







目录
(1)LSB替换法(Least Significant Bit Substitution)
(3)频域隐写法(Frequency Domain Steganography)
(1)自适应隐写(Adaptive Steganography)
(一)研究背景
1.隐写术的定义
随着信息技术以前所未有的速度迅猛发展,信息安全问题正以日益复杂和严峻的态势呈现在人们面前。从个人隐私数据的泄露到国家机密的窃取,从商业情报的非法获取到恶意软件的传播,信息安全已成为关乎国家安全、社会稳定和个人权益的重要议题。信息隐藏技术作为保障信息安全的重要手段之一,凭借其独特的技术优势和创新理念,在近年来得到了学术界和产业界的广泛关注。其中,隐写术(Steganography)作为信息隐藏技术的核心分支,是一种将秘密信息巧妙地嵌入到普通媒介中,使其在传输和存储过程中不被轻易察觉的技术。这种技术不仅广泛应用于图像、音频、视频等多媒体数据中,还在军事通信、数字版权保护、电子商务等多个领域发挥着至关重要的作用。
2.声音文件隐写技术
在各类隐写技术中,声音文件隐写技术凭借其显著的特性脱颖而出,成为信息安全领域的重要研究方向。一方面,声音文件具有极强的隐蔽性,由于人耳对音频信号中的细微变化存在感知局限,使得秘密信息的嵌入几乎难以被察觉;另一方面,音频数据本身的数据量较大,能够承载更多的秘密信息,具备较高的嵌入容量;此外,声音作为一种常见的信息载体,广泛存在于网络通信、语音通话、广播媒体等日常场景中,其传输过程自然流畅,不易引起怀疑。因此,利用声音文件进行隐写不仅具有极高的实用价值,能够满足特殊场景下的秘密通信需求,同时也存在潜在威胁,可能被不法分子用于非法信息的传播。
3.隐写技术相比传统声音加密的优势
传统的声音加密主要依赖于密码学技术,诸如 AES(高级加密标准)、RSA 等对称或非对称加密算法。这些加密算法通过复杂的数学运算对信息进行加密处理,能够有效保障信息的机密性和完整性,在一定程度上抵御攻击者的破解。然而,这些方法虽然安全性高,但存在一个明显的缺陷,即无法掩盖信息的存在性。加密后的信息往往呈现出不同于正常数据的特征,容易引起攻击者的注意,从而成为被攻击的目标。而隐写技术则另辟蹊径,它可以在不改变载体感知质量的前提下,将敏感信息 “藏” 入普通的音频文件中,使秘密信息与正常音频数据融为一体,从根本上掩盖了信息的存在,从而达到更高的隐蔽性,有效避免引起外界的怀疑。
4.隐写检测技术在近年来的发展
近年来,随着人工智能和大数据技术的飞速发展,隐写检测(Steganalysis)技术也取得了显著进展。基于深度学习的隐写检测模型,如卷积神经网络(CNN)和循环神经网络(RNN),能够自动提取隐写特征,对隐写信息进行精准识别和分析。这些先进的检测技术使得传统的隐写方法面临新的挑战,以往简单的隐写手段逐渐失去优势,难以逃避检测。因此,在当前技术环境下,研究高效、安全且具备抗检测能力的声音文件隐写技术,不仅能够推动信息隐藏领域的理论创新,还能为实际应用提供可靠的技术支撑,具有重要的理论意义和现实应用价值。
(二)声音隐写技术介绍
1.隐写技术的基本要求
一个有效的声音文件隐写系统应满足以下基本要求:
不可感知性(Imperceptibility):嵌入的秘密信息不应影响音频的听觉效果,即人耳无法察觉音频的变化。
鲁棒性(Robustness):隐写后的音频在经过压缩、滤波、格式转换等常见处理后,仍能保留嵌入的信息。
容量(Capacity):能够嵌入的数据量尽可能大,以满足实际应用需求。
安全性(Security):隐写过程应具备一定的抗检测能力,防止被隐写分析工具识别并提取出隐藏信息。
2.当前存在的问题
尽管声音文件隐写技术在过去数十年间积累了丰富的理论成果与实践经验,众多学者通过优化算法、改进模型等方式推动其不断发展,但在实际应用场景中,这一技术仍面临着诸多亟待解决的关键问题。
