







ERA5数据广泛应用于气象和气候模拟,本文将展示如何利用ECMWF的Web API自动化下载ERA5再分析数据(以ERA5-Land hourly data from 1950 to present数据集为例,其他数据集同理),轻松获取所需数据,驱动WRF数值模式。
文章目录
目录
1. ERA5数据介绍
ERA5是由欧洲中期天气预报中心(ECMWF)发布的第五代大气再分析全球气候数据。该数据集的第一部分(涵盖从1979年到3个月前的数据)现已公开提供。ERA5数据提供每小时的大气、陆地和海洋气候变量的估计值,数据精度高达30公里网格,且包括137层的大气数据。官方网址:Catalogue — Climate Data Store 界面如下
我们驱动WRF需要的数据集ERA5-Land hourly data from 1950 to present 最新版界面以及我们需要的变量如下
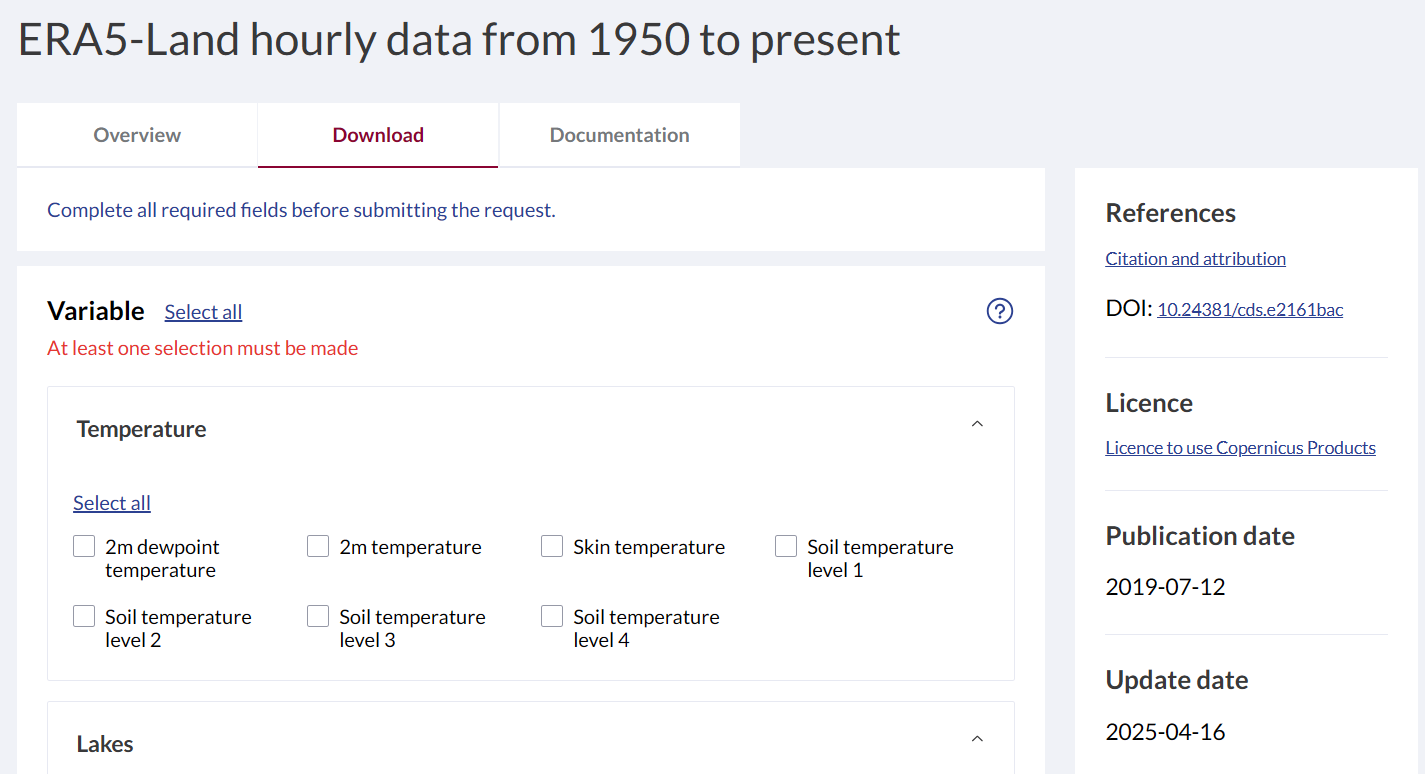
ERA5驱动WRF所需变量
高空数据需要以下变量:
'geopotential', 'relative_humidity', 'specific_humidity', 'temperature', 'u_component_of_wind', 'v_component_of_wind'地面数据需要以下变量:
'surface_pressure', 'mean_sea_level_pressure', '10m_u_component_of_wind', '10m_v_component_of_wind', '2m_temperature', 'sea_surface_temperature', 'skin_temperature', '2m_dewpoint_temperature', 'snow_depth', 'sea_ice_cover', 'land_sea_mask', 'soil_type', 'soil_temperature_level_1', 'soil_temperature_level_2', 'soil_temperature_level_3', 'soil_temperature_level_4', 'volumetric_soil_water_layer_1', 'volumetric_soil_water_layer_2', 'volumetric_soil_water_layer_3', 'volumetric_soil_water_layer_4'2. API下载方式下载数据的介绍与准备工作
(1) 注册CDS账号
只有完成注册账号并登录后才能下载数据,官网右上角可直接使用邮箱注册,页面如下:
注册完后查看自己的邮箱,会给个链接设置密码。

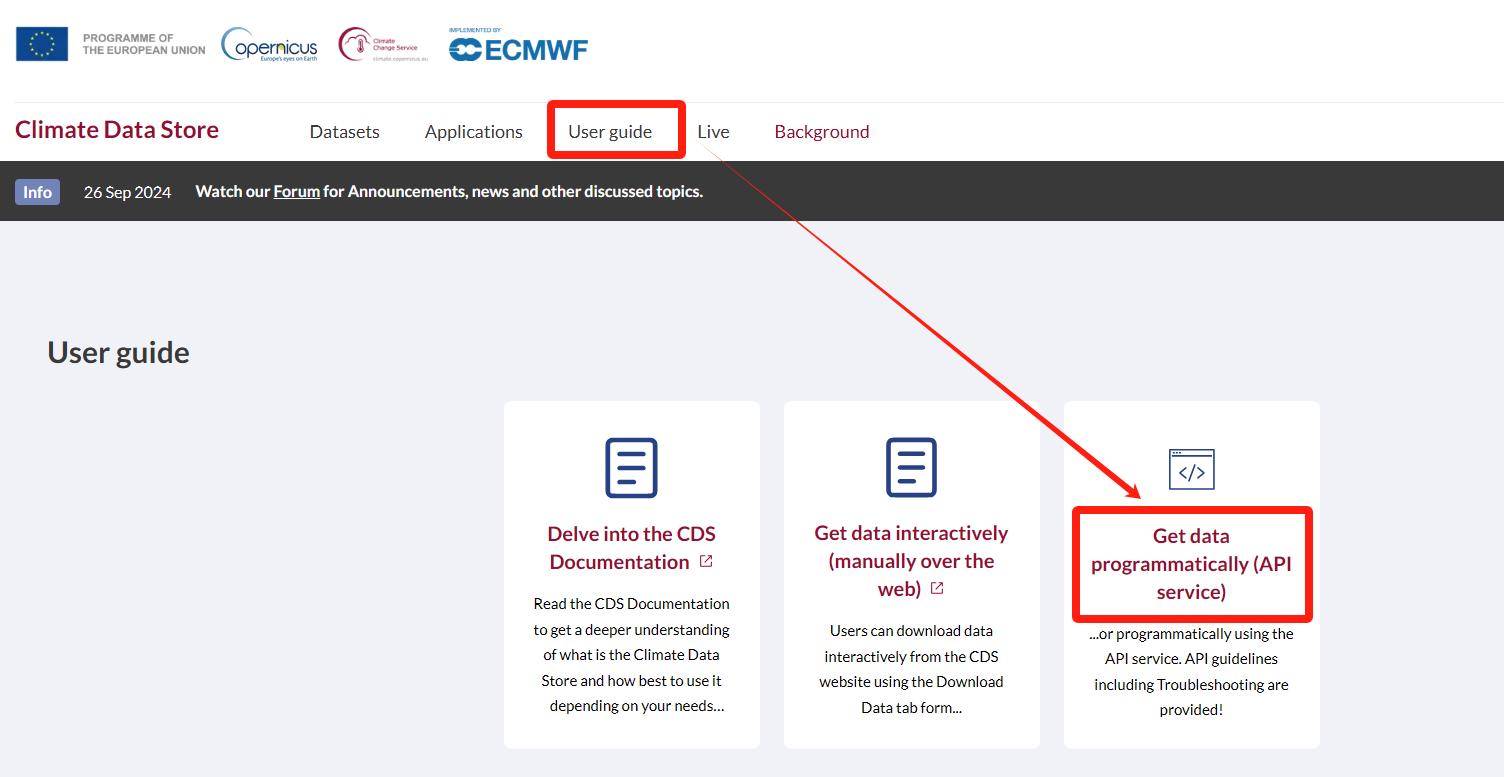
(2) 获取API key
注册并登录后,1点击User guide进入下图图1页面,2再点击Get dataprogrammatically(API service)进入图2页面。在图2页面中找到API key部分(如下图),记录下url和key,方便后续数据下载使用。
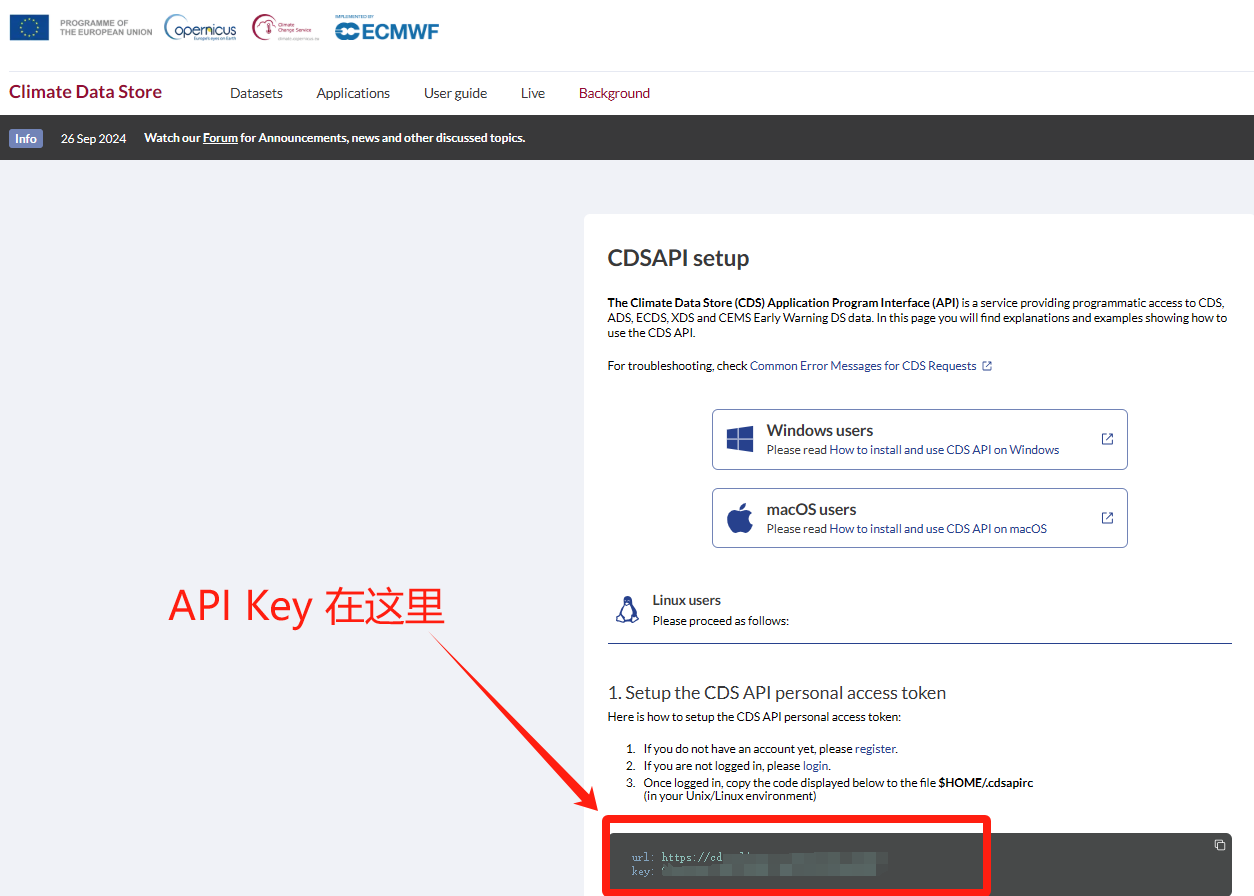
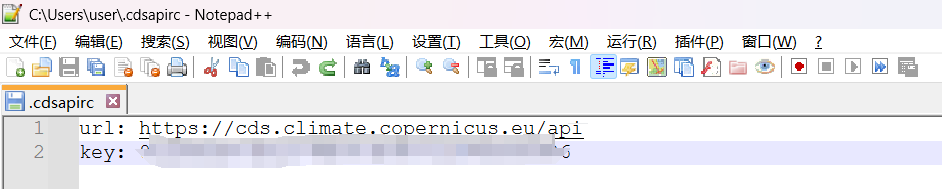
(3) 创建".cdsapirc"文件
windows系统中,在路径 “C:\Users\用户名” 下创建 “.cdsapirc” 文件(步骤:1.新建文本文档,输入url和key内容后,将此文件另存为,选择文件类型-”所有文件“,文件名: “.cdsapirc”)。在 “.cdsapirc” 文件输入的内容如下:
