






什么是数据冗余?
数据冗余是指同一数据在数据库中被重复存储多次的现象,通常表现为:
- 同一字段在不同表中重复出现
- 同一数据在同一表中重复存储
- 可通过其他字段计算得出的派生数据直接存储
危害示意图:
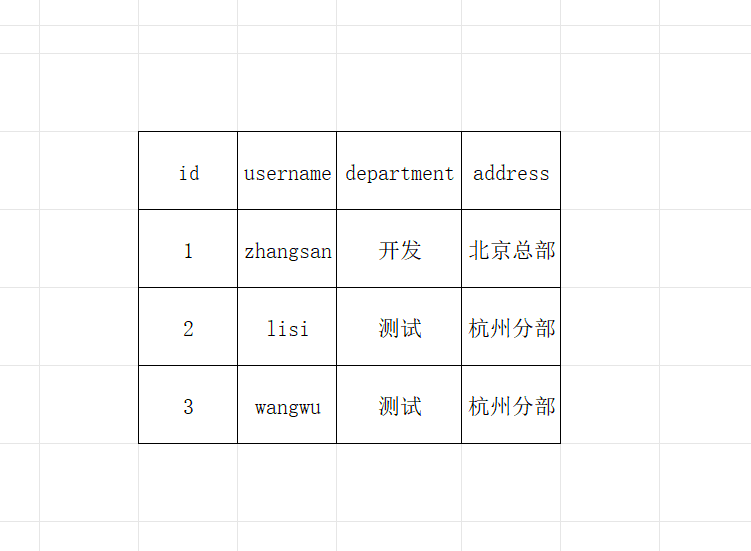
(部门地址重复存储造成冗余)
一、一对多关系处理
冗余示例(订单表)
订单表:
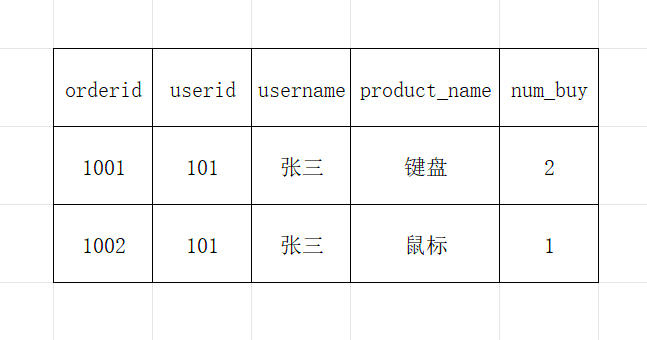
(用户名重复存储)
规范化设计
用户表和订单表分离:

