




一、系统程序文件列表
二、开题报告内容
Springboot古建筑保护管理系统设计与实现 开题报告
| 论文(设计)题目 | Springboot 古建筑保护管理系统设计与实现 | Springboot 古建筑保护管理系统设计与实现 | Springboot 古建筑保护管理系统设计与实现 |
|---|---|---|---|
| 学 院 | 计算机科学与技术学院 | 专业班级 | 软件工程 XXXX 班 |
| 学生姓名 | H 同学 | 学 号 | XXXXXXXX |
| 指导教师 | XXX | 职称或学位 | XXX(如:副教授 / 硕士) |
| 选题来源 | 1. 科研课题 □ 2. 企业与社会生产实践 □ 3. 自选课题 ■ | 选题类型 | A. 理论研究 □ B. 应用研究 □ C. 软件设计 ■ |
一、课题的目的及意义
(一)研究目的
当前古建筑保护管理存在信息碎片化(纸质档案易丢失、电子记录分散)、保护流程不规范(巡检记录不及时、维修进度难跟踪)、资源共享不足(文物部门、研究机构、公众间信息壁垒)等问题。本课题旨在基于 Spring Boot 框架,设计并实现一套集 “古建筑信息管理、保护巡检、维修跟踪、公众科普” 于一体的古建筑保护管理系统,实现古建筑保护管理的数字化、规范化与智能化,为文物保护部门提供高效的管理工具,同时为公众搭建了解古建筑的科普平台。
(二)研究意义
- 理论意义:本系统将软件工程(Spring Boot、前后端分离架构)与古建筑保护学交叉融合,丰富 “数字化文物保护” 领域的技术实践案例,为后续同类系统(如古遗址、近现代文物管理系统)的开发提供可借鉴的架构设计与功能模块参考。
- 实践意义:
- 对文物保护部门:通过系统整合古建筑基础信息(年代、结构、病害情况)、巡检数据、维修记录,实现 “一建筑一档案”,减少人工记录误差,提升保护管理效率;
- 对公众:系统开放古建筑基础科普信息(历史背景、文化价值、开放时间),增强公众对古建筑的认知与保护意识,助力文化传承;
- 对研究机构:为古建筑保护研究提供结构化的历史数据(如病害演变趋势、维修效果反馈),支撑学术研究的精准性。
- 社会意义:古建筑是文化遗产的重要载体,系统通过数字化手段延长古建筑 “信息生命周期”,减少因管理不当导致的保护延误,助力文化遗产的活态传承,符合 “文化自信” 与 “数字化中国” 的发展需求。
二、国内外发展现状
(一)国内发展现状
国内古建筑保护数字化起步于 21 世纪初,目前呈现 “政策推动、局部落地” 的特点:
- 政策层面:国家文物局印发《“十四五” 文物信息化发展规划》,明确提出 “推进文物保护管理数字化转型”,部分省市(如北京、山西)已试点古建筑电子档案系统;
- 技术应用:多数现有系统聚焦 “信息存储”(如故宫 “数字文物库”),但存在功能单一(仅展示文物图片与文字,缺乏保护流程管理)、交互性弱(公众仅能被动浏览,无法参与反馈)、跨部门协同不足(文物局与维修单位数据不互通)等问题;
- 学术研究:国内学者多关注 “古建筑三维建模”(如利用 BIM 技术还原建筑结构),但针对 “保护全流程管理系统” 的技术实现(如 Spring Boot 框架应用、数据安全设计)研究较少,系统实用性与落地性有待提升。
(二)国外发展现状
发达国家(如意大利、法国、日本)在古建筑数字化保护领域起步较早,技术应用更为成熟:
- 系统功能:意大利 “文化遗产信息系统(SIA)” 整合了古建筑的历史档案、保护修复记录、游客管理数据,支持多部门(文物局、修复机构、旅游部门)协同操作;日本 “古建筑保护管理平台” 引入物联网技术(如传感器监测建筑温湿度、结构变形),实现保护的 “预防性管理”;
- 技术特点:普遍采用 “云架构 + 移动端” 设计,支持工作人员现场通过手机端录入巡检数据,同时开放公众查询接口(如法国 “Monuments Historiques” 平台,公众可查询古建筑保护状态与开放信息);
- 不足:国外系统多基于本国文化遗产特点设计,对中国古建筑 “木构为主、病害类型复杂(如虫蛀、风化)” 的适配性不足,且部分系统收费较高、不开放源代码,难以直接借鉴。
(三)总结
国内外现有研究已意识到数字化对古建筑保护的重要性,但国内系统仍需突破 “功能单一、协同不足” 的瓶颈,国外系统需结合中国古建筑特点进行本土化适配。本系统将聚焦 “保护全流程管理” 与 “公众参与”,弥补现有系统的短板。
三、研究的主要内容
(一)系统技术架构设计
采用前后端分离架构,具体技术栈如下:
| 技术层级 | 技术选型 | 版本 / 工具 | 作用 |
|---|---|---|---|
| 后端 | Spring Boot | 2.7.x | 快速开发后端接口,处理业务逻辑(如巡检数据校验、维修进度更新) |
