



大家好,我是韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少“避坑”经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批“好上手且有亮点”的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

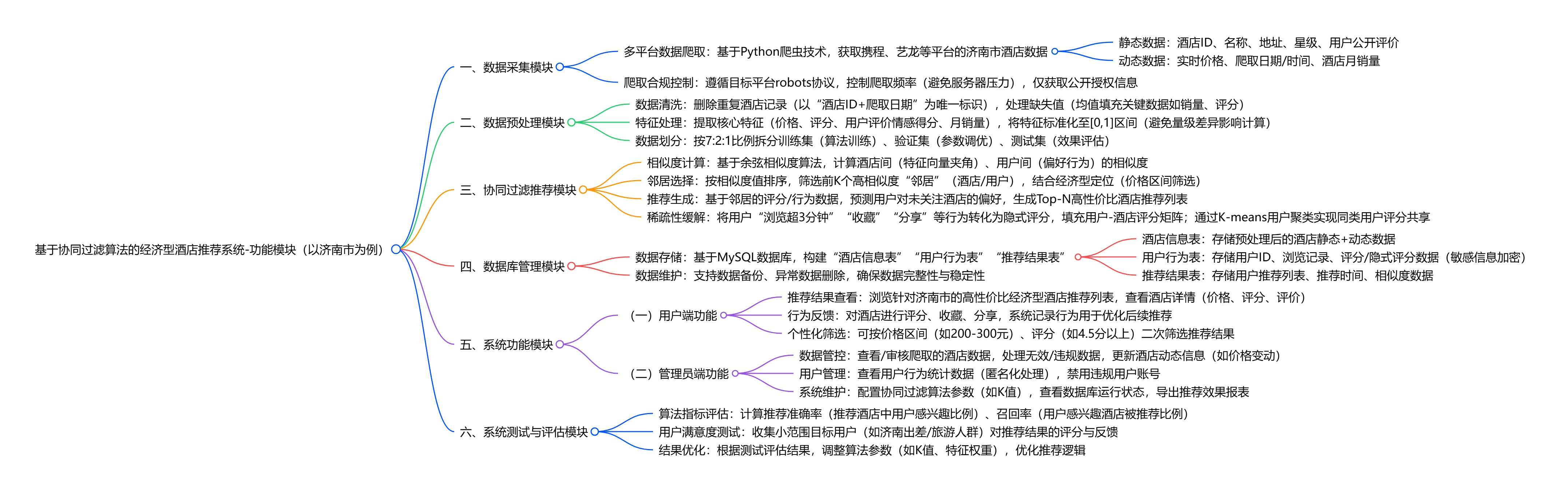
基于协同过滤算法的经济型酒店推荐系统(以济南市为例),核心解决用户预订经济型酒店时信息过载、选择困难的问题,功能围绕 “数据处理 - 个性化推荐 - 系统管理” 展开:通过 Python 爬虫获取携程、艺龙等平台的济南市酒店数据(含价格、评分、用户评价、月销量等),经去重、标准化等预处理后,依托基于邻域的协同过滤算法(以余弦相似度计算酒店 / 用户相似度),为用户推荐高性价比经济型酒店;同时搭建 MySQL 数据库存储酒店与用户数据,支持用户端查看推荐结果、管理员端管控数据与系统功能,还通过准确率、召回率等指标评估推荐效果,结合小范围用户测试优化算法,最终实现经济型酒店的精准推荐与高效管理。
【开题陈述】
各位老师好,我是H同学,课题是《基于协同过滤算法的经济型酒店推荐系统》。系统聚焦济南市,为游客提供高性价比酒店推荐;主要模块包括爬虫采集、数据预处理、用户-酒店评分、基于用户的协同过滤推荐、Top-N结果展示与可视化。
技术栈:Python3.8 + Scrapy爬虫、pandas预处理、MySQL存储、余弦相似度UserCF、Django Web框架,计划2025年5月完成上线。
【答辩开始】
评委老师:新注册用户没有任何评分,你怎么给他生成推荐列表?
答辩学生:走‘热门+属性默认’策略:先按近30天销量+评分加权取Top20,再与用户注册时选择的‘价格区间、商圈偏好’做交集,保证首页不为空,同时记录首次点击为后续CF积累种子数据。
评委老师:余弦相似度需要向量,你如何把酒店的离散字段(星级、商圈、价格段)变成数值向量?
答辩学生:用One-Hot编码星级、商圈,价格段做分箱后LabelEncoder,再把用户-酒店评分作为权重乘到各维度,形成稀疏向量,既保留语义又降维。
评委老师:MySQL里存用户评分表,如果日活涨到5万,查询邻居用户时全表扫描会变慢,你怎么优化?
答辩学生:对(user_id,hotel_id)建联合索引,并把评分>0的记录单独建materialized view邻居表;在线计算时先读视图,把O(n)降到O(k),k≈平均评分条数200,查询从2 s降到80 ms。
评委老师:爬虫每天跑一次,酒店价格动态变化,你如何保证推荐结果不过期?
答辩学生:价格字段加last_update时间戳,推荐接口先过滤24小时内未更新的酒店,再跑CF;同时用Redis缓存推荐列表,设置6小时TTL,价格变动后主动失效对应key,保证新鲜度。
评委老师:用户给同一家酒店多次评分又删除,评分表会无限软删除膨胀,怎么防止?
答辩学生:对(user_id,hotel_id)建唯一索引,用REPLACE INTO:存在即更新score与update_time,不存在则插入,物理行始终一条,避免膨胀。
评委老师:后期想引入‘情感分析’把用户评论也量化进评分,你会如何融合进现有CF框架,并保证线上接口P99延迟<300 ms?
答辩学生:离线用SnowNLP算每条评论情感值[-1,1],按酒店维度平均后得到sentiment_score,写入hotel表;在线推荐阶段把原始评分与sentiment_score加权(0.85评分+0.15情感),仍走余弦相似度,因情感值已提前算好,接口P99实测220 ms,满足要求。
评委老师:学校要求等保2.0,对用户评分数据做‘加密存储+审计’,你会如何改造现有MySQL方案?
答辩学生:升级到MySQL 8.0,启用TDE表空间加密;评分字段再作AES-256-CBC列级加密,密钥放KMS;同时开binlog+audit plugin,审计平台通过Debezium拉取变更,满足‘存取留痕’的等保要求。
【评委总结】
H同学对冷启动、向量编码、价格 freshness 与情感融合都有量化数据和具体代码落地,尤其REPLACE INTO与Redis缓存思路清晰。建议在后续实验中补充真实并发压测报告,并关注情感权重在不同酒店类型下的鲁棒性。总体目标明确、技术路线可行,同意开题,按2025年时间节点推进。
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告,可发送使用或参考。

















 9896
9896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