![]()
(4) 安装cdsapi第三方库
可以直接打开控制台,在cmd中输入如下命令,安装cdsapi第三方库
pip install cdsapi3. ERA5数据下载步骤与完整python代码
运行下方Python脚本,CDS API将自动连接Copernicus服务器下载所需数据。以下以驱动WRF模型所需的变量下载为例,提供两种实现方式:
方法一:官方标准脚本(基础版)
(1)高空多层数据下载-python代码
# 导入Copernicus Data Store (CDS)官方API库
# 需提前安装:pip install cdsapi
# 并配置~/.cdsapirc文件(含API密钥)
import cdsapi
# 指定数据集名称(ERA5气压层再分析数据)
# 注意区分:
# - "reanalysis-era5-pressure-levels":高空多层数据
# - "reanalysis-era5-single-levels":地表单层数据
dataset = "reanalysis-era5-pressure-levels"
# 构建符合CDS API要求的请求字典
request = {
# 产品类型(必须为"reanalysis"才能获取ERA5数据)
"product_type": "reanalysis", # 其他选项如"analysis"不适用于ERA5
# 数据格式(WRF推荐使用GRIB1格式)
"format": "grib", # 可选"netcdf",但WRF对GRIB支持更好
# 气象变量列表(变量名必须与CDS数据库完全一致)
"variable": [
"geopotential", # 位势高度(m**2/s**2)
"relative_humidity", # 相对湿度(%)
"temperature", # 温度(K)
"specific_humidity", # 比湿(kg/kg)
"u_component_of_wind", # 纬向风(m/s)
"v_component_of_wind", # 经向风(m/s)
"vertical_velocity" # 垂直速度(Pa/s)
],
# 气压层(单位hPa,必须为字符串格式)
"pressure_level": [ # 完整ERA5气压层(共37层)
"1", "2", "3", "5", "7", "10", # 高层(平流层/对流层顶)
"20", "30", "50", "70", "100", # 中高层
"125", "150", "175", "200", # 对流层上部
"225", "250", "300", "350", # 对流层中部
"400", "450", "500", "550", # 对流层下部
"600", "650", "700", "750", # 低层
"775", "800", "825", "850", # 边界层上部
"875", "900", "925", "950", # 边界层下部
"975", "1000" # 近地面
],
# 时间范围(必须为字符串格式)
"year": "2024", # 年份(ERA5当前覆盖1940-近实时)
"month": "06", # 月份(必须补零,如"06"而非"6")
"day": ["01", "02", "03", "04"], # 日期(可单日或多日列表)
# 时间点(UTC时间,必须为HH:MM格式)
"time": [ # 完整逐小时数据(24时次)
"00:00", "01:00", "02:00", "03:00", "04:00", "05:00",
