







一、从二维正态条件数学期望作为引入
例:若是服从
分布的二维随机变量,如果已知
,试求
。
解:根据二维随机变量分布的密度函数,可以得出
因此,条件数学期望为
此时如果把
画在平面直角坐标系中,它是一条直线。这条直线描述了依赖
的关系,常常称为回归直线。一般表示为
或者
二、构建一元回归模型
将在不确定性关系中作为影响因素的变量称为自变量或解释变量,用表示,受
取值影响的响应变量称为因变量,用
表示。假设
是可控制变量(可以是随机变量,也可以不是),即它的取值是可以事先取定的,
是可观测的随机变量,当
取定一个数值
时,就有一个随机变量
与之对应。令
从而其他随机因素引起的偏差是
这时与
的不确定性关系表示为
对于一元线性回归模型来说,回归函数是线性函数,且可控制变量只有一个,即有如下形式的回归函数:
称为对
的一元线性回归方程或一元线性回归直线。
即为一元线性回归模型。
三、一元线性回归模型求解方法
通常我们可以采用参数的最小二乘估计来确定和
。
设为取值的一组实验数据,假定满足如下一元线性回归模型:
在此基础上,确定回归系数和
的估计值
和
,并使残差
尽可能的小,其中
因此可总结为求解下面的优化问题:
具体的解法是通过正规方程组来求解:
解得
为了简记运算结果,规定如下符号的表示含义:
从而和
可简记为
这样的得到的和
称为
和
的最小二乘估计,记作LSE。
为关于
的经验回归函数,称一元线性回归方程,其图形称为回归直线,且是
的最小二乘估计量。给定
后,称
为回归值(也称拟合值、预测值)。
四、一元线性回归有关性质
性质一:残差和等于零,即。
性质二:在样本回归直线上。
性质三
五、讨论回归直线是否有意义
将残差分成两部分的差:
前者称为随机误差,是由随机因素引起的误差(当然是越小越好);后者称为回归误差,有点类似于系统误差。
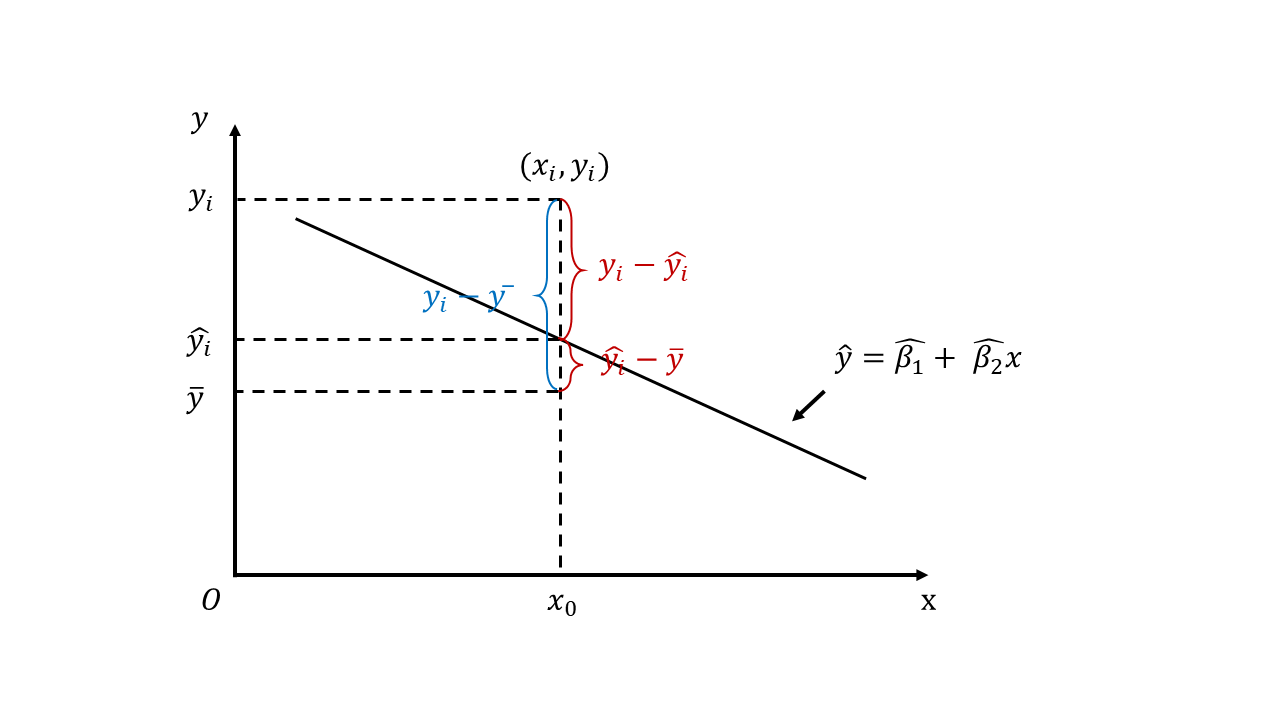
这三项竟然也满足平方和关系,证明的话就是展开后发现交叉项全部为0:
左端为总离差平方和,记为;
右端第一项为残差平方和,记为;
右端第二项为回归平方和,记为。
关于这三个平方和具有如下性质
(1),从而
是
的无偏估计。
(2)和
独立
(3)
(4)当时,有
直观上理解:只有当回归平方和比残差平方和
更大时,回归方程的预测才有更高的精度。为了定量地说明回归方程的精度,有以下对回归方程精度检验的方法。
六、一元线性回归方程系数的假设检验
1. F检验
,
原假设为真时,
当原假设不为真时,即
,
原假设为真时,选取如下统计量
在给定显著性水平的情况下,
拒绝域可以表示为
2. t检验
由于,
3. r检验
由于,从而
。这相当于回归平方和残差平方在总体中占的比重。我们耳熟能详的相关系数计算公式如下:
通过比较与1是否接近从而判断回归方程的精度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