| 后端 | MyBatis-Plus | 3.5.x | 简化 MySQL 数据库操作,实现古建筑信息、用户数据的 CRUD |
| 数据库 | MySQL | 8.0.x | 存储古建筑基础信息、巡检记录、维修工单、用户信息等结构化数据 |
| 前端 | Vue.js | 3.x(搭配 Element Plus) | 构建用户友好的界面(如管理员后台、公众科普页面) |
| 移动端 | 响应式设计 | - | 支持文物管理员通过手机端录入巡检数据、上传现场照片 |
| 数据安全 | JWT | - | 实现用户身份认证(区分管理员、巡检员、普通用户) |
(二)核心功能模块设计
系统分为管理员端、文物管理员端、公众端三个角色,各角色功能模块如下:
1. 管理员端(核心管理角色)
- (1)用户管理:审核 “文物管理员” 账号申请(分配巡检权限,如指定负责的古建筑区域)、禁用违规公众账号、重置用户密码;
- (2)古建筑基础信息管理:录入 / 编辑古建筑信息(基础属性:名称、年代、结构类型、地址;文化属性:历史背景、保护级别;现状属性:病害类型、保护状态),支持上传图片、三维模型文件(如 OBJ 格式),实现 “一建筑一档案”;
- (3)系统配置:设置巡检周期(如重点古建筑每月 1 次、一般古建筑每季度 1 次)、维修工单流转规则(如巡检发现 “重大病害” 时自动触发紧急维修流程)、数据备份计划(每日自动备份数据库,防止信息丢失)。
2. 文物管理员端(一线保护角色)
- (1)巡检管理:接收系统分配的巡检任务(含指定古建筑、巡检项),现场通过手机端填写巡检记录(如 “屋顶瓦片是否松动”“木构件是否有虫蛀”),上传现场照片 / 视频,标记 “正常”“轻微病害”“重大病害” 状态;
- (2)维修跟踪:查看由 “重大病害” 生成的维修工单,更新维修进度(如 “待派单→维修中→验收完成”),上传维修前后对比照片、维修材料清单;
- (3)数据统计:查看个人负责区域的巡检完成率、维修工单闭环率,生成月度巡检报告(系统自动汇总数据,支持导出 Excel)。
3. 公众端(科普与反馈角色)
- (1)古建筑科普:浏览系统开放的古建筑基础信息(历史背景、文化价值、开放时间),查看无涉密的巡检照片(如外观修复后的状态),支持按 “地区”“年代” 筛选古建筑;
- (2)保护反馈:公众发现古建筑存在异常(如游客刻画、构件损坏)时,可通过系统提交 “反馈建议”(含文字描述、现场照片、位置信息),由文物管理员审核后跟进;
- (3)参观预约:针对开放参观的古建筑,公众可在线预约参观时段(系统联动古建筑管理处的预约限额,避免过度拥挤),接收预约成功短信提醒。
4. 系统通用功能
- (1)身份认证:管理员 / 文物管理员通过 “账号密码 + 验证码” 登录,公众支持 “手机号注册登录”,通过 JWT 令牌维持登录状态;
- (2)消息通知:系统自动向文物管理员推送 “待巡检任务”“维修工单更新” 提醒,向公众推送 “反馈建议审核结果”“参观预约确认” 短信;
- (3)数据安全:对古建筑涉密信息(如维修核心技术、精确坐标)进行权限控制(仅管理员可见),用户密码采用 BCrypt 加密存储,防止数据泄露。
(三)预期实现效果
- 功能层面:实现 “古建筑信息管理 - 巡检 - 维修 - 科普” 全流程闭环,文物管理员巡检记录提交时间从 “人工纸质记录后录入系统” 的 2 小时缩短至 “现场实时提交” 的 5 分钟;
- 数据层面:系统存储至少 100 个典型古建筑的结构化档案,支持按 “病害类型”“年代” 进行数据统计(如 “明清古建筑木构虫蛀病害占比 60%”);
- 用户体验层面:管理员后台响应时间≤2 秒,公众端页面适配手机、电脑等设备,科普信息加载速度≤3 秒。
四、研究方法(技术路线)
本课题采用 “需求导向 - 设计 - 开发 - 测试” 的软件工程方法,具体技术路线如下:
- 需求分析阶段(2025 年 X 月 - X 月):
- 通过文献调研(查阅《古建筑保护工程施工规范》《文物数字化管理标准》)明确系统功能边界;
- 走访当地文物保护部门(如 XX 市文物局),访谈文物管理员、巡检人员,梳理核心需求(如巡检项定义、维修流程节点),形成《需求规格说明书》;
- 系统设计阶段(2025 年 X 月 - X 月):
- 架构设计:确定前后端分离架构,划分后端服务层(Controller、Service、Dao)、前端视图层(管理员端、公众端页面);
- 数据库设计:设计 E-R 图,创建核心数据表(如
ancient_architecture(古建筑表)、inspection_record(巡检记录表)、maintenance_order(维修工单表)); - 接口设计:定义后端 API 接口(如