隐蔽性与容量之间的矛盾:隐蔽性与容量之间的矛盾始终是困扰声音文件隐写技术发展的核心难题。从信息嵌入的本质来看,秘密信息的嵌入必然会对原始音频信号造成一定程度的改变。通常来说,若为提高嵌入容量而增加单位音频数据中携带的秘密信息量,就不可避免地会导致音频信号失真程度增加,这种失真可能表现为细微的噪声、音调变化或频率异常,从而降低隐蔽性,使得隐藏信息更容易被发现;反之,若为追求极致的隐蔽性,采取更为保守的嵌入策略,严格限制对音频信号的修改幅度,则可能极大地限制了可嵌入的信息量,难以满足实际应用中对大容量秘密传输的需求。
易受隐写分析攻击:声音文件隐写技术面临着日益严峻的隐写分析攻击威胁。随着机器学习和深度学习技术的迅猛发展,隐写分析领域迎来了革命性的突破。基于深度神经网络的隐写分析工具不断涌现,这些工具能够自动从海量音频数据中学习隐写特征,通过对音频信号的时域、频域、变换域等多维度特征进行深度挖掘与分析,实现对隐藏信息的精准检测。与传统的人工分析方法相比,这些智能隐写分析工具不仅检测效率大幅提升,而且检测精度也达到了前所未有的高度。在这种情况下,许多传统的隐写方法逐渐失去了安全性优势,其隐藏的信息极易被检测和破解,使得声音文件隐写技术在实际应用中的安全性面临巨大挑战。
兼容性和格式依赖性:兼容性和格式依赖性问题严重制约了声音文件隐写技术的广泛应用。在数字音频领域,存在着多种不同的音频编码格式,如未经压缩的WAV格式、广泛应用的有损压缩格式MP3、具有更高压缩效率的AAC格式等。由于每种音频编码格式的编码原理、数据结构和压缩特性各不相同,它们对隐写操作的影响也存在显著差异。某些隐写方法是基于特定音频格式的特性设计的,只能适用于特定格式,一旦应用于其他格式的音频文件,可能会导致隐藏信息丢失、音频文件损坏或隐写效果大幅下降。
实时性差:实时性差也是声音文件隐写技术在实际应用中面临的一大瓶颈。部分隐写算法为了追求更高的隐蔽性、鲁棒性或嵌入容量,采用了复杂的数学模型和计算方法,导致算法的计算复杂度大幅增加。在处理音频数据时,这些算法需要耗费大量的计算资源和时间进行信息嵌入和提取操作,难以满足流媒体、实时语音通话等对实时性要求极高的通信场景的需求。
3.声音隐写技术的原理和实现
3.1声音文件隐写的基本原理
声音文件隐写的核心思想是利用音频信号中存在的冗余空间来嵌入秘密信息。根据音频信号的特性,常见的隐写方法可分为以下几类:
(1)LSB替换法(Least Significant Bit Substitution)
这是最经典的音频隐写方法之一。其基本原理是将音频采样值的最低有效位(LSB)替换为秘密信息的二进制位。由于LSB对音频信号的影响非常小,因此在大多数情况下不会引起人耳的察觉。
例如,假设有一个16位PCM音频样本值为 01100110 10100100,如果要嵌入一位信息 1,只需将其最后一位改为 1,变为 01100110 10100100 → 01100110 10100101(最后一位变化)。这样的修改几乎不会影响原始音频的感知质量。
优点:实现简单、嵌入容量大。
缺点:容易被统计分析检测出来,对音频处理操作(如压缩)敏感。
(2)回声隐藏法(Echo Hiding)
该方法通过在音频信号中添加微弱的回声来表示隐藏信息。回声的时间延迟和强度可以用来表示不同的比特值。
例如,若在某段音频中加入一个延迟为3ms、振幅较低的回声,可以表示比特“1”,否则表示“0”。由于人类听觉系统对微弱回声不敏感,这种方法具有较好的隐蔽性。
优点:抗压缩能力强、不易被察觉。
缺点:嵌入容量有限、实现较为复杂。
(3)频域隐写法(Frequency Domain Steganography)
将音频信号从时域变换到频域(如使用FFT或DCT),然后在频域系数中嵌入信息。常用的方法包括在低频区域修改系数大小,或者在相位信息中隐藏数据。
优点:更适合对抗隐写分析、具有良好的鲁棒性。
