






随着在线购物的迅速增长,电子商务目前已占全球零售销售额的24%。到2025年,全球电子商务零售额预计将达到7.4万亿美元,反映了其对消费者行为日益增长的影响。
在韩国数字生态系统的核心,Naver作为该国领先的搜索引擎和技术巨头占据着重要地位。作为日常数字生活的基石,Naver整合了电子商务、数字支付解决方案、网络漫画、博客平台和移动消息服务等多种功能。这种广泛的服务使其能够比区域内任何其他平台收集更多领域的用户数据,进一步巩固了其在塑造国家在线格局中的关键角色。
如何快速、大规模且低成本地从Naver Shop抓取产品数据?
让我们现在来深入了解细节!
💡 我们可以从Naver提取哪些产品数据?
一个强大的Naver抓取工具可以提取广泛的数据字段,确保全面且最新的洞察。这些包括:
核心产品信息 :
- 产品名称
- 描述
- 图片
- 类别与子类别
- 品牌
- 产品ID
- SKU(库存单位)
- 重量/体积
定价与促销 :
- 原价
- 折扣价
- 折扣百分比
- 单价
- 促销活动
- 捆绑优惠
可用性与物流 :
- 库存状态
- 配送选项
- 配送时间
- 退货政策
- 商店位置
消费者洞察 :
- 客户评分
- 评论
- 卖家信息
- 截止日期
- 成分
- 营养信息
元数据 :
- 最后更新时间
- 类别/子类别
⚠️ 抓取Naver数据的挑战