/api/architecture/getById(获取单古建筑信息)、/api/inspection/submit(提交巡检记录)),明确请求参数与返回格式;
- 系统开发阶段(2025 年 X 月 - X 月):
- 后端开发:基于 Spring Boot 实现接口逻辑,使用 MyBatis-Plus 操作数据库,集成 JWT 实现身份认证;
- 前端开发:用 Vue.js+Element Plus 构建页面,实现数据可视化(如巡检完成率折线图、古建筑分布地图);
- 功能集成:对接短信通知接口(如阿里云短信服务),实现预约提醒、反馈通知功能;
- 系统测试阶段(2025 年 X 月 - X 月):
- 功能测试:采用 “黑盒测试” 验证各模块功能(如巡检记录提交后是否自动生成维修工单);
- 性能测试:用 JMeter 模拟 100 用户同时访问,测试系统响应时间与并发能力;
- 兼容性测试:验证系统在 Chrome、Edge、Safari 浏览器及手机端的显示与操作正常性;
- 系统优化与验收阶段(2025 年 X 月 - X 月):
- 根据测试结果修复漏洞(如数据校验不严格、页面适配问题);
- 邀请文物管理员试用系统,收集改进建议,优化操作流程,最终形成可运行的系统原型。
五、进度安排
| 时间节点(2025 年) | 阶段任务 | 交付成果 |
|---|---|---|
| X 月 X 日 - X 月 X 日 | 需求分析与文献调研 | 《需求规格说明书》、文献综述 |
| X 月 X 日 - X 月 X 日 | 系统架构设计、数据库设计 | 架构设计文档、E-R 图、数据表结构 |
| X 月 X 日 - X 月 X 日 | 后端接口开发、前端页面开发 | 后端 API 接口文档、前端页面原型 |
| X 月 X 日 - X 月 X 日 | 系统功能集成、联调测试 | 可运行的系统初版、测试报告 |
| X 月 X 日 - X 月 X 日 | 系统优化、用户试用 | 系统终版、试用反馈报告 |
| X 月 X 日 - X 月 X 日 | 毕业论文撰写、修改 | 毕业论文初稿 |
| X 月 X 日 - X 月 X 日 | 论文定稿、答辩准备 | 毕业论文终稿、答辩 PPT |
六、已具备的基础条件
- 理论与技术基础:已掌握 Java 编程语言、Spring Boot 框架核心知识(如依赖注入、RESTful 接口开发),熟悉 Vue.js 前端开发与 MySQL 数据库操作,具备软件工程专业所需的系统设计与开发能力;
- 调研与资料基础:已收集《古建筑保护管理办法》《Spring Boot 实战》等政策文件与技术书籍,通过中国知网(CNKI)查阅 “数字化古建筑保护” 相关文献 20 余篇,对行业需求与技术路线有清晰认知;
- 开发环境基础:已搭建本地开发环境(JDK 1.8、IntelliJ IDEA、MySQL 8.0、Vue CLI),可满足系统开发与测试需求;同时联系当地文物保护部门,可获取部分公开的古建筑基础数据(如名称、年代)用于系统测试。
七、主要参考文献
[1] 国家文物局. “十四五” 文物信息化发展规划 [Z]. 2021.
[2] 王洁。基于 Spring Boot 的古建筑电子档案管理系统设计 [J]. 信息技术,2023, 47 (06): 123-127.
[3] 李娜,张磊。古建筑巡检管理系统的设计与实现 [J]. 计算机工程与应用,2022, 58 (11): 234-240.
[4] 张小明。数字化技术在古建筑保护中的应用研究 [J]. 古建园林技术,2021, (03): 89-92.
[5] 陈皓. Spring Boot 实战(第 2 版)[M]. 北京:人民邮电出版社,2020.
[6] 意大利文化遗产部. Sistema Informativo per i Beni Culturali (SIA) User Guide [R]. 2022.
[7] Kim J, Lee S. Digital Preservation System for Traditional Korean Architecture Using BIM and Cloud[J]. Journal of Cultural Heritage, 2023, 58: 103-112.
[8] 国家文物局。古建筑保护工程施工规范(GB 50761-2012)[S]. 北京:中国建筑工业出版社,2012.
重要说明:以上为项目开发前基于选题撰写的开题报告内容,后期因需求调整、技术优化等因素,系统程序可能存在较大改动。最终成品以本文档后续 “运行环境 + 技术栈 + 界面展示” 为准,开题报告内容可作为开发与论文撰写的参考依据。系统源码获取方式详见文末!