缺点:计算复杂度较高、需要较高的信号处理知识。
(4)基于语音编码的隐写方法
针对语音通信场景,可在语音编码器内部进行信息隐藏。例如,在G.711、G.729等语音编码标准中,某些参数(如增益、索引等)可用于携带隐藏信息。
优点:适用于实时语音通信、不改变语音结构。
缺点:容量较小、需要了解编码标准细节。
3.2现代改进方法与抗检测策略
为了提升隐写的隐蔽性和抗检测能力,研究人员提出了多种改进方法:
(1)自适应隐写(Adaptive Steganography)
自适应隐写技术根据音频内容的局部特征选择合适的位置进行信息嵌入。例如,在音频信号变化剧烈的地方嵌入信息,可以减少被检测的可能性。
(2)基于深度学习的隐写模型
近年来,基于生成对抗网络(GAN)和自动编码器(Autoencoder)的隐写模型逐渐兴起。这些模型可以通过训练,使隐写过程更加智能化,提高隐蔽性和抗检测能力。
例如,使用GAN模型训练一个“伪装器”,使得嵌入后的音频与原始音频在统计分布上高度相似,从而绕过隐写分析工具的检测。
(3)多通道/立体声隐写
利用双声道或多声道音频中的冗余信息进行跨通道隐写。例如,在左声道中嵌入信息,右声道保持不变,或将信息分散嵌入多个通道中,增强隐蔽性。
(4)结合加密与隐写的混合方案
为了提高安全性,常将隐写与传统加密相结合。例如,先对信息进行AES加密,再将密文嵌入音频中,即使被检测出隐藏信息,也无法直接解密获取明文。
3.3应用场景
军事与情报通信:在敌方监听环境下,通过隐写技术传递敏感信息,避免暴露通信行为本身。
数字水印与版权保护:在音乐作品中嵌入水印信息,用于标识作者、版权归属或追踪盗版传播路径。
商业机密保护:企业可通过音频隐写在内部通信中传输保密资料,防止被第三方窃取。
网络安全攻防演练:在红蓝对抗中,攻击者可利用隐写技术逃避入侵检测系统(IDS)的监测。
3.4使用方法
目前市面上已有多种支持音频隐写功能的软件和工具,以下是几种常用的实现方式:
(1)开源工具推荐
Steghide:支持多种音频格式(如WAV、AU),可将文本或文件隐藏在音频中。
OpenStego:提供图形界面,支持图像与音频隐写。
Hide and Seek (HNS):专为音频设计的隐写工具,支持LSB和频域方法。
(2)编程实现
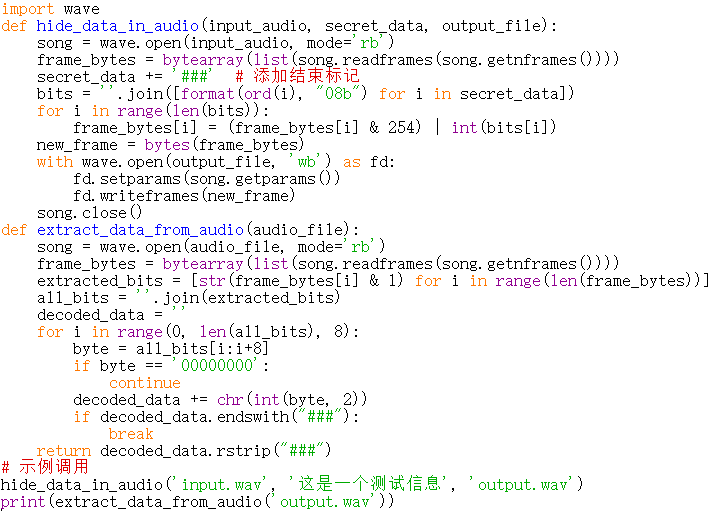
使用Python进行音频隐写的示例代码如下(基于LSB方法):
import wave
def hide_data_in_audio(input_audio, secret_data, output_file):
song = wave.open(input_audio, mode='rb')
frame_bytes = bytearray(list(song.readframes(song.getnframes())))
secret_data += '###' # 添加结束标记
bits = ''.join([format(ord(i), "08b") for i in secret_data])
for i in range(len(bits)):
frame_bytes[i] = (frame_bytes[i] & 254) | int(bits[i])
new_frame = bytes(frame_bytes)
with wave.open(output_file, 'wb') as fd:
fd.setparams(song.getparams())
fd.writeframes(new_frame)
song.close()
def extract_data_from_audio(audio_file):
song = wave.open(audio_file, mode='rb')