尽管好处显而易见,但抓取Naver数据并非没有障碍。以下是企业必须应对的六大挑战:
-
缺乏稳定的入口点或会话控制
Naver要求一致的用户行为来进行会话验证。匿名抓取通常会引发怀疑,导致访问被封锁。 -
JavaScript渲染挑战
关键内容通常通过JavaScript动态加载。无法准确渲染JS的工具将错过重要数据。 -
会话验证、地理锁定和CAPTCHA
Naver采用多层保护措施,包括CAPTCHA和地理限制。如果没有强大的会话模拟和代理轮换,抓取工作可能很快失败。 -
频繁的布局更改
Naver经常更新其界面,改变分页逻辑、标签结构和加载顺序,这需要不断调整抓取工具。 -
速率限制和封锁
高请求量可能触发速率限制。有效的抓取需要行为模拟、多样化的访问协议和谨慎的节奏控制。 -
法律和监管合规
韩国拥有严格的数据隐私法。不合规可能导致法律风险和声誉损害,尤其是对于海外企业。
Naver抓取API:轻松提取Naver产品详情
如何操作
- 只需配置商店ID和产品ID。
- Scrapeless Naver API将从Naver Shop中提取详细的产品数据,包括价格、卖家信息、评论等。
- 您可以下载并分析数据。
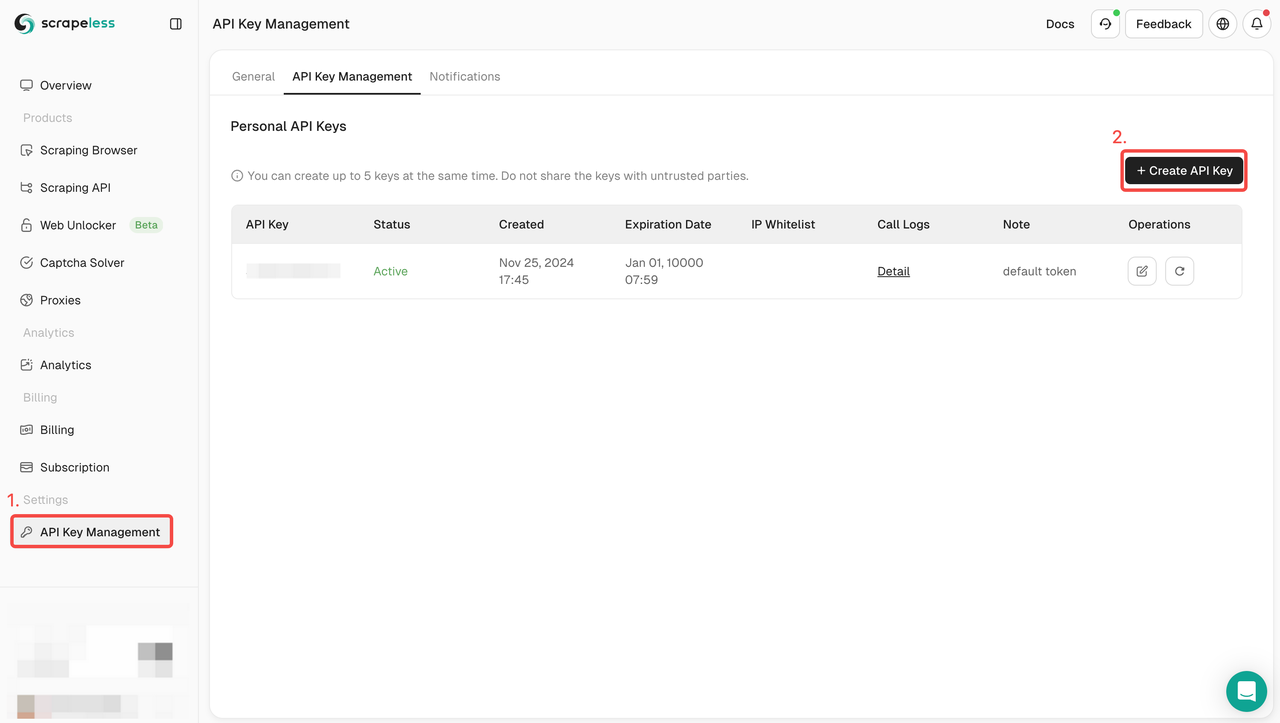
步骤1:创建您的API令牌
要开始使用,您需要获取API密钥:
- 登录Scrapeless仪表板。
- 导航到API密钥管理。