三、系统技术栈
(一)前端技术栈:Vue.js
Vue.js 是一套专注于构建用户界面的渐进式 JavaScript 框架,具备轻量、高效、易集成的特点,尤其适合与 Spring Boot 后端框架搭配实现前后端分离架构。其核心库仅聚焦视图层,不强制依赖其他工具或库,既便于新手快速上手,也能灵活整合第三方插件(如 Vue Router、Vuex)或融入现有项目;同时,Vue.js 的响应式数据绑定机制可实时同步视图与数据,显著提升前端开发效率与用户交互体验。
(二)后端技术栈
- 核心容器:基于 Spring Boot 构建,提供全面的对象管理与依赖注入能力,可自动维护应用程序中各类组件的生命周期,简化对象创建与调用流程,降低代码耦合度。
- Web 层:Spring Boot 内置 Tomcat、Jetty、Undertow 等主流 Web 容器,无需额外配置即可快速搭建 Web 应用,支持 HTTP 请求处理、接口开发、会话管理等核心功能,满足项目的 Web 服务需求。
- 数据访问层:支持多种数据库连接池(如 HikariCP、Druid)与 ORM(对象关系映射)框架(如 MyBatis、JPA),可简化数据库操作流程(如 SQL 编写、结果映射、事务管理),降低数据访问层的开发复杂度,提升数据交互效率与安全性。
(三)开发工具
