






一、Qwen3:大模型赛道的破局者
1. 划时代的开源发布
2025年4月29日,阿里通义千问团队正式推出Qwen3系列大模型,包含两大架构:
- MoE(混合专家)模型:旗舰版Qwen3-235B-A22B(2350亿总参数/220亿激活参数)、轻量级Qwen3-30B-A3B(30亿总参数/3亿激活参数)
- Dense(密集)模型:覆盖0.6B、1.7B、4B、8B、14B、32B六大版本,形成从端侧到云端的全场景覆盖
此次开源采用Apache 2.0协议,支持119种语言交互,开发者可免费商用并二次开发,被业界誉为“中国AI生态的里程碑”。
2. 性能全面碾压DeepSeek R1与OpenAI o1
(1)基准测试对比
| 模型 | 数学能力(AIME25) | 代码能力(LiveCodeBench) | 综合推理(ArenaHard) | 部署成本(H20 GPU卡数) |
|---|---|---|---|---|
| Qwen3-235B-A22B | 81.5 | 70.8 | 95.6 | 4张(50万) |
| DeepSeek-R1(671B) | 78.2 | 66.7 | 89.3 | 16张(200万) |
| OpenAI-o1 | 79.8 | 68.4 | 94.1 | 闭源/按API调用收费 |
