






隐私事件频发引发对本地AI的关注
近期人工智能应用的隐私安全问题频频曝出,引发了广大用户的担忧。5月20日,国家网信部门通报应用宝平台中35款App违法违规收集个人信息,其中就包括智谱清言、Kimi等热门AI应用。此外,美团旗下的 AI应用 “Wow” 以及字节跳动的 “猫箱” 也在被通报名单之列。这些应用被指存在超范围收集用户信息、收集与功能无关的个人信息等多种违规情形。在经历了一段时间的爆发式发展后,AI应用的隐私安全问题开始受到更多关注。相比传统应用,AI应用由于技术特性和数据需求不同,面临更严峻的数据安全挑战。这一系列事件无疑加剧了用户的“隐私焦虑”——很多人开始担心与AI对话时自己的敏感信息会否被后台记录、滥用。

在此背景下,一部分用户和开发者把目光投向了本地部署的大语言模型(LLM)工具。通过在本地运行AI模型,所有数据均留存在用户自己的设备上,不经过第三方服务器处理,从而从源头上降低了隐私泄露的风险。这种思路不仅回应了当下隐私安全的关切,同时也为AI应用的使用提供了一条新路径。下面我们将以近日发布的新功能为例,介绍本地LLM工具 Ollama 及其在 ServBay 开发环境中的一键部署方案,探讨本地部署在保护用户隐私方面的优势,并附上详细的教程供有兴趣的读者参考。
什么是 Ollama?本地部署LLM的新选择
要理解本地LLM的优势,首先需要了解Ollama 这一工具。简单来说,Ollama 是一个开源的本地大语言模型运行框架,它能够让用户在自己的电脑上下载、安装并运行各种主流的大模型。Ollama 支持的模型非常丰富,涵盖了国内外多种开源LLM,例如 DeepSeek-R1(深度求索模型)、LLaMA(Meta开源模型)、Qwen(通义千问,阿里巴巴模型)等。也就是说,不论是国外广受关注的 LLaMA 系列,还是国内新涌现的 DeepSeek、Qwen 等模型,用户都可以通过 Ollama 在本地运行它们。
然而,在没有图形化支持的情况下,传统方式使用 Ollama 对许多非专业用户而言存在一定技术门槛。过去要在本地部署这些大模型,往往需要通过命令行执行一系列复杂步骤,包括配置环境变量、安装依赖库、手动下载上百GB的模型文件等等。稍有不慎还可能遇到各种错误,令人生畏。正因如此,虽然本地LLM具备隐私保障的天然优势,但许多普通用户很难真正把它用起来。
值得庆幸的是,随着工具链的进步,本地部署LLM正在变得越来越简单。其中一个显著的变化就是 ServBay 对 Ollama 的深度集成。ServBay 是一款跨平台的本地开发环境工具(支持 macOS 系统),原本用于快速搭建本地的 Web 服务器、数据库等开发服务,如今在新版本中新增了一键部署 Ollama 的功能。这意味着,即使您没有深厚的系统和开发背景,也可以借助 ServBay 以可视化的方式在本地启动大语言模型。通过这样的集成,本地LLM工具的诸多优势将真正触手可及:
