






在页面端创建数据集#
1、创建数据集前需要先登陆,点击页面右上角的个人头像,选择创建数据集#
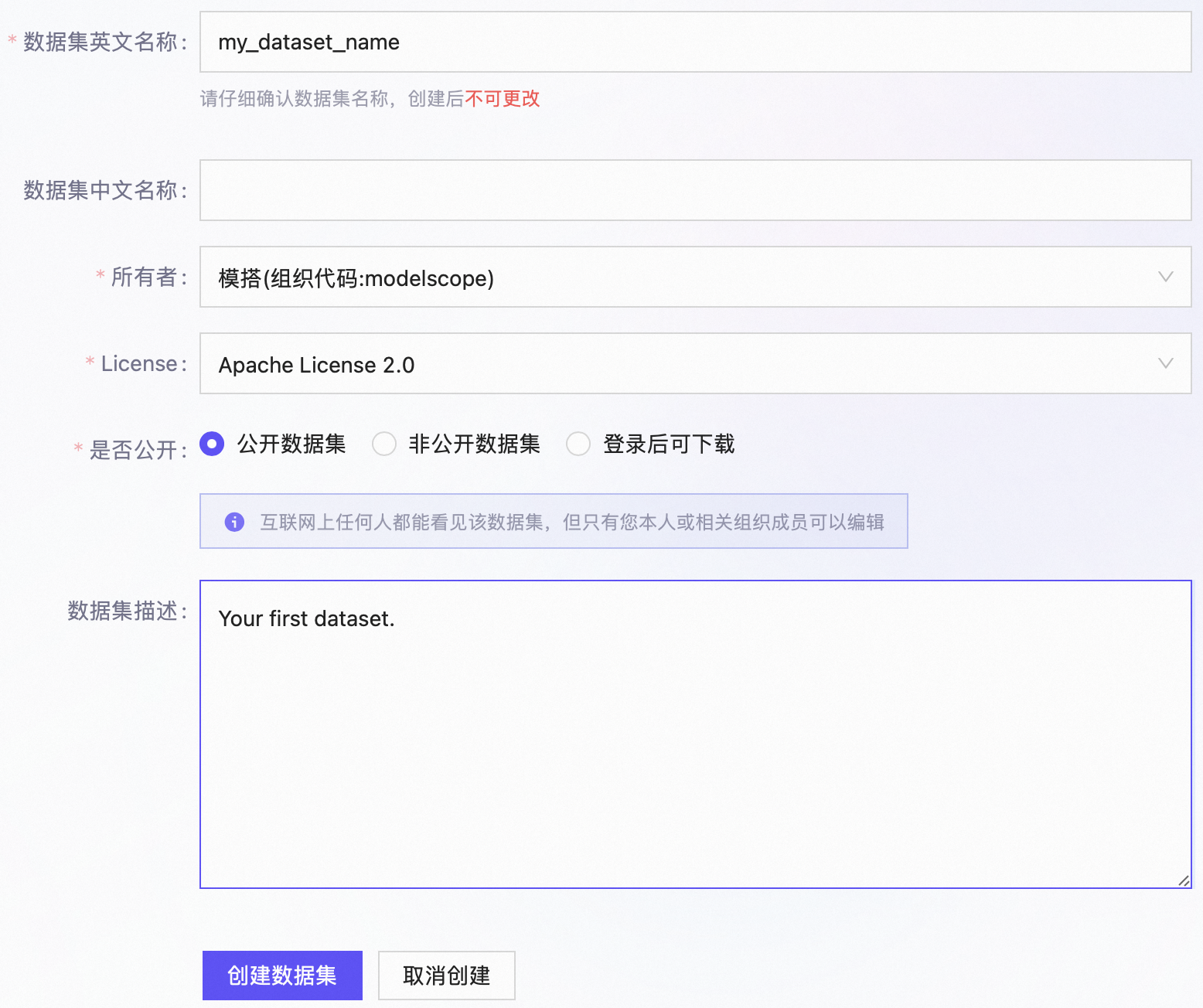
2、填入必要的数据集信息#
3、空白数据集创建完毕:#
4、准备数据#
数据集的组织形式参考下文中的组织您的数据集仓库章节,同时我们也提供了一些参考示例。
5、数据集上传#
点击数据集文件标签页,上传数据集文件,参考数据集的上传。
组织您的数据集仓库#
在modelscope创建一个数据集仓库后,本指南将指导您如何在上传时组织您的数据集仓库。
具有良好结构和特定文件格式(如 .txt、.csv、.parquet、.jsonl、.mp3、.jpg、.zip 等)的数据集会通过 MsDataset 自动加载,并且在的数据集页面上会有数据预览。
基础案例#
最简单的数据集结构包含两个文件:train.csv 和 test.csv。您的仓库还应包含一个 README.md 文件,用于展示在数据集页面上的数据集卡片。
my_dataset_repository/
├── README.md
├── train.csv
└── test.csv
在这个简单的案例中,您将获得一个包含两个拆分(split)的数据集:train(来自 train.csv 的样本)和 test(来自 test.csv 的样本)。
在 YAML 中定义拆分和子集#
拆分(split)#
如果您有多个文件并希望定义哪些文件属于哪个拆分,您可以在 README.md 顶部的 YAML 区块中使用 configs 字段。例如,给定一个如下的仓库:
my_dataset_repository/
├── README.md
├── data.csv
└── holdout.csv
您可以通过在 README.md 顶部的 YAML 块中添加 configs 字段来定义您的拆分:
---
configs:
- config_name: default
data_files:
- split: train
path: "data.csv"
- split: test
path: "holdout.csv"
---
您可以通过路径列表选择多个文件作为一个拆分:
my_dataset_repository/
├── README.md
├── data/
│ ├── abc.csv
│ └── def.csv
└── holdout/
└── ghi.csv
---
configs:
- config_name: default
data_files:
- split: train
path:
- "data/abc.csv"
- "data/def.csv"
- split: test
path: "holdout/ghi.csv"
---
您也可以使用通配符模式自动列出所需的所有文件:
---
configs:
- config_name: default
data_files:
- split: train
path: "data/*.csv"
- split: test
path: "holdout/*.csv"
---
注意: 即使您只有一个配置,
config_name字段也是必需的。
配置#
如果您的数据集有多个子数据集,希望能够分别加载它们,您可以在 YAML 的 configs 字段中定义一个配置列表:
my_dataset_repository/
├── README.md
├── main_data.csv
└── additional_data.csv
---
configs:
- config_name: main_data
data_files: "main_data.csv"
- config_name: additional_data
data_files: "additional_data.csv"
---
每个配置在上会在数据预览页面单独显示,可以通过传递其名称作为subset_name参数进行加载:
from modelscope import MsDataset main_data = MsDataset.load("my_dataset_repository", subset_name="main_data") additional_data = MsDataset.load("my_dataset_repository", subset_name="additional_data")
构建器参数#
不仅可以通过 YAML 传递 data_files,还可以传递其他构建器特定的参数,从而在加载数据时提供更多灵活性。比如,可以定义在何种配置中使用何种分隔符加载 csv 文件:
---
configs:
- config_name: tab
data_files: "main_data.csv"
sep: "\t"
- config_name: comma
data_files: "additional_data.csv"
sep: ","
---
提示: 您可以通过使用
default: true设置默认配置,例如,如果设置- config_name: main_data data_files: "main_data.csv" default: true那么可以使用
main_data = MsDataset.load("my_dataset_repository")加载数据集。