- IntelliJ IDEA:一款功能强大的 Java 集成开发环境(IDE),对 Spring Boot 项目开发支持尤为友好。内置丰富的插件(如 Spring Assistant、Lombok),可实现代码自动补全、语法检查、调试跟踪、项目构建等功能,大幅提升后端开发效率与代码质量。
- Visual Studio Code(VS Code):轻量级跨平台 IDE,支持 Windows、macOS、Linux 多系统运行。通过安装 Java、Vue.js 相关插件(如 Java Extension Pack、Vetur),可实现前后端代码的编写、调试与运行,兼顾开发灵活性与轻量化需求。
四、开发流程
- 项目初始化:使用 Maven 构建工具创建 Spring Boot 项目,可通过 IntelliJ IDEA、Eclipse 等 IDE 的可视化界面选择 “Spring Initializr” 模板,快速生成项目基础结构(含目录层级、配置文件框架)。
- 依赖配置:在项目根目录的pom.xml文件中,添加 Spring Boot 相关依赖(如spring-boot-starter-web用于 Web 开发、spring-boot-starter-mybatis用于数据访问),Maven 会自动下载并管理依赖包及其版本,避免版本冲突问题。
- 启动类设置:在src/main/java目录下创建项目启动类(通常命名为XXXApplication.java,如SystemApplication.java),并在类上添加@SpringBootApplication注解 —— 该注解整合了@Configuration(配置类)、@EnableAutoConfiguration(自动配置)、@ComponentScan(组件扫描)三大功能,是 Spring Boot 应用启动的核心标识。
- 核心配置:创建 Spring Boot 配置文件(支持application.properties(Properties 格式)或application.yml(YAML 格式)),在文件中定义数据库连接信息(如 URL、用户名、密码)、服务器端口、缓存策略、日志级别等核心配置,确保应用程序按预期运行。
五、使用者指南
(一)项目搭建步骤
- 工程创建与依赖引入:使用 Maven 或 Gradle 构建工具创建新工程,在构建配置文件(Maven 为pom.xml,Gradle 为build.gradle)中引入 Spring Boot 相关依赖(参考本文档 “开发流程 - 依赖配置” 部分),确保核心功能模块(Web、数据访问等)的依赖完整。
- 主类创建与配置:在src/main/java目录下创建项目主类,在类上添加@SpringBootApplication注解 —— 该注解会触发 Spring Boot 的自动配置机制,根据项目依赖与配置文件自动初始化应用环境(如加载 Web 容器、配置数据库连接)。