-
数据完全自主管控:本地部署最大的优势就是数据隐私和安全。所有对模型的请求、提示词以及模型生成的日志都留存在您自己的硬件中,杜绝任何第三方未授权访问的风险。不像在线服务那样需要把您的聊天内容上传到云端,本地LLM确保对话内容不出门,有效缓解了用户对隐私泄露的担忧。
-
低延迟与高性能:由于推理过程完全在本地进行,省去了网络往返云端的开销,本地LLM可以实现毫秒级的响应延迟。对于需要实时交互的应用(如本地聊天机器人、编程助手等)来说,响应迅速带来更流畅的使用体验。此外,一旦购置硬件,调用模型不再产生额外费用,避免了云服务高额的计费和不可预测的账单。
综上,在当前隐私事件频发的环境下,本地部署LLM工具提供了一种兼顾安全与效率的解决方案。下面我们将具体看看Servbay是如何将复杂的 Ollama 部署过程化繁为简,并总结其给用户带来的便利之处。
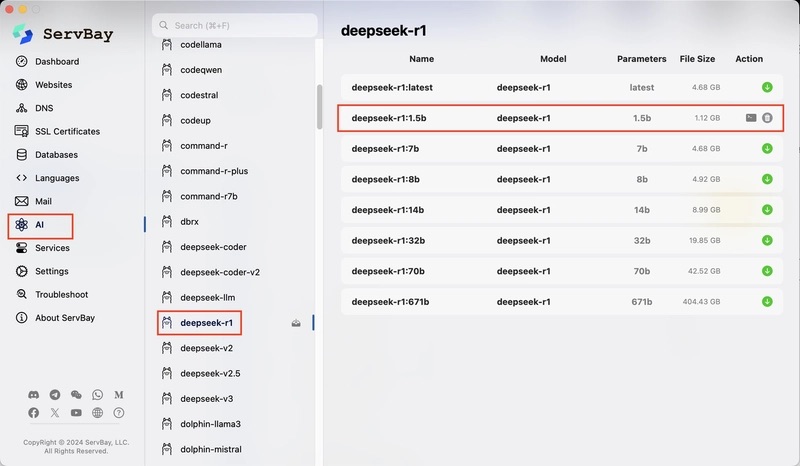
ServBay 集成 Ollama:一键部署带来的五大优势
ServBay 从 v1.12.0 版本开始引入了对 Ollama 的一键集成功能,将原本复杂的命令行部署流程转变为简单直观的GUI操作。借助 ServBay,用户只需点击几下鼠标,就能在本地安装并运行所需的大模型。下面,我们以要点形式盘点 ServBay + Ollama 带来的主要优势:
-
直观的可视化界面:再也无需对着黑乎乎的终端敲命令。ServBay 为 Ollama 提供了完善的图形化管理界面,用户可以在面板上方便地启动、停止或重启 Ollama 服务,查看运行状态和日志,并通过设置界面调整参数。所有操作都有清晰的按钮和开关,大大降低了使用门槛,让不擅长命令行的用户也能得心应手。
-
一键安装与同时运行多个模型:过去部署新模型往往意味着繁琐的配置和安装过程,而现在在 ServBay 中选择模型版本并点击安装即可自动完成一切。无论是只有十亿参数的轻量模型还是上百亿参数的大型模型,ServBay 都能自动处理依赖环境和资源分配,彻底告别手动出错的烦恼。更强大的是,ServBay 支持同时启动多个大模型实例(只要本地硬件资源充足)。您可以在不同任务间自由切换模型,而不必每次启停,极大提升了效率和灵活性。
-
-
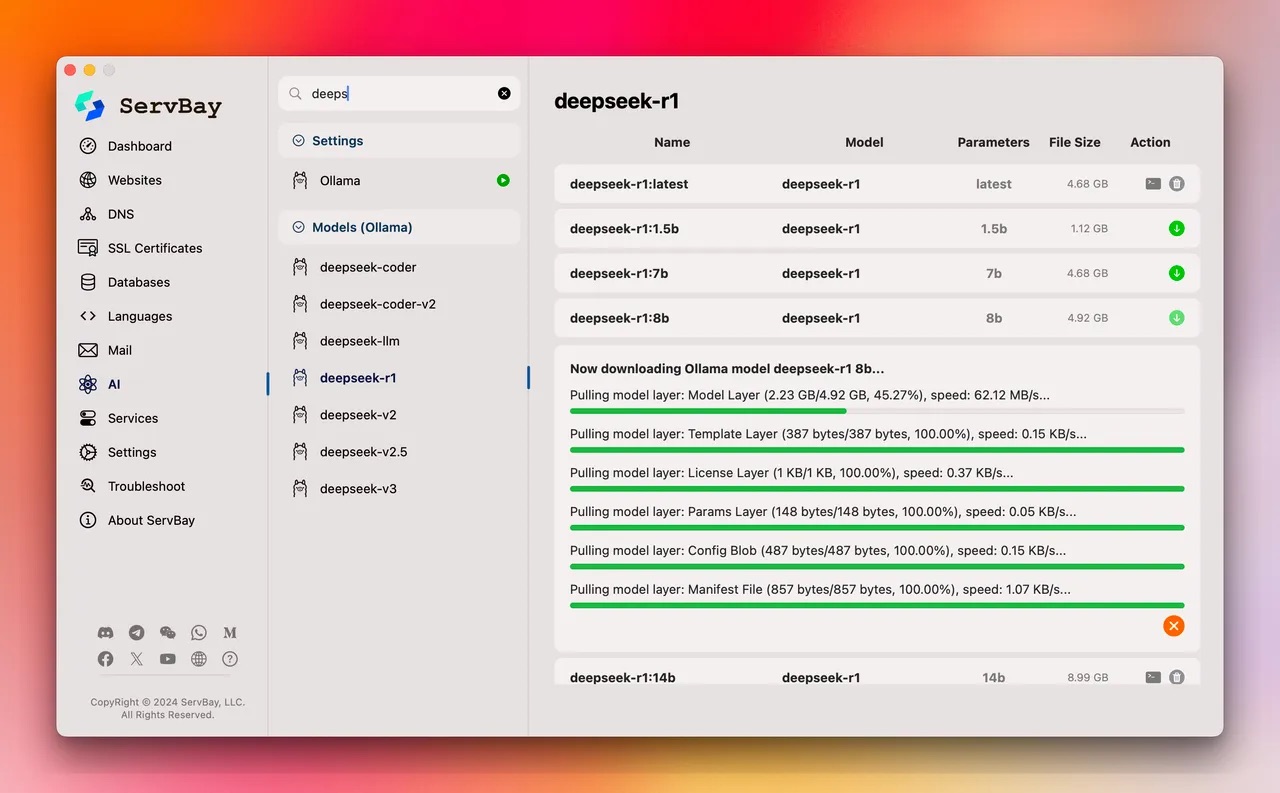
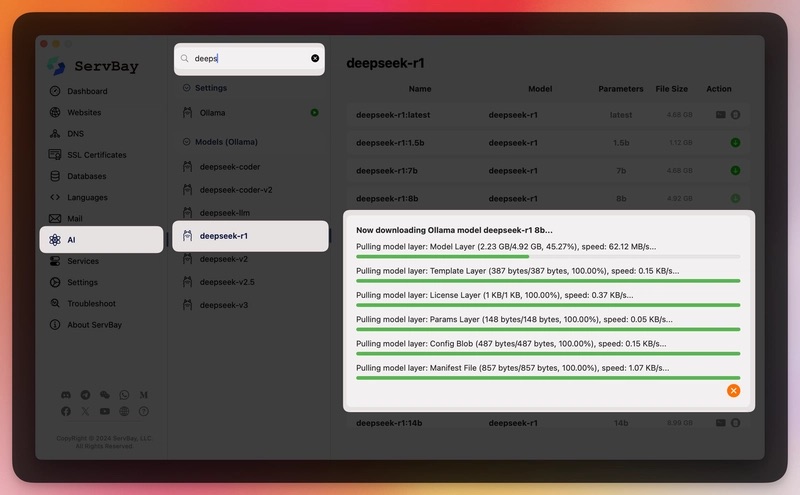