(2)核心优势
- 成本革命:旗舰模型Qwen3-235B-A22B的推理成本仅为DeepSeek-R1的25%-35%。以4张H20 GPU即可部署满血版,显存占用降低67%
-
语言理解与生成:在各类自然语言处理任务中表现出色,如文本生成、问答系统、摘要提取等。它能够理解复杂的语义和上下文信息,生成逻辑连贯、内容丰富的文本。
-
代码能力:在代码生成、代码补全、代码解释等方面表现优异,能够根据用户的需求生成高质量的代码,并且可以对代码进行详细的解释和优化。
- 混合推理机制:国内首个支持思考模式(Chain-of-Thought)与快速响应模式无缝切换的模型,复杂问题推理速度提升3倍,简单问题响应延迟<0.5秒
- 多模态与Agent能力:原生支持MCP协议,在工具调用(Function Call)评测中创下70.76分新高,远超DeepSeek-R1的56.9分
二、为什么选择Qwen3?
1. 与竞品的本质差异
| 维度 | Qwen3 | DeepSeek R1 | OpenAI o1 |
|---|---|---|---|
| 架构创新 | 动态MoE+密集混合架构 | 纯MoE架构 | 闭源黑盒架构 |
| 部署灵活性 | 支持端侧到超算集群部署 | 仅适合企业级服务器 | 仅限API调用 |
