char *argv[])
{
FILE*fp;
int nRet = 0;
if(argc != 2)
{
printf("failed\n");
return -1;
}
fp = fopen(argv[1],"r");
if(fp == NULL)
{
printf("open file failed\n");
return -2;
}
while(1)
{
nRet = fgetc(fp);
if(feof(fp))
{
break;
}
fputc(nRet,stdout);
}
fclose(fp);
return 0;
}
编译后在命令行输入./a.out cat.c 即可实现cat cat.c 的效果
静态库和动态库
静态库,
libxxx.a
,在编译时就将库编译进可执行程序中。
优点:程序的
运行环境
中不需要外部的函数库。
缺点:可执行程序大
动态库,又称共享库,
libxxx.so
,在运行时将库加载到可执行程序中。
优点:可执行程序小。
缺点:程序的
运行环境
中必须提供相应的库。
函数库目录:
/lib /usr/lib
静态库的制作
1.创建库文件
gcc -c mylib.c -o mylib.o
ar rcs libmylib.a mylib.o
2.使用库文件
gcc main.c -o main -L. -lmylib
./main动态库的制作
1.
生成目标文件
gcc -c file.c
2.生成
libaddsub.so
动态函数库
gcc -shared -fpic -o libfile.so file.o
‐fpic:产生位置无关代码
‐shared:生成共享库
3.使用库文件
gcc ‐o out main.c ‐L. ‐lfile
此时还不能立即
./out
,因为在动态函数库使用时,会查找
/usr/lib /lib
目录下的动态函数库,而此时我们生成的库 不在里边
第一种方法:
libaddsub.so
放到
/usr/lib
或
/lib
中去
第二种方法:
假设
libfile.so
在
/home/linux/file
环境变量方法
export LD_LIBRARY_PATH=/home/linux/addsub
:
$LD_LIBRARY_PATH
第三种方法:
在
/etc/ld.so.conf
文件里加入我们生成的库的目录,然后
/sbin/ldconfig
/etc/ld.so.conf
是非常重要的一个目录,里面存放的是链接器和加载器搜索共享库时要检查的目录,默认是从/usr/lib /lib
中读取的,所以想要顺利运行,可以把我们库的目录加入到这个文件中并执行
/sbin/ldconfig


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