多线程高速下载模型:大型模型的文件往往体积惊人(几十GB乃至更大),下载缓慢曾是让人头疼的问题。ServBay 针对这一痛点提供了多线程并行下载支持,可以显著提升模型的下载速度。实测中,通过 ServBay 下载模型时速度甚至可超过 60MB/s,而对比之下 Ollama 默认方式下经常只有几十KB/s。用户还可以在设置中调整下载线程数,以充分利用带宽提升下载效率。高速下载意味着更短的等待时间,让您几分钟内就能获取并运行心仪的模型。
-
支持 macOS 本地开发测试:ServBay 的 Ollama 功能目前支持在 macOS 12 及以上版本的系统上运行。这对使用 Mac 开发的用户来说非常友好:可以充分利用 Apple 芯片在本地运行AI推理的性能优势,在笔记本上直接完成模型调试和应用原型开发。而且 ServBay 无需依赖 Docker 容器即可隔离管理服务,大幅降低了在 Mac 上配置AI环境的复杂度。
-
非技术用户也能轻松上手:过去只有熟悉命令行和脚本的开发者才能玩转本地模型,但现在借助 ServBay 的一键部署,即使是零开发经验的“小白”用户也可以快速上手本地LLM。ServBay 已经为用户处理好了一切底层配置,避免了繁琐的环境搭建和可能出现的错误。因此,从安装Ollama服务到加载模型,全流程都傻瓜式可视化,真正实现开箱即用。这种降低门槛的设计,让更多对AI有兴趣的普通用户也能加入本地部署的行列。
综上所述,ServBay 对 Ollama 的集成极大改善了本地部署LLM的体验。从界面友好度、安装便利性到运行效率,各方面都做了优化,让开发者和普通用户都能更专注于模型本身的调优和应用开发,而不是把精力耗费在环境配置上。
拥抱本地部署,守护数据隐私
当下,AI应用的隐私风险使越来越多的用户意识到数据自主可控的重要性。本地部署大语言模型以其“数据不出门”的天然优势,正成为缓解隐私焦虑的一剂良方。而像 ServBay 集成 Ollama 这样的工具,大幅降低了本地部署的技术门槛,让这一选择变得更加可行和易于实践。在不影响使用体验的前提下,用户可以既享受AI强大的功能,又对自己的数据拥有100%的掌控权。对于关注隐私安全的个人开发者和企业团队来说,本地LLM无疑是值得深入探索的方向。
总的来说,ServBay+ Ollama 为我们展示了本地部署AI的美好前景:即使不依赖云端,我们依然可以快速地搭建起强大的AI应用,并确保所有的交互数据都掌握在自己手中。希望通过本文的介绍和教程,能帮助大家更好地理解和体验本地LLM工具的魅力。如果您也对这种安全、高效的AI使用方式感兴趣,不妨下载最新版的 ServBay,亲自尝试一键部署 Ollama,打造属于自己的本地AI助手吧!下一篇文章将为大家带来操作步骤教程,想看的朋友们可以点个关注!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