"06:00", "07:00", "08:00", "09:00", "10:00", "11:00",
"12:00", "13:00", "14:00", "15:00", "16:00", "17:00",
"18:00", "19:00", "20:00", "21:00", "22:00", "23:00"
],
# 空间区域([North, West, South, East])
"area": [55.25, 69.75, 14.75, 140.25], # 单位:度
}
# 创建CDS API客户端实例
# 注意:会自动读取~/.cdsapirc中的URL和key
client = cdsapi.Client()
# 执行请求并下载数据
# 输出文件命名建议:
# - 包含数据集类型(era5_pl)
# - 时间范围(20240601-04)
# - 格式后缀(.grib)
client.retrieve(dataset, request).download("era5_pl_20240601-04.grib") # 指定数据文件名,默认下载到一个文件中
注:此模板未完全覆盖API配额超限、网络中断等异常场景,建议生产环境补充重试机制和日志监控。

(2)地表单层数据下载-python代码
import cdsapi
# 初始化CDS API客户端(需提前配置~/.cdsapirc文件)
# 注意:CDS API密钥需在官网注册获取(https://cds.climate.copernicus.eu)
client = cdsapi.Client()
# 请求ERA5地表单层数据(与高空数据时空范围对应)
client.retrieve(
'reanalysis-era5-single-levels', # 数据集名称(不可更改)
{
# 必须参数(直接来自CDS官方文档要求)
'product_type': 'reanalysis', # 固定值,表示再分析产品
'format': 'grib', # 格式必须小写(GRIB/NetCDF二选一)
# 变量列表(所有名称必须与CDS数据库完全一致)
'variable': [ '10m_u_component_of_wind','10m_v_component_of_wind','2m_dewpoint_temperature',
'2m_temperature','forecast_albedo',
'forecast_surface_roughness','high_cloud_cover',
'land_sea_mask','low_cloud_cover',
'mean_sea_level_pressure','medium_cloud_cover',
'sea_ice_cover','sea_surface_temperature',
'skin_temperature','snow_albedo',
'snow_depth','surface_pressure',
'total_cloud_cover',
'total_column_water','total_column_water_vapour',
'soil_temperature_level_1','soil_temperature_level_2',
'soil_temperature_level_3','soil_temperature_level_4','volumetric_soil_water_layer_1','volumetric_soil_water_layer_2',
