






人工智能(AI)正以前所未有的速度改变着我们的世界,而这其中最引人瞩目的力量之一,无疑是“大模型”(Large Language Models, LLMs)。它们凭借海量的数据和参数,展现出令人惊叹的理解、生成和推理能力,成为了各行各业探索创新的强大引擎。
面对市面上琳琅满目的大模型,我们该如何了解它们、选择适合自己的模型,甚至是尝试在本地运行呢?作为一名对AI充满好奇与探索欲的大四学生,我希望能和大家分享一些我的学习心得和实践经验。

主流AI大模型概览:各有千秋
当前,国内外涌现出众多优秀的大模型,它们由不同的机构开发,在能力、特性、应用场景等方面各有侧重。了解它们的优势与劣势,有助于我们更好地选择和使用。
以下是一些目前主流的大模型及其特点的简单对比:
| 模型名称 | 开发者 | 优势 | 劣势 | 典型应用场景 |
| GPT 系列 | OpenAI | 强大的通用能力,创意生成、对话、编程辅助等方面表现卓越。生态成熟。 | 闭源,API调用成本相对较高,数据隐私需考虑。 | 聊天机器人、内容创作、代码生成、智能客服等通用场景。 |
| Gemini 系列 | 原生支持多模态,能理解和处理文本、图片、音频、视频等多种信息。与Google生态结合紧密。 | 发布时间相对较晚,部分能力仍在快速迭代中。 | 多模态分析、信息检索、跨模态内容生成、编程等。 | |
| Claude 系列 | Anthropic | 拥有超长上下文窗口,处理长文本能力强。注重安全和伦理,不易产生有害内容。 | 在某些特定领域或中文能力上可能不如本土模型。 | 长文档处理、小说创作、安全合规的AI应用、总结归纳。 |
| Llama 系列 | Meta | 开源或社区驱动,版本多样,适合研究和定制开发。可在本地部署,灵活性高。 | 开箱即用性能可能不如头部闭源模型,需要一定技术能力进行部署和优化。 | 学术研究、定制化应用开发、本地部署、资源受限环境。 |
| 文心一言 | 百度 | 深耕中文领域,对中文语境理解和生成能力强。结合百度生态应用。 | 相对通用能力可能稍逊于国际顶级模型,海外用户使用有局限。 | 中文内容创作、国内市场应用、企业级智能解决方案。 |
| 通义千问 | 阿里云 | 背靠阿里云,技术积累深厚。在编程、数学等领域有不错表现。可集成至阿里云服务。 | 发展较快,但仍需不断完善和优化。 | 企业级应用、云服务集成、编程辅助、科研计算。 |
| 星火认知大模型 | 科大讯飞 | 在中文理解、语音交互、教育医疗等领域有特色优势。 | 主要面向特定行业应用,通用性上可能有所侧重。 | 智能语音、教育辅助、医疗诊断、行业解决方案。 |
| DeepSeek 系列 | DeepSeek AI | 在编程能力方面表现突出,代码生成、补全、解释等方面性能优异。有社区版可本地部署。 | 主要优势在编程领域,通用对话能力可能不是最强。 | 代码开发、技术文档生成、编程教育、开发者工具集成。 |
选择建议:
- 如果您需要最前沿、最强大的通用能力,并且不介意API费用和数据隐私,GPT或Gemini通常是不错的选择。
- 如果需要处理超长文本或对安全伦理有较高要求,Claude值得考虑。