- 主方法编写:在主类中定义main方法,通过SpringApplication.run(主类.class, args)语句启动 Spring Boot 应用,示例代码如下:
java
运行
@SpringBootApplicationpublic class SystemApplication {
public static void main(String[] args) {
SpringApplication.run(SystemApplication.class, args);
}}
(二)核心机制说明:自动配置
Spring Boot 的自动配置机制是其核心特性之一,可根据项目中的依赖包、配置文件及外部属性,自动完成应用程序的配置(无需手动编写大量 XML 配置)。其实现原理为:Spring Boot 启动时,会扫描类路径下的META-INF/spring.factories文件,加载其中定义的自动配置类;随后根据项目依赖(如引入spring-boot-starter-web则自动配置 Web 容器)与配置文件参数,判断是否需要实例化相关组件(如 Tomcat 容器、DataSource 数据源),最终完成应用环境的初始化。
(三)应用运行步骤
- 运行方式:
- 方式 1(IDE 运行):在 IntelliJ IDEA 或 VS Code 中,找到主类文件,右键点击 “Run 主类名”(如 “Run SystemApplication”),即可启动应用。
- 方式 2(命令行运行):通过终端进入项目根目录,执行mvn spring-boot:run(Maven 项目)或gradle bootRun(Gradle 项目)命令,启动应用程序。
- 默认运行环境:Spring Boot 应用默认使用嵌入式容器(Tomcat 为默认容器,可通过修改依赖切换为 Jetty 或 Undertow)运行,无需额外安装或配置独立容器,启动后即可通过浏览器或接口测试工具(如 Postman)访问应用接口(默认端口为 8080,可在配置文件中修改)。
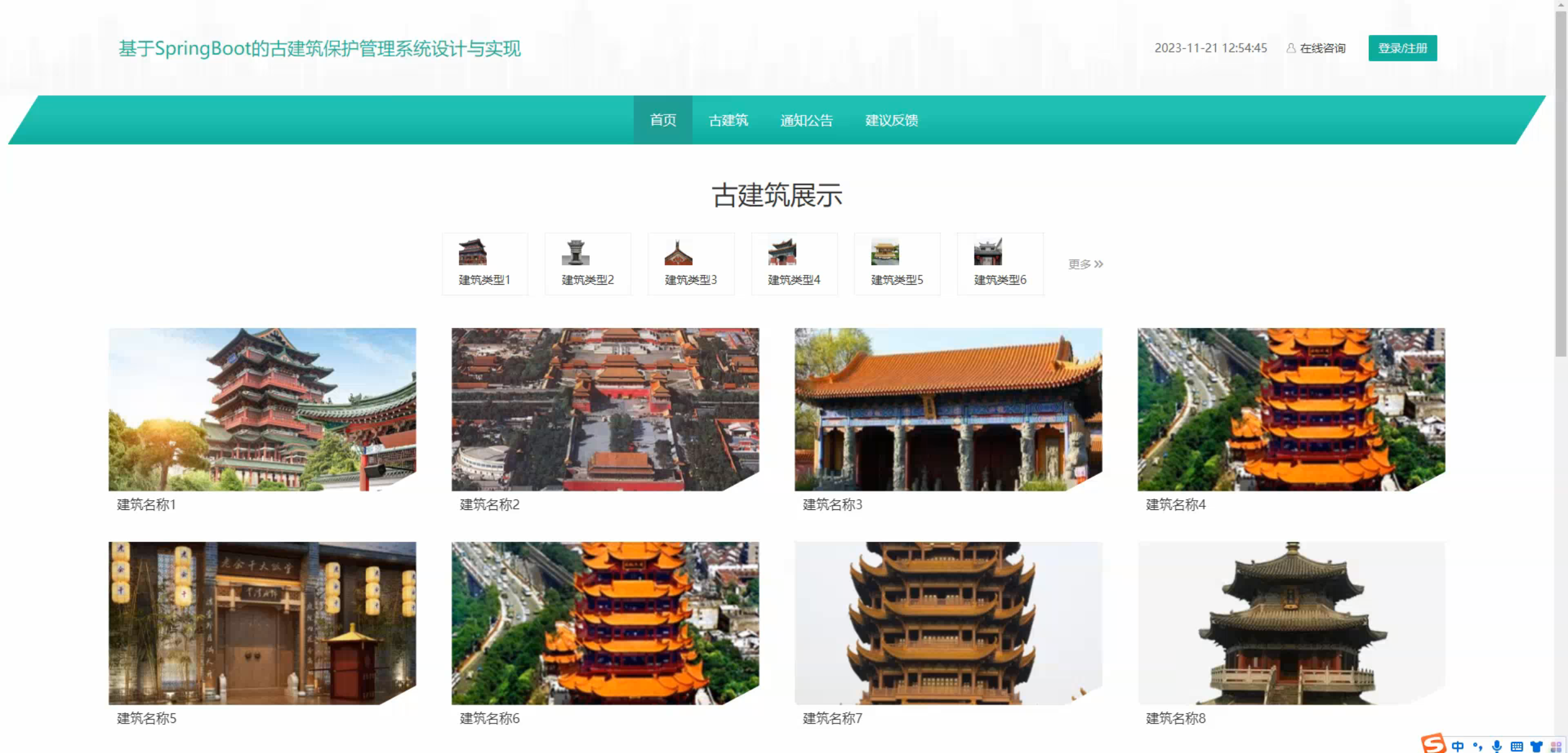
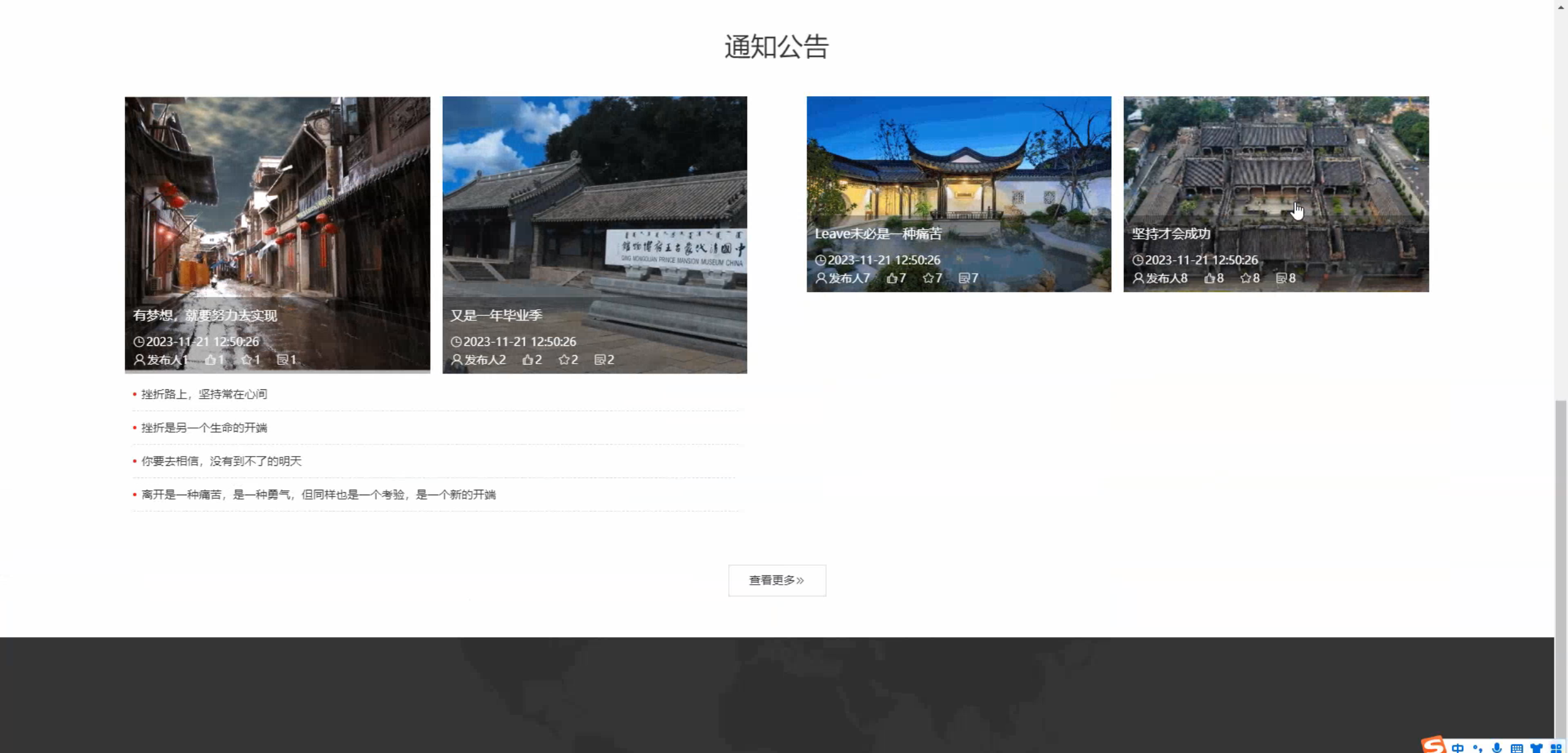
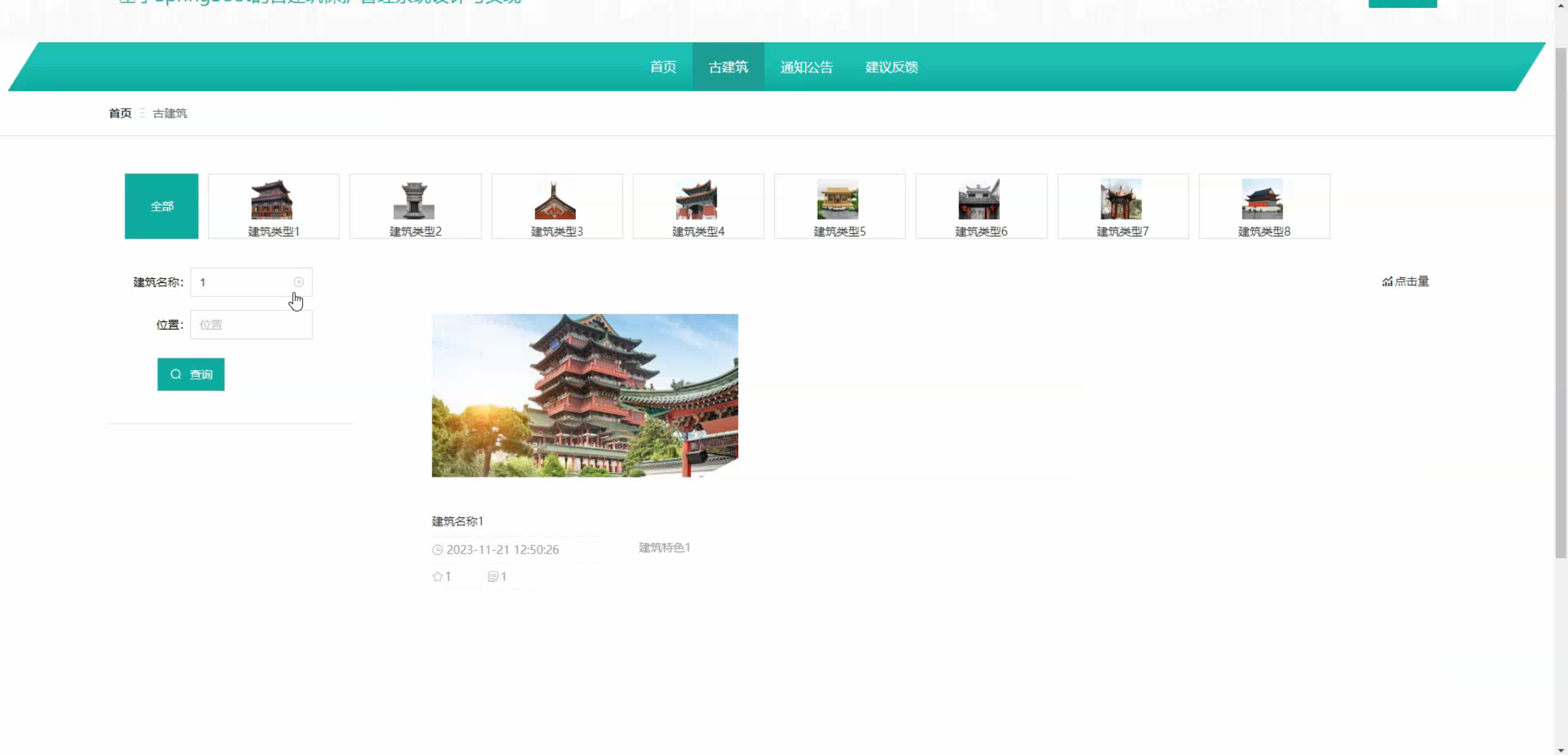
六、程序界面展示
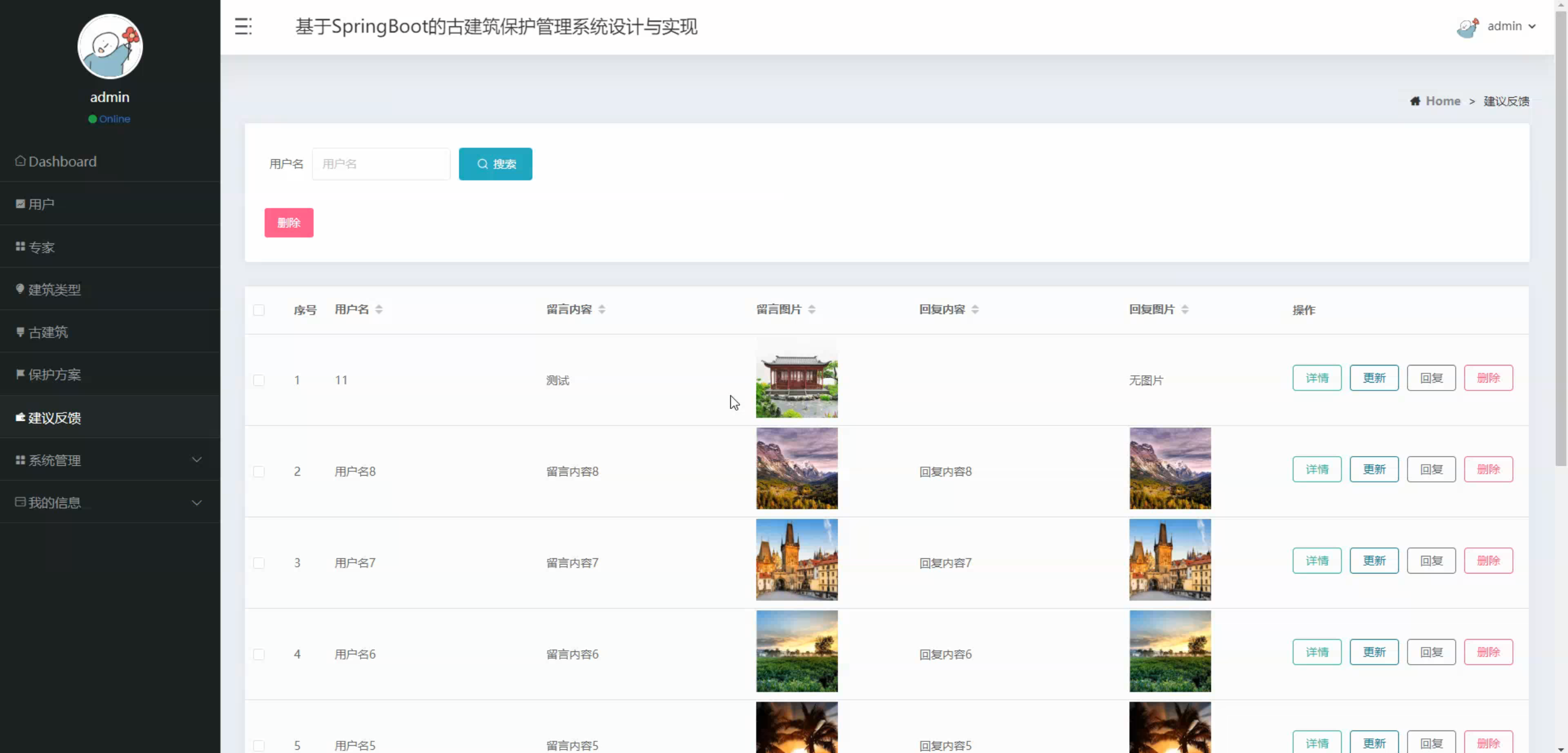
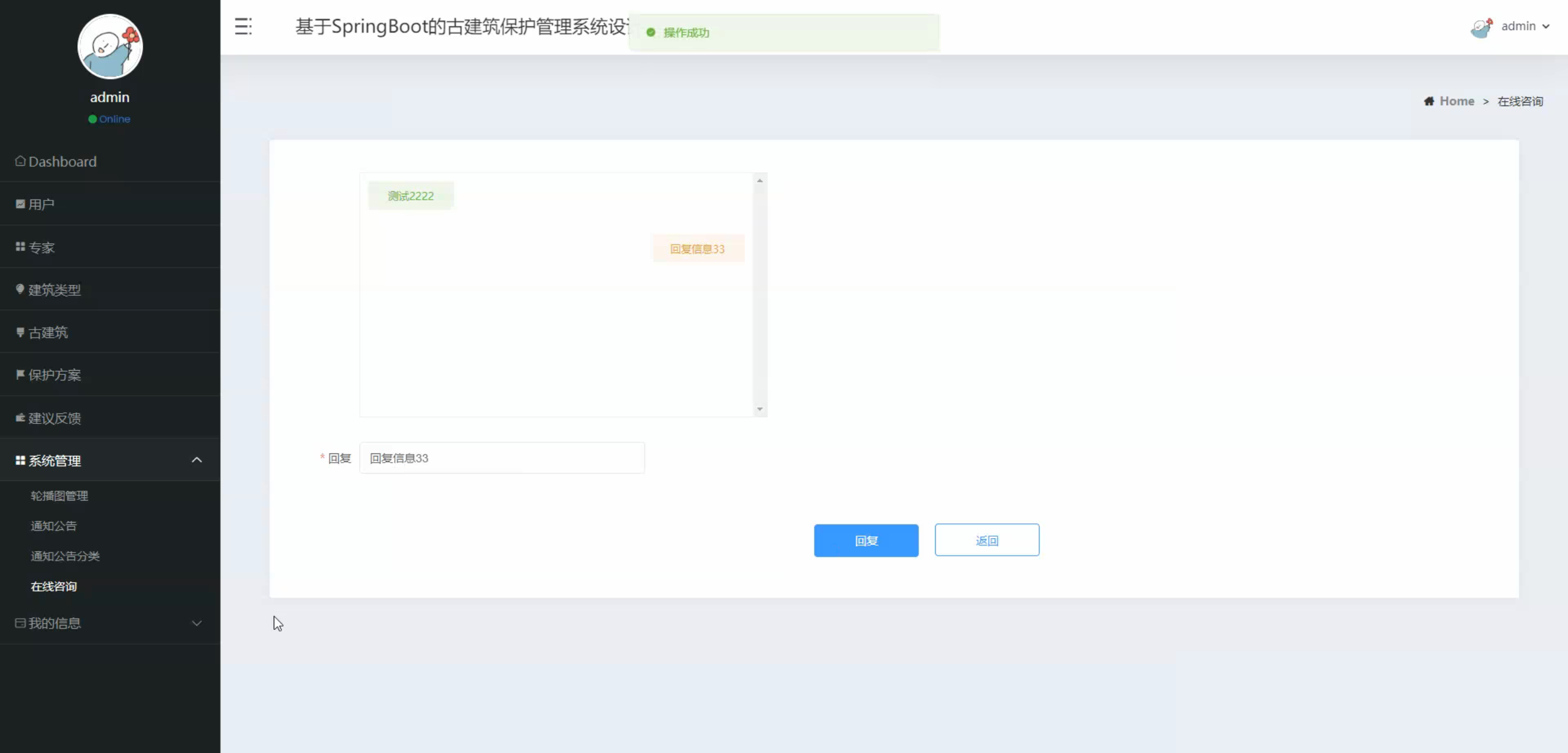

















 2765
2765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