'volumetric_soil_water_layer_3','volumetric_soil_water_layer_4'
],
# ---- 时间范围(与高空数据一致)----
'year': '2024', # 年份(字符串格式)
'month': '06', # 月份(必须补零)
'day': ['01', '02', '03', '04'], # 日期列表(字符串格式)
'time': [f"{hour:02d}:00" for hour in range(24)], # UTC时间HH:MM格式
# ---- 空间范围(与高空数据相同)----
# 格式:[北纬, 西经, 南纬, 东经](单位:度)
# 注意:经度范围-180到180,西经为负值
'area': [55.25, 69.75, 14.75, 140.25] # 中国区域
},
# 输出文件命名规范:数据集_时间_类型.grib
'era5_surface_20240601-04.grib' # 推荐明确包含"surface"标识以作区分
)方法二:改进增强脚本(推荐)
import os
from datetime import datetime, timedelta
import cdsapi
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm # 进度条
# 文件最小阈值(1 MB),小于此大小视为不完整
MIN_FILE_SIZE = 1 * 1024 * 1024
# 定义安全下载函数,若下载失败会删除不完整的文件
def safe_retrieve(client, dataset, request, outfile):
"""下载文件,失败时删除不完整文件"""
try:
print(f"⬇️ 正在下载 {dataset}: {outfile}")
client.retrieve(dataset, request, outfile) # 使用CDS API进行数据下载
print(f"✅ 下载成功: {outfile}")
except Exception as e:
print(f"❌ 下载失败: {outfile}, 错误信息: {e}")
# 删除可能已写入的不完整文件
if os.path.exists(outfile):
os.remove(outfile) # 删除不完整的文件
print(f"🗑️ 删除不完整文件: {outfile}")
# 定义下载某一小时数据的函数
def download_one_hour(itime):
client = cdsapi.Client() # 创建CDS API客户端
# 文件路径(根据时间生成文件名)
pl_file = f"data/era5_{itime:%Y%m%d%H}_pl.grib" # 压力层数据文件路径
ml_file = f"data/era5_{itime:%Y%m%d%H}_ml.grib" # 表面数据文件路径
# —— 压力层数据请求参数 —— #
pressure_request = {
"product_type": "reanalysis", # 数据类型为再分析数据
"variable": [
"geopotential", "relative_humidity", "temperature", "specific_humidity",
"u_component_of_wind", "v_component_of_wind", "vertical_velocity"
], # 请求的变量列表
"year": itime.strftime("%Y"), # 请求的年份
"month": itime.strftime("%m"), # 请求的月份