关键改变:通过外键关联代替直接存储用户信息
优势分析:
1、数据一致性:用户信息修改只需更新一处
2、存储优化:减少约30%的存储空间(按示例计算)
3、维护便利:消除「幽灵数据」风险(已删除用户残留订单)
二、自连接关系处理
这个点我们用京东的商品分层来说一下。
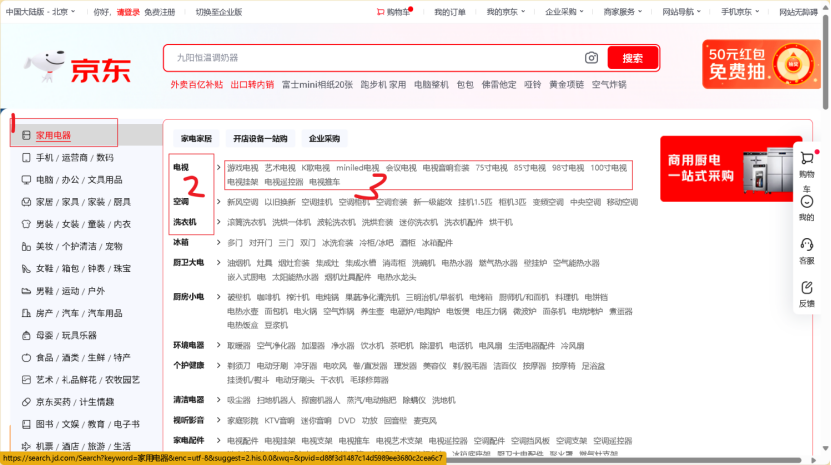
根据这张图,你猜猜后台的数据库中到底是几张表?
没错,这实际上就是一张表,那怎么才能让它数据不冗余呢?我用表格来演示一下:
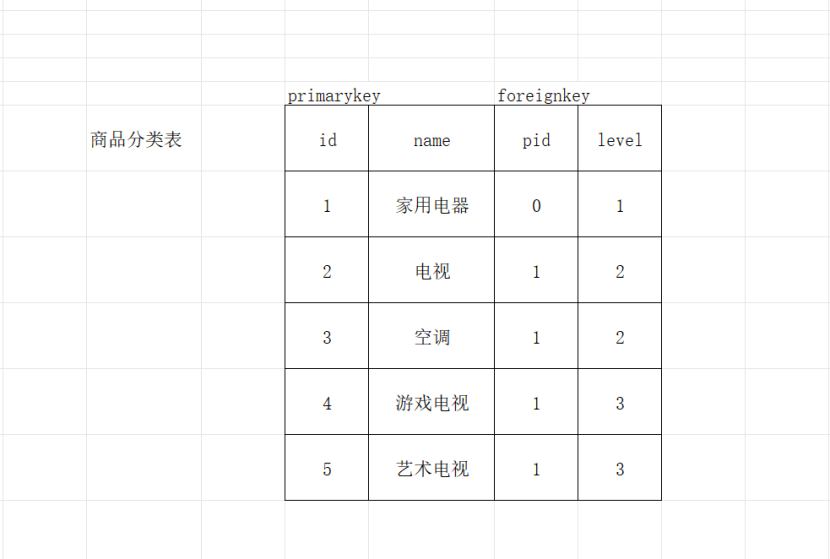
首先明确一点:当数据之间存在父子关系或者层级结构的时候才能使用自连接。
pid就是指向父级的id,使用level来分层,我们通过这种自连接的方式可以高效处理任意级别深度的数据(树状数据)。
优势分析:
动态更新:上级变动无需批量修改下级记录
无限层级:支持任意深度的商品层级结构
数据权威:保证信息唯一来源
三、多对多关系处理
冗余示例:
学生选课表:
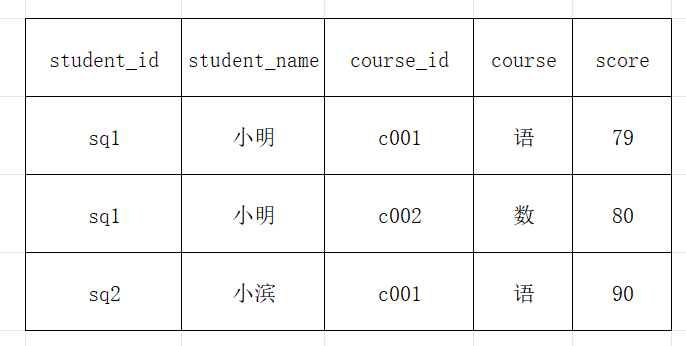
(学生姓名和课程名称重复存储)
规范化设计
中间表机制:通过关联表解耦多对多关系
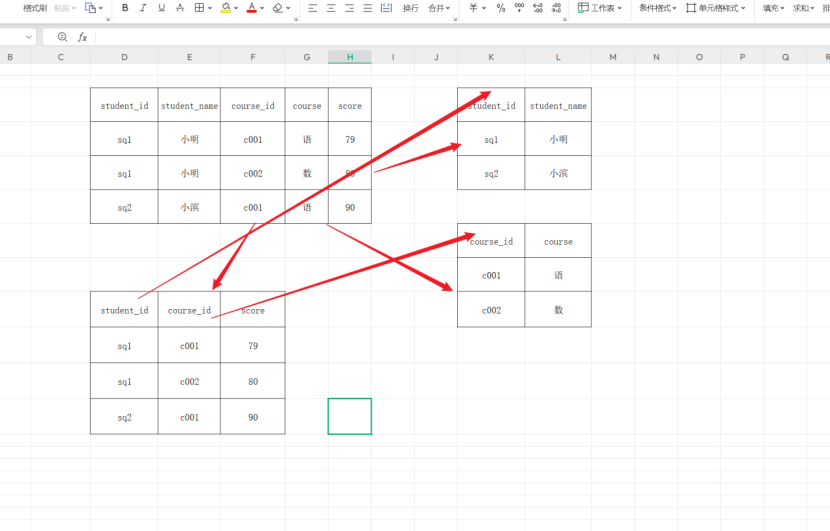
那么主键和外键怎么联立,关键点就在中间表,中间表设置多个外键,和其他表的主键联立。
优势分析:
存储效率:消除交叉重复,节省空间达60%+
修改安全:课程/学生信息变更不影响历史记录
扩展灵活:轻松支持附加字段(如选课时间、授课教师等)
最佳实践总结:
核心原则:第三范式(3NF)是基础要求
设计步骤:
识别实体 → 建立主表
分析关系 → 确定外键
处理多对多 → 创建关联表
例外情况:在高并发查询场景可适度反范式化
平衡艺术:在存储效率与查询性能间找到平衡点
经验法则:当发现自己在重复输入相同数据时,就该考虑是否需要重构表结构了。良好的数据库设计就像乐高积木——每个零件都独一无二,但能组合出无限可能


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