| 多语言支持 | 119种语言(含方言) | 主攻中英文 | 主流语言 |
| 安全可控性 | 提供端到端加密与私有化部署方案 | 依赖第三方安全方案 | 数据出境风险 |
2. 开发者友好特性
- 轻量化适配:Qwen3-4B量化版可在手机端实现30 tokens/s的推理速度
- 工具链生态:预集成Ollama、vLLM、LMStudio等工具链,一行代码实现模型加载
- 企业级支持:海光DCU已完成全系列模型深度调优,保障金融、医疗等场景的合规部署
3. 应用场景
-
智能客服:能够快速准确地理解用户的问题,并提供详细的解决方案,提高客户服务的效率和质量。
-
内容创作:可以辅助作家、记者等进行文章创作、故事编写等工作,提供创意灵感和语言表达支持。
-
教育领域:作为智能学习助手,为学生提供答疑解惑、知识讲解等服务,帮助学生更好地理解和掌握知识。
-
科研工作:在学术研究中,能够协助科研人员进行文献检索、数据分析、论文写作等工作,提高科研效率。
三、环境准备与资源配置
1. 平台注册与实例创建
- 账号注册:访问星海智算云官网 ,完成实名认证并开通AI算力服务,新用户可获50元体验券(含20元支付券+30元客服专享券)。
- 星海智算-GPU算力云平台