"day": itime.strftime("%d"), # 请求的日期
"time": [itime.strftime("%H:00")], # 请求的小时
"pressure_level": [str(p) for p in [
1, 2, 3, 5, 7, 10, 20, 30, 50, 70, 100, 125, 150, 175, 200, 225, 250, 300,
350, 400, 450, 500, 550, 600, 650, 700, 750, 775, 800, 825, 850, 875,
900, 925, 950, 975, 1000
]], # 请求的压力层列表
"format": "grib", # 返回的数据格式为GRIB格式
"area": [55.25, 69.75, 14.75, 140.25], # 请求的区域范围([北纬, 西经, 南纬, 东经])
}
# —— 表面层数据请求参数 —— #
surface_request = {
"product_type": "reanalysis", # 数据类型为再分析数据
"variable": [
"10m_u_component_of_wind", "10m_v_component_of_wind", "2m_dewpoint_temperature",
"2m_temperature", "forecast_albedo", "forecast_surface_roughness", "high_cloud_cover",
"land_sea_mask", "low_cloud_cover", "mean_sea_level_pressure", "medium_cloud_cover",
"sea_ice_cover", "sea_surface_temperature", "skin_temperature", "snow_albedo",
"snow_depth", "surface_pressure", "total_cloud_cover", "total_column_water",
"total_column_water_vapour", "soil_temperature_level_1", "soil_temperature_level_2",
"soil_temperature_level_3", "soil_temperature_level_4", "volumetric_soil_water_layer_1",
"volumetric_soil_water_layer_2", "volumetric_soil_water_layer_3",
"volumetric_soil_water_layer_4"
], # 请求的变量列表
"year": itime.strftime("%Y"), # 请求的年份
"month": itime.strftime("%m"), # 请求的月份
"day": itime.strftime("%d"), # 请求的日期
"time": [itime.strftime("%H:00")], # 请求的小时
"format": "grib", # 返回的数据格式为GRIB格式
"area": [55.25, 69.75, 14.75, 140.25], # 请求的区域范围([北纬, 西经, 南纬, 东经])
}
# —— 下载压力层数据 —— #
if os.path.exists(pl_file) and os.path.getsize(pl_file) >= MIN_FILE_SIZE:
# 如果文件已经存在且文件大小大于阈值,跳过下载
print(f"✔️ 压力层文件已存在: {pl_file}")