自动拆分检测#
如果没有提供 YAML,系统会自动根据数据集仓库中的特定模式推断数据集拆分。模式的优先顺序是首先尝试自定义文件名拆分格式,如果没有找到,则将所有文件视为单一拆分。
文件夹名称#
您可以将数据文件放入名为 train、test 和 validation 的不同目录中,每个目录包含该拆分的数据文件:
my_dataset_repository/
├── README.md
└── data/
├── train/
│ └── bees.csv
├── test/
│ └── more_bees.csv
└── validation/
└── even_more_bees.csv
文件名拆分#
如果您没有使用任何非传统拆分,则可以将拆分名称放置在数据文件的任何位置,系统会自动推断。唯一的规则是,拆分名称必须由非字母数字字符分隔,例如,test-file.csv 合法,而 testfile.csv 不合法。支持的分隔符包括下划线、短横线、空格、点和数字。
例如,以下文件名都是可以接受的:
- 训练集拆分:
train.csv、my_train_file.csv、train1.csv - 验证集拆分:
validation.csv、my_validation_file.csv、validation1.csv - 测试集拆分:
test.csv、my_test_file.csv、test1.csv
例如,所有文件放在一个名为 data 的目录中的结构如下:
my_dataset_repository/
├── README.md
└── data/
├── train.csv
├── test.csv
└── validation.csv
自定义文件名拆分#
如果您的数据集拆分有自定义名称(例如,既不是 train、test、也不是 validation),可以将您的数据文件命名为 data/<split_name>-xxxxx-of-xxxxx.csv。
示例如下,包含三个拆分:train、test 和 random:
my_dataset_repository/
├── README.md
└── data/
├── train-00000-of-00003.csv
├── train-00001-of-00003.csv
├── train-00002-of-00003.csv
├── test-00000-of-00001.csv
├── random-00000-of-00003.csv
├── random-00001-of-00003.csv
└── random-00002-of-00003.csv
单一拆分#
当系统无法识别上述任何模式时,则会将所有文件视为单个训练拆分。如果数据集拆分未按预期加载,可能是由于模式不正确。
拆分名称关键字#
拆分名称有多种方式命名。验证集拆分有时被称为 "dev",测试集拆分可能称为 "eval"。这些其他名称也受到支持,以下关键字是等价的:
- train, training
- validation, valid, val, dev
- test, testing, eval, evaluation
以下结构是一个有效的仓库:
my_dataset_repository/
├── README.md
└── data/
├── training.csv
├── eval.csv
└── valid.csv
每个拆分多个文件#
如果某个拆分包含多个文件,系统仍然可以根据文件名推断这是训练、验证还是测试拆分。例如,如果您的训练集和测试集跨多个文件:
my_dataset_repository/
├── README.md
├── train_0.csv
├── train_1.csv
├── train_2.csv
├── train_3.csv
├── test_0.csv
└── test_1.csv
确保 train 集的所有文件名称中都包含 train(验证集和测试集同理)。即使您在文件名中添加前缀或后缀(例如 my_train_file_00001.csv),系统仍然可以推断出相应的拆分。
为了方便,您还可以将数据文件放入不同的目录中。在这种情况下,拆分名称从目录名称推断。
my_dataset_repository/
├── README.md
└── data/
├── train/
│ ├── shard_0.csv
│ ├── shard_1.csv
│ ├── shard_2.csv
│ └── shard_3.csv
└── test/
├── shard_0.csv
└── shard_1.csv
通过按照上述结构组织仓库,您将能够轻松上传并使用数据集,而且在数据仓库里有数据预览。
(可选)使用python脚本组织数据集#
在数据集仓库中,可以定义一个与数据仓库同名的python脚本,用于组织数据集
my_dataset/ ├── README.md ├── my_dataset.py └── data/ # optional ├── a1.csv or a1.json or a1.parquet or a1.zip └── a2.csv or a2.json or a2.parquet or a2.zip

















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