frame_bytes = bytearray(list(song.readframes(song.getnframes())))
extracted_bits = [str(frame_bytes[i] & 1) for i in range(len(frame_bytes))]
all_bits = ''.join(extracted_bits)
decoded_data = ''
for i in range(0, len(all_bits), 8):
byte = all_bits[i:i+8]
if byte == '00000000':
continue
decoded_data += chr(int(byte, 2))
if decoded_data.endswith("###"):
break
return decoded_data.rstrip("###")
# 示例调用
hide_data_in_audio('input.wav', '这是一个测试信息', 'output.wav')
print(extract_data_from_audio('output.wav'))编译器中效果:
(三)总结
声音文件隐写技术作为信息安全领域极具潜力的关键技术,凭借其独特的隐蔽通信特性,已在信息安全、数字水印、隐私保护等多个重要领域展现出广阔的应用前景。在信息安全领域,它能够实现秘密信息的隐蔽传输,为军事、情报等敏感通信场景提供可靠保障;在数字水印领域,通过将版权信息嵌入音频文件,有效防止数字内容的非法复制与盗用;在隐私保护方面,可将敏感数据隐藏于普通音频中,降低数据泄露风险。随着信息技术的持续革新,隐写技术与隐写分析技术之间的博弈也在不断加剧,二者如同“矛”与“盾”,在相互对抗中推动着技术的持续进步。
当前,主流的声音文件隐写方法呈现出多样化的特点,其中,LSB替换通过修改音频采样点的最低有效位实现信息嵌入,操作简单但抗攻击能力较弱;回声隐藏利用人耳对回声的不敏感特性,将秘密信息编码为回声信号,具有较好的隐蔽性,但嵌入容量有限;频域嵌入则是在音频的频域变换系数中隐藏信息,能够有效应对音频压缩等操作,但算法复杂度较高。这些方法各有优劣,适用于不同的应用场景。值得关注的是,现代隐写技术的研究正朝着自适应隐写、深度学习辅助隐写、多模态隐写融合等前沿方向发展。自适应隐写可根据音频信号的特性动态调整嵌入策略,在保证隐蔽性的同时提高嵌入效率;深度学习辅助隐写借助神经网络强大的特征学习能力,实现更高效、隐蔽的信息嵌入;多模态隐写融合则整合音频、图像等多种载体的优势,进一步增强隐写系统的性能,全方位提升隐写系统的隐蔽性、容量与安全性。
尽管声音文件隐写技术取得了显著进展,但在实际应用与技术发展中,仍然面临诸多亟待解决的挑战。例如,如何在保证隐蔽性不被破坏的前提下,最大限度地提高嵌入容量,以满足日益增长的秘密信息传输需求;面对不断涌现的先进隐写分析工具,如何增强隐写系统的抗检测能力,确保隐藏信息的安全性;由于音频格式种类繁多且特性各异,如何使隐写技术更好地适配各种音频格式,提高技术的通用性和实用性。展望未来,声音文件隐写技术的研究需要进一步深化与人工智能、量子加密等新兴技术的融合。借助人工智能强大的数据分析与处理能力,优化隐写算法;利用量子加密的绝对安全性,为隐写密钥管理提供更可靠的保障,从而推动隐写技术向更高层次迈进,为信息安全领域带来新的突破与发展。
(四)参考文献
《长久努力 构建信息安全防线》
《网络协议隐写检测技术的研究》
《多媒体隐写及隐写分析:基于深度学习的研究》
《基于分离卷积与GAN的高精度图像隐写解码》
《面向网络多媒体的音频隐写术应用》
《音频隐写方法综述:从传统到深度学习》
《基于DC-DM的小波域数字音频水印算法研究》
《基于音频载体的特定信息隐藏算法研究》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