else:
if os.path.exists(pl_file):
# 如果文件存在但文件大小不符合要求,删除文件并重新下载
print(f"⚠️ 压力层文件太小,正在重新下载: {pl_file}")
os.remove(pl_file) # 删除不完整文件
# 下载压力层数据
safe_retrieve(client, "reanalysis-era5-pressure-levels", pressure_request, pl_file)
# —— 下载表面层数据 —— #
if os.path.exists(ml_file) and os.path.getsize(ml_file) >= MIN_FILE_SIZE:
# 如果文件已经存在且文件大小大于阈值,跳过下载
print(f"✔️ 表面层文件已存在: {ml_file}")
else:
if os.path.exists(ml_file):
# 如果文件存在但文件大小不符合要求,删除文件并重新下载
print(f"⚠️ 表面层文件太小,正在重新下载: {ml_file}")
os.remove(ml_file) # 删除不完整文件
# 下载表面层数据
safe_retrieve(client, "reanalysis-era5-single-levels", surface_request, ml_file)
# 主函数
def main():
# 设置开始和结束时间
start_time = datetime.strptime('2021071900', "%Y%m%d%H") # 设置开始时间
end_time = datetime.strptime('2021072100', "%Y%m%d%H") # 设置结束时间
interval_h = 1 # 每次下载的时间间隔(1小时)
# 创建保存数据的目录
os.makedirs('data', exist_ok=True)
# 构造所有时间点列表(从开始时间到结束时间,按小时递增)
all_times = []
t = start_time
while t <= end_time:
all_times.append(t)
t += timedelta(hours=interval_h)
# 并发下载数据,最多并发2个线程
max_workers = 2
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 使用线程池来并发下载每小时的数据
futures = {executor.submit(download_one_hour, t): t for t in all_times}
# 使用tqdm来显示进度条
for _ in tqdm(as_completed(futures), total=len(futures), desc="下载进度"):
pass
# 如果是主程序运行,则执行main函数
if __name__ == "__main__":
main()
通过本文介绍的两种ERA5数据下载方法,相信您已经能够根据需求选择适合的方案——无论是快速获取小规模数据的官方标准脚本,还是具备断点续传、并行下载能力的增强脚本,都能为您的科研或业务工作提供可靠支持。批量下载可以使用IDM具体见博客批量下载ERA5数据(Python+IDM)_import cdsapi-CSDN博客
如果在使用过程中遇到任何问题,或发现脚本存在需要改进的地方,欢迎随时私信交流。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









