






本人因为预算有限,把自己之前的显卡从4060升级到4070tisuper;其他配置如下:
精粤主板b760igaming,i5-12490f处理器,32*2DDR4 3200内存(发现没多大用,实际使用15g左右),1TSN850X硬盘。
开始使用时ds14b版本,发现回答的精度和准确性和32b版本差别很大,所以才升级的4070tisuper,
主要提升的显存,因为deepseek在训练过程中,显存的使用是刚需,内存反而不是特别明显,在训练70b 模型时,内存的使用提高了,目前还在测试阶段。
现在是我测试了半个月的代码,win10系统ollama框架,参数文件在这个文件夹名下:
所有的参数在config.json中进行调试,代码如下(欢迎大家交流):
{
"model": {
"name": "deepseek-r1:32b",
"n_gpu_layers": 42,
"batch_size": "auto",
"flash_attn": {
"version": "v2_tiled",
"tile_size": 192,
"num_kv_heads": 8
},
"quantization": {
"type": "gptq-4bit-64g",
"group_size": 64,
"act_order": true,
"damp_percent": 0.02
},
"mmap": true,
"low_vram": false
},
"data_loader": {
"workers": 4,
"prefetch_factor": 3,
"pin_memory": true,
"persistent_workers": true,
"async_upload": true,
"shard_strategy": "gradient"
},
"training": {
"micro_batch_size": "dynamic",
"grad_accum_steps": 2,
"use_amp": {
"matmul": "tf32",
"memory": "int4",
"cache": "nf4"
},
"gradient_checkpointing": {
"strategy": "layer_wise",
"interval": 4
},
"optimizer": {
"type": "lion_hybrid",
"lr": 2e-5,
"betas": [ 0.95, 0.98 ],
"weight_decay": 0.01,
"clip_grad": 1.0
},
"cuda_streams": {
"compute": 2,
"data": 1,
"proactive_migration": true
}
},
"memory_management": {
"cpu_cache_size": "10GB",
"gpu_cache_strategy": "blocked",
"page_lock_buffers": false,
"swap_threshold": 0.3
},
"hardware_tuning": {
"kernel_fusion": 3,
"tensor_cores": {
"mma_precision": "mixed",
"sparsity": 0.5,
"mma_format": "16x8x16"
},
"cuda_arch": "sm_89"
}
}
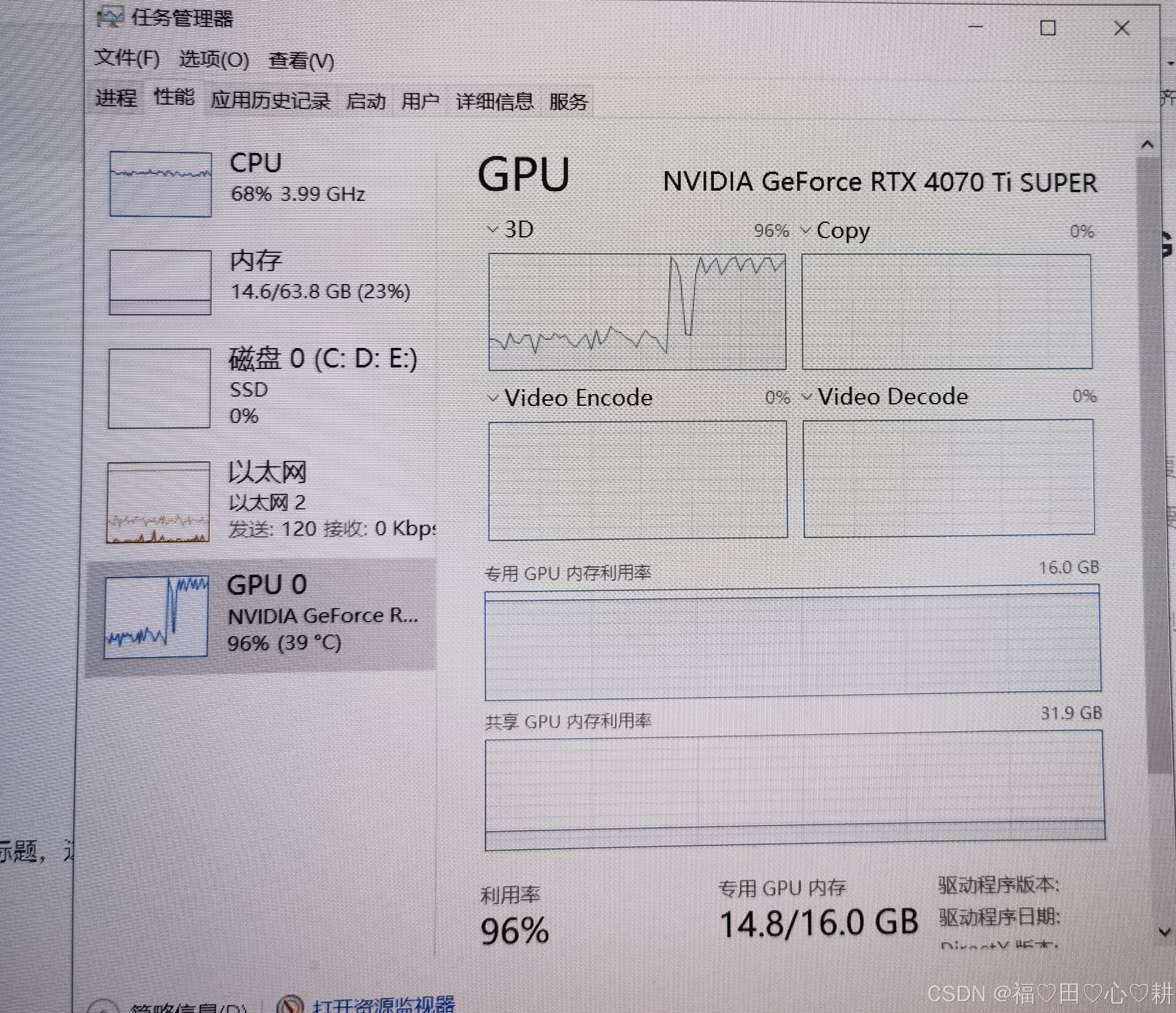
调整后的GPU使用明显提高:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