- 如果希望进行定制开发、学术研究,或者需要在本地部署,Llama系列等开源模型提供了极高的灵活性。
- 如果主要面向中文用户和市场,并且需要结合特定生态,文心一言、通义千问、星火认知大模型等本土模型具有优势。
- 如果您的核心需求是编程,DeepSeek模型往往能提供更好的体验。
实际上,很多时候并没有绝对的“最好”,只有“最适合”特定场景和需求的模型。
大模型本地部署:让AI触手可及
尽管云端大模型提供了强大的能力,但本地部署也有其独特的吸引力:
- 数据隐私与安全: 敏感数据无需上传云端,更安全可控。
- 低延迟: 在本地运行,响应速度更快。
- 离线可用: 无需网络连接即可使用。
- 成本控制: 长期使用可能比API调用更经济(前提是有合适的硬件)。
- 定制化与实验: 更容易对模型进行微调或实验。
当然,本地部署的最大门槛是硬件要求,尤其是需要一块性能较好的GPU显卡。
常规的本地部署方法通常涉及:
- 选择合适的模型版本: 通常需要下载针对特定硬件优化过的模型文件(如 FP16, INT8 量化版本等)。
- 安装运行框架: 使用如 PyTorch, TensorFlow 等深度学习框架,或llama.cpp, vLLM 等专为LLM优化的推理框架。
- 配置环境: 安装依赖库、设置显卡驱动等。
这些步骤对于不熟悉深度学习环境配置的同学来说,可能有些复杂。幸运的是,现在出现了一些简化本地部署流程的工具。
我的本地部署小尝试:大四学姐的Ollama初体验
作为一名即将毕业、对AI充满好奇的大四学生,我一直在探索如何能更“亲手”地感受大模型的运作。最近,为了测试DeepSeek模型在编程任务上的表现,我尝试了一次本地部署。
我选择了DeepSeek-R1模型,原因之前也提到了,我对它在代码方面的能力很感兴趣。在工具的选择上,我使用了 Ollama。Ollama 是一个非常方便的工具,它简化了模型的下载、安装和运行过程,让本地部署大模型变得相对容易。通过简单的命令,我就可以拉取 DeepSeek 模型并在本地运行。
看了B站也是有些教程,因为之前用过Servbay这个工具,我直接就用它下载Ollama一键搞定了的,不清楚这个工具的可以回看我之前的帖子,专门介绍这个工具的。在 Ollama 的帮助下,我成功地在我的笔记本电脑上运行了 DeepSeek 模型(因为我只是测试用,我直接市选择了1.5B的乞丐版,如果你豪无人性,你可以选择满血的671B版),并进行了一些简单的编程辅助测试。
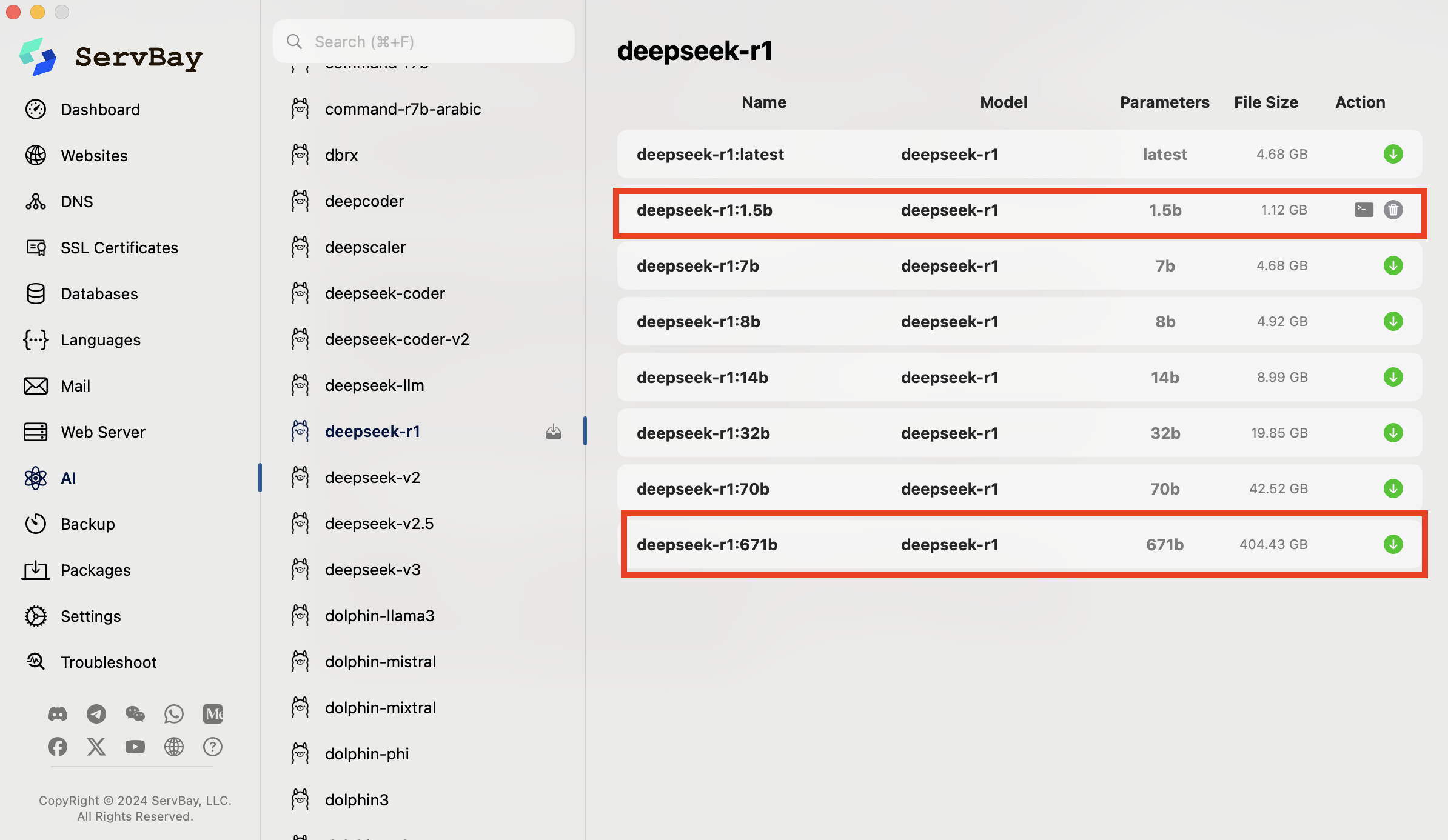
当然,丐版 DeepSeek 的能力不敢恭维,但也算是体验了本地部署大模型的过程。这让我对AI技术的落地应用有了更深的理解,也更加期待未来能将所学应用于实际。
结语
无论是云端强大的能力,还是本地部署的灵活性,大模型正以前所未有的方式赋能个人和企业。了解不同模型的特点,并根据自己的需求选择合适的部署方式,是我们玩转AI时代的必修课。
希望我的分享能帮助大家对主流大模型和本地部署有一个初步的认识。AI的世界正在加速发展,保持好奇心,动手实践,我们都能成为这场变革的参与者!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