- 单击“创建”以生成您的唯一API密钥。
- 创建完成后,您可以单击API密钥进行复制。
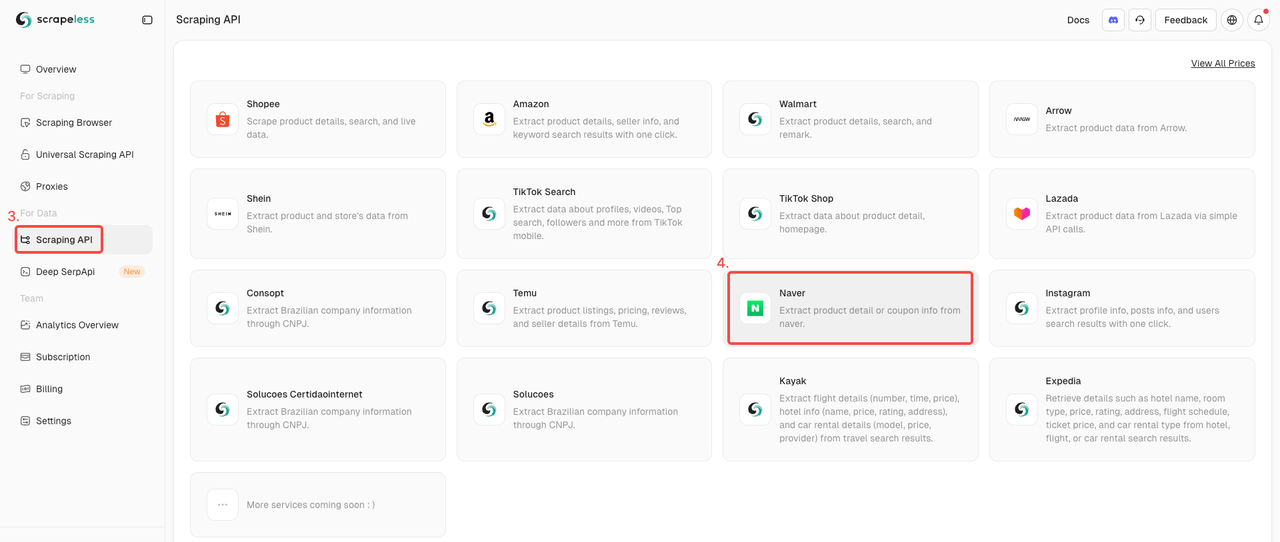
步骤2:启动Naver Shop API
- 在“数据收集”下找到抓取API。
- 单击Naver Shop 接口以准备抓取产品数据。
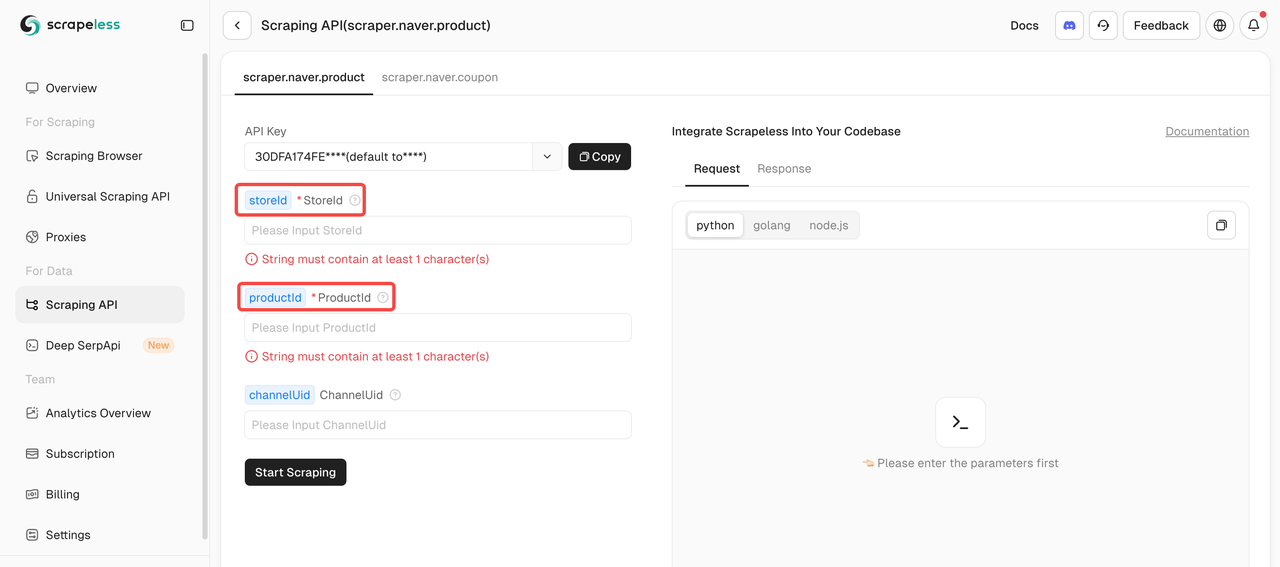
步骤3:确定目标
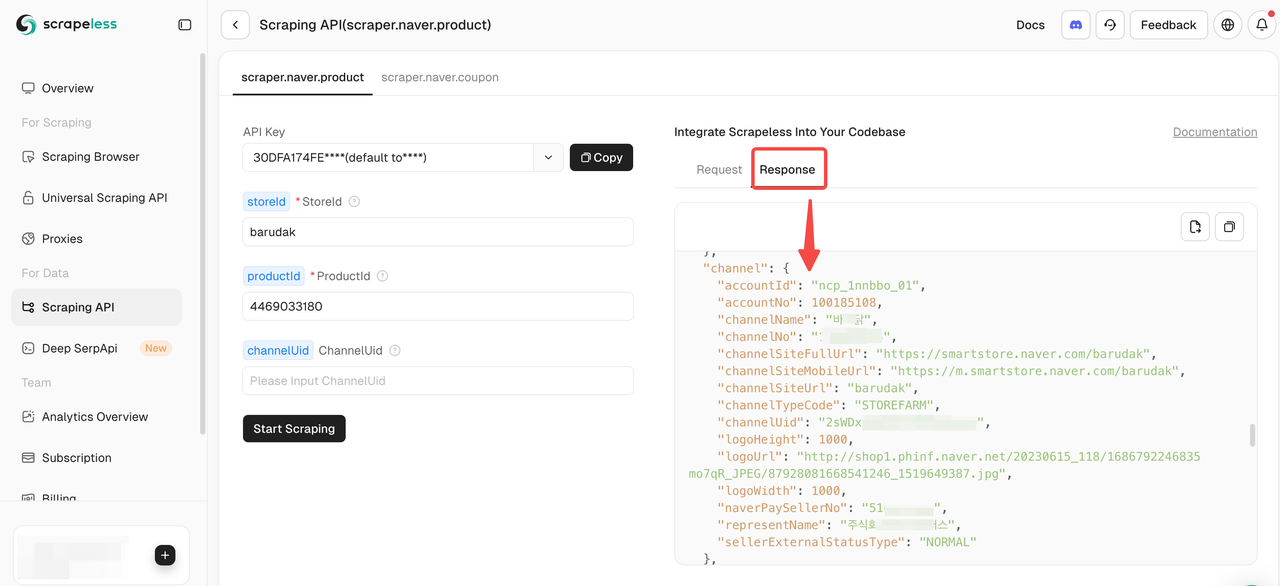
使用Naver抓取API抓取产品数据时,您必须提供两个必填参数:storeId 和 productId。channelUid参数是可选的。
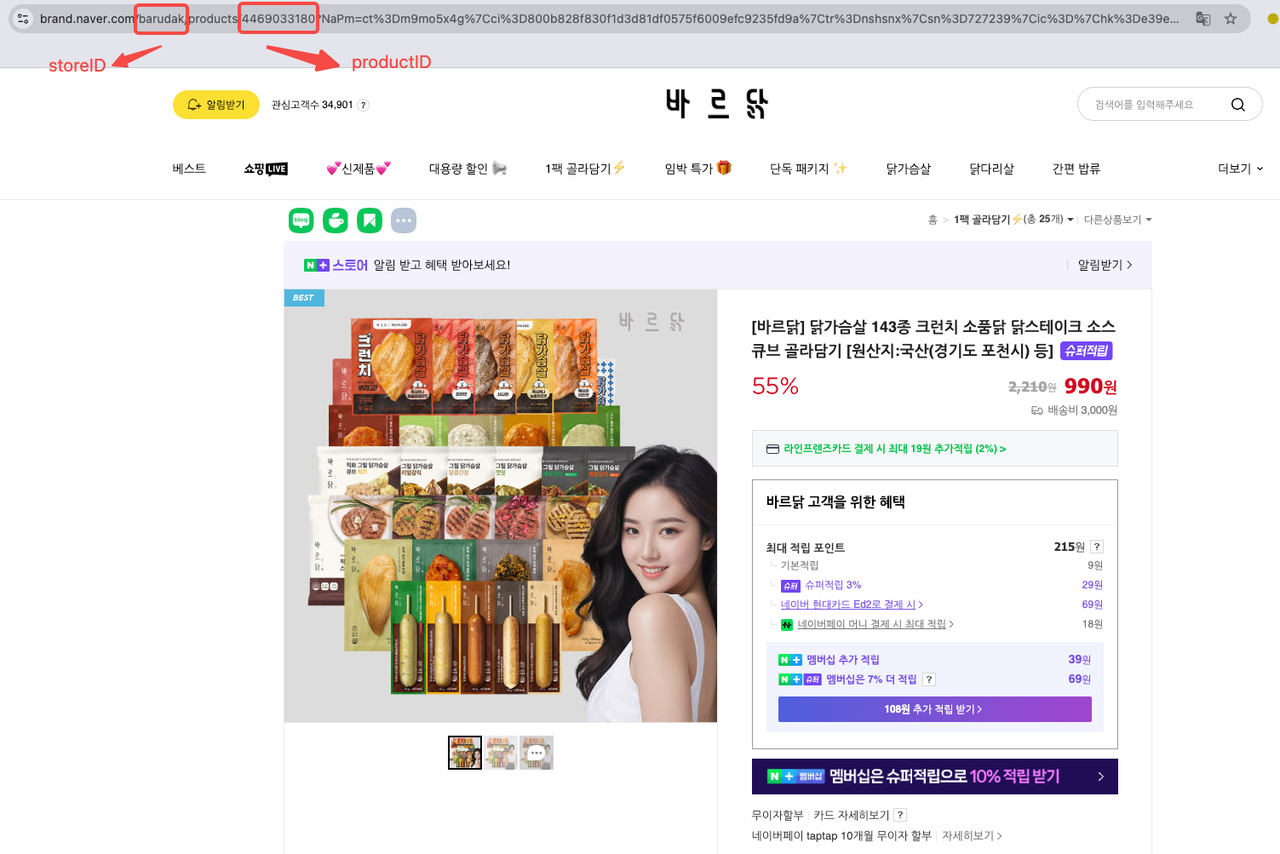
您可以在产品URL中直接找到产品ID和商店ID。例如,以[바르닭] 닭가슴살 143종 크런치 소품닭 닭스테이크 소스큐브 골라담기 [원산지:국산(경기도 포천시) 등]为例:
- 商店ID: barudak
- 产品ID: 4469033180
步骤4:开始抓取Naver产品数据
填写完所需参数后,只需单击“开始抓取”即可获取全面的产品数据。
以下是一个提取Naver产品数据的代码示例。只需将YOUR_SCRAPELESS_API_TOKEN替换为您的实际API密钥即可:
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUR_SCRAPELESS_API_TOKEN"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.naver.product",
"input": {
"storeId": "barudak",
"productId": "4469033180",
"channelUid": " " ## Optional
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()准备将您的业务提升到一个新的水平了吗?信任Scrapeless为您提供可操作的洞察,并简化您的数据提取流程。
关键要点
从Naver提取数据是一项具有战略意义的举措,可以带来显著价值。然而,当依赖编程抓取时,团队必须构建自适应系统,有效管理会话行为,并遵守平台规则和韩国数据法规。应对Naver动态架构通常涉及设置代理、解决CAPTCHA以及模拟真实用户交互——所有这些都可能复杂且耗时。
好消息是?维护不必成为负担。通过使用可靠的工具堆栈,包括浏览器自动化工具和API,您可以确保高效、合规且可扩展的Naver产品数据提取,而无需担心被封锁。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