 https://gpu.spacehpc.com/user/register?inviteCode=29460209
https://gpu.spacehpc.com/user/register?inviteCode=29460209 - 镜像选择:在控制台选择「Qwen3-预装镜像」,内置PyTorch 2.3、CUDA 12.1、Ollama等工具链,无需手动安装依赖。
2. 操作步骤
① 从官网进入平台
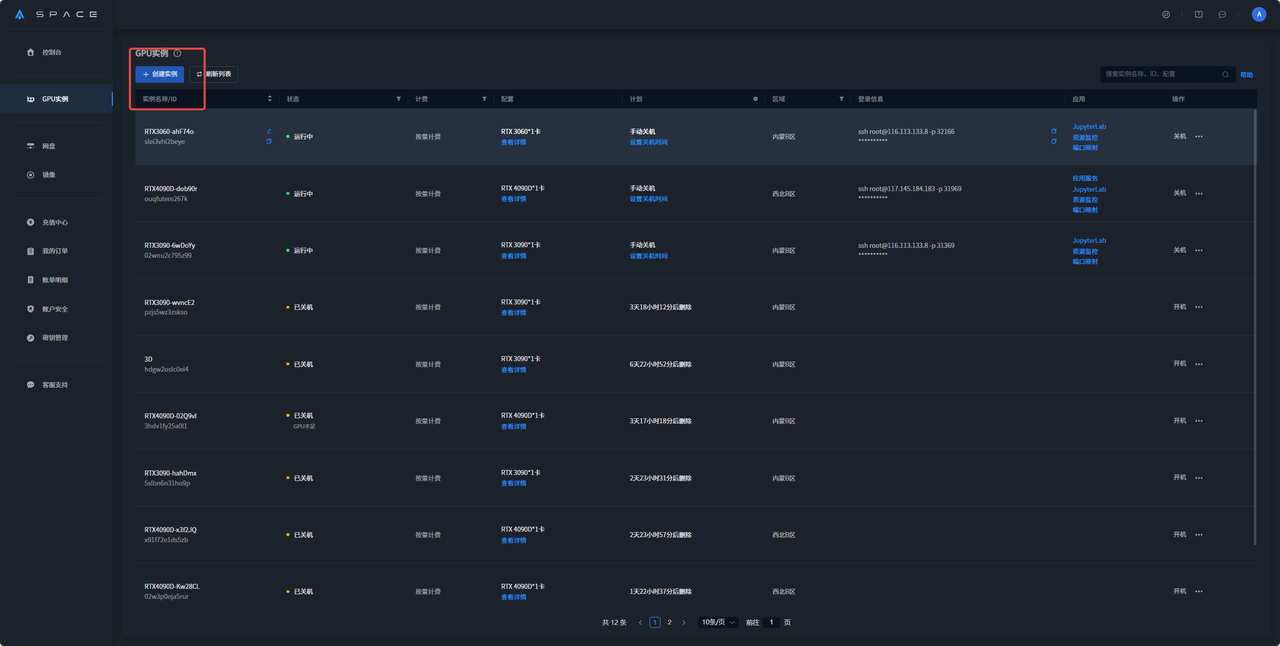
② 在GPU实例界面中选择创建实例
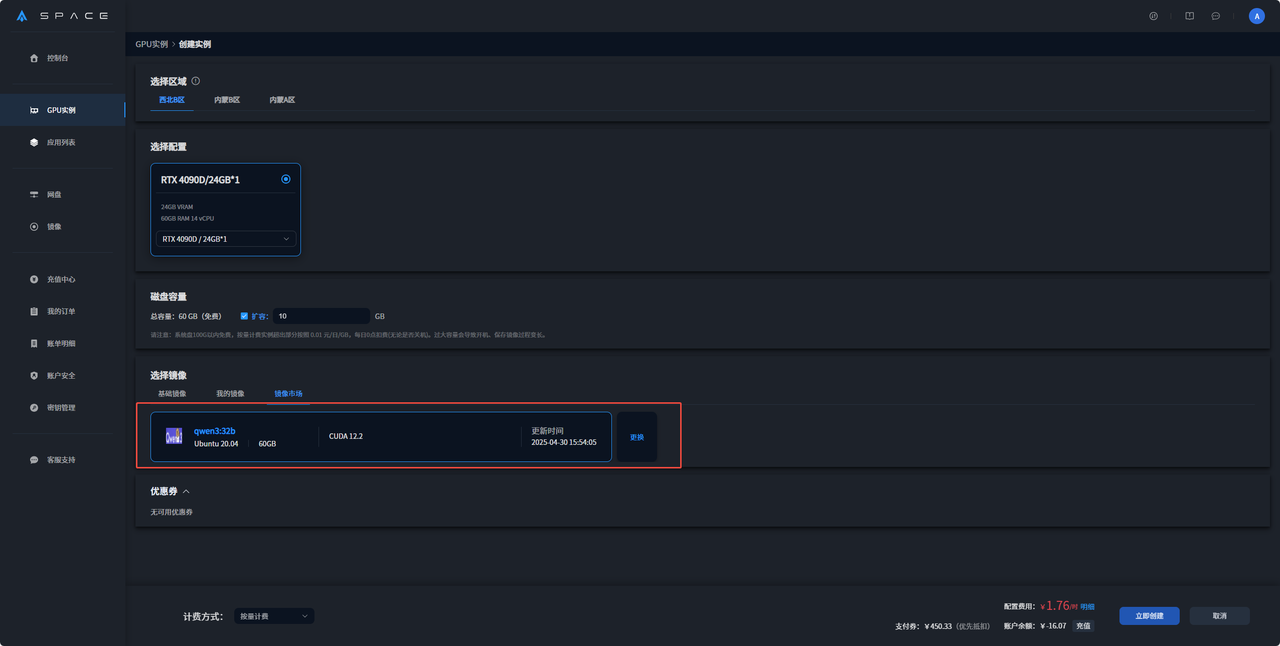
③ 选择好所在区域、所需配置、计费方式后在镜像市场搜索qwen3:32b
④ 待开机后,启动应用服务 (刚开机后点击启动若是出现502问题,请关闭页面等2-3分钟后再重新启动服务)

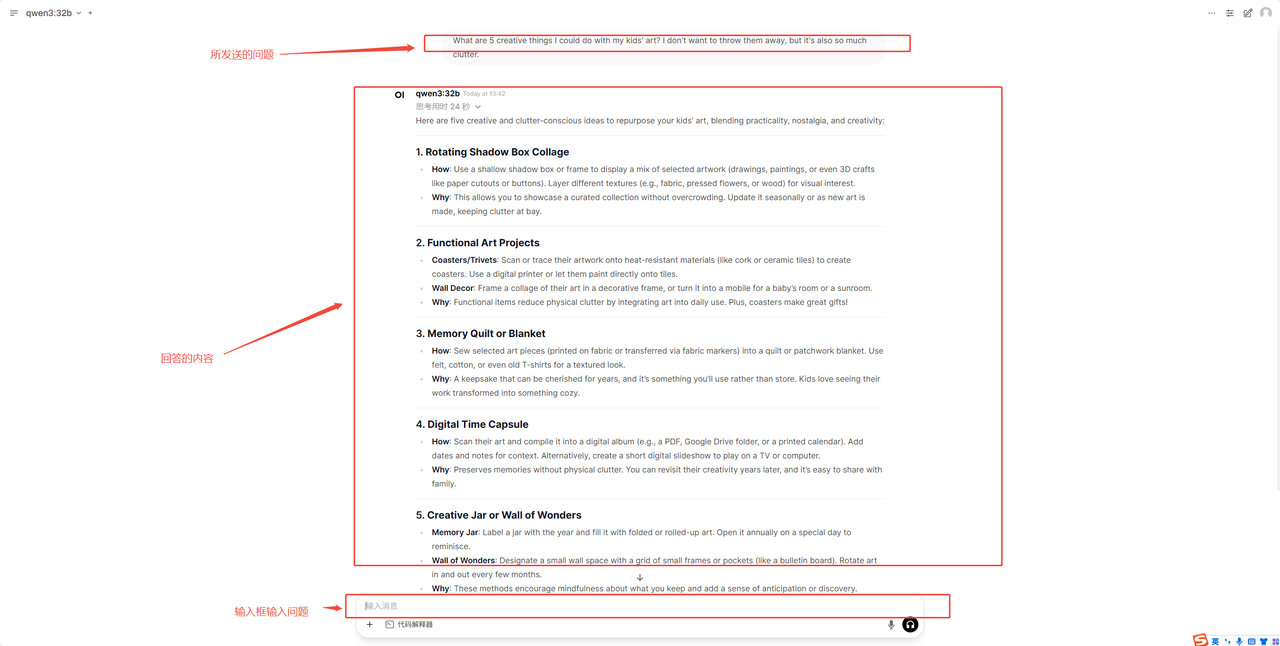
打开后界面如下
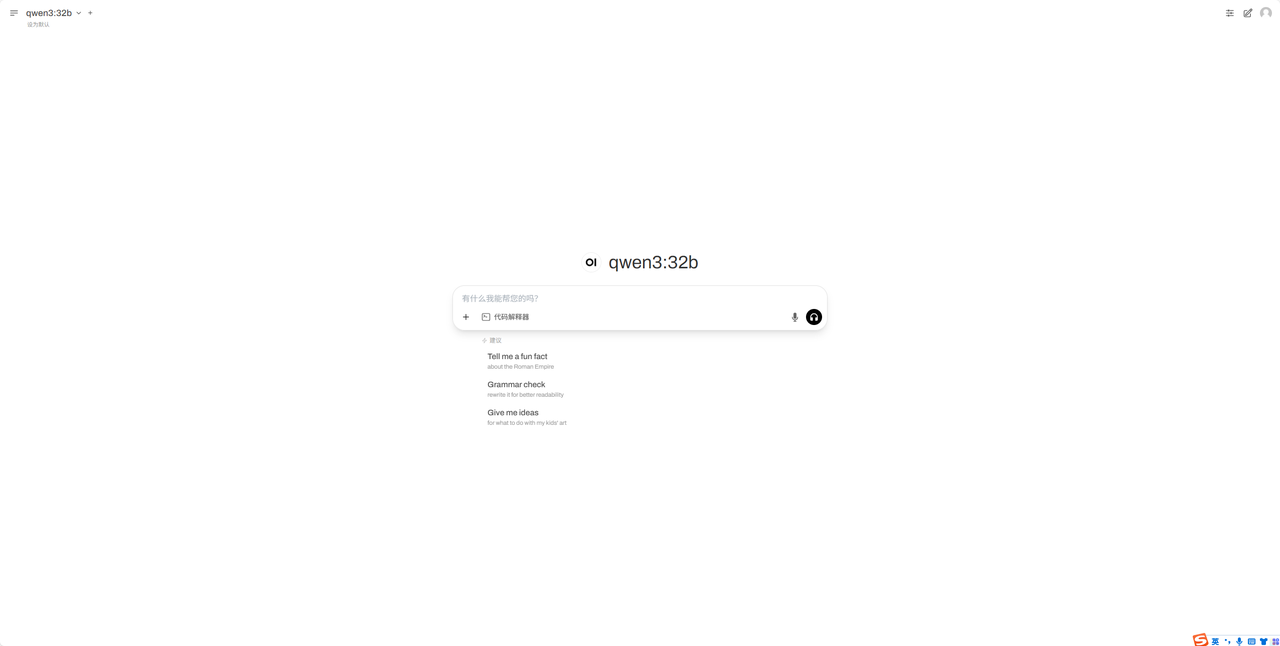
⑤ 在对话框中输入想要提问的文字并回车发送(首次发送需要等待模型加载完成1-2分钟)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









