






弱监督目标检测论文相关
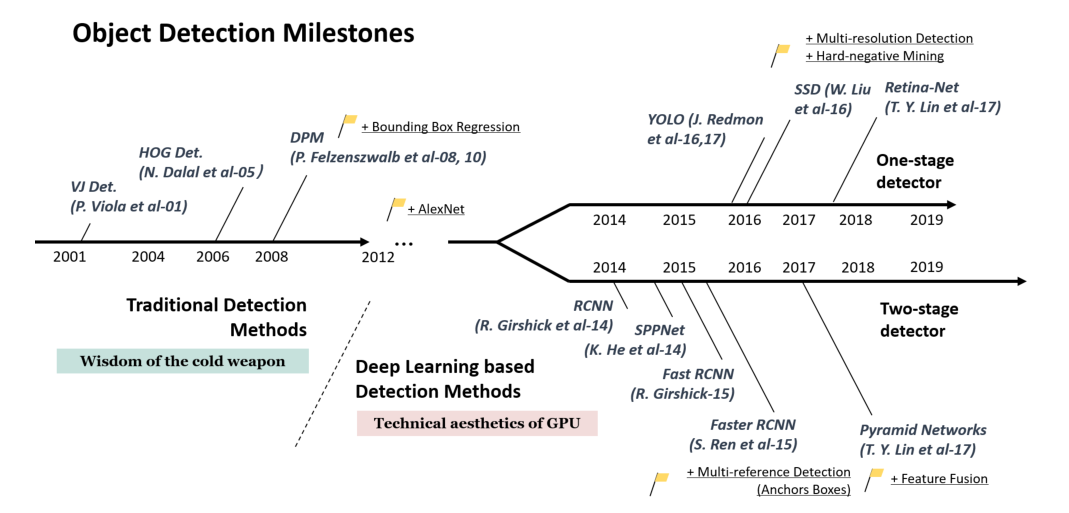
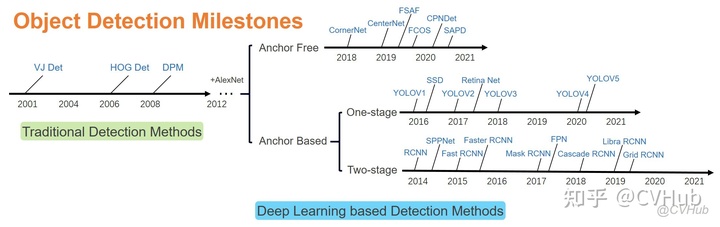
1.传统目标检测
2014年之前->传统的目标检测器:VJ检测器->HOG检测器->DPM
2014年之后->基于深度学习的目标检测器:
双阶段:RCNN->SPPNet->Fast RCNN->Faster RCNN->Feature Pyramid Networks
单阶段:YOLO->SSD->RetinaNet


现有的图像目标检测其通常可以被分为两类:一类是two-stage检测器,最具代表性的是Faster R-CNN[8]。另一种是one-stage检测器,如YOLO[9]、SSD[10]。two-stage检测器具有较高的定位和目标识别精度,而one-stage检测器具有较高的推理速度。two-stage检测器可以按照ROI池化层来划分为two-stage。例如,在Faster RCNN中,第1阶段叫做RPN,一种区域建议网络,提出候选目标边界框。第2阶段,通过ROI操作从每个候选框中提取特征,用于接下来的分类和边界框回归任务。图1 (a)为two-stage探测器的基本结构。此外,one-stage检测器直接从输入图像中提出预测框,不需要区域建议步长,因此具有时间效率,可用于实时设备。图1 (b)为one-stage探测器的基本结构
双阶段
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iJxMY5KG-1682324796818)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220710140738564.png)]
1.0 RCNN


思路:
- 给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
- 对于每个区域利用 CNN 抽取一个固定长度的特征向量。
- 再对每个区域利用 SVM 进行目标分类。
提取框,对每个框提取特征、图像分类、 非极大值抑制四个步骤进行目标检测。
边界框回归详解:
这个回归模型主要是用来修正由第二步Region proposals得到的图像区域。同第四步的分类一样,每个类别对应一个Regression模型。这个Bounding Box Regression主要是为了精准定位。它所做的就是把旧的区域(SS算法生成的区域) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9xsKkVNp-1682324798163)(null)] 重新映射到新的区域 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rDfAXCqa-1682324797476)(null)] ,其中 - 中心位置 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-024Ph99G-1682324797603)(null)] -宽高尺寸 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SPMgkolT-1682324797573)(null)]
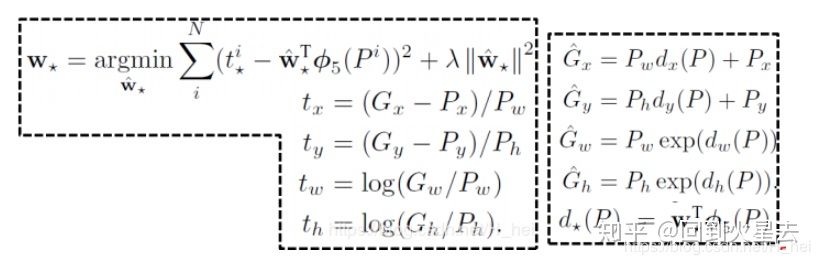
不足:
1.由于上一步Region proposals所提取出来的图像的尺寸大小是不一样的,我们需要卷积后输出的特征尺度是一样的,所以要将Region proposals选取的区域进行一定的缩放处理(warped region)成统一的227x227的大小,再送到CNN中特征提取。
1.2 SPP-net

R-CNN虽然不再像传统方法那样穷举,但R-CNN流程的第一步中对原始图片通过Selective Search提取的候选框region proposal多达2000个左右,而这2000个候选框每个框都需要进行CNN提特征+SVM分类,计算量很大,导致R-CNN检测速度很慢,一张图都需要47s。
那么有没有方法提速呢?答案是有的,这2000个region proposal不都是图像的一部分吗,那么我们完全可以对图像提一次卷积层特征,然后只需要将region proposal在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个region proposal的卷积层特征输入到全连接层做后续操作。
但现在的问题是每个region proposal的尺度不一样,而全连接层输入必须是固定的长度,所以直接这样输入全连接层肯定是不行的。SPP Net恰好可以解决这个问题。

贡献:
- 直接输入整图,所有区域共享卷积计算(一遍),在CNN输出上提取所有区域的特征
- 引入空间金字塔池化(Spatial Pyramid Pooling),为不同的尺寸区域在CNN输出上提取特征,映射到固定尺寸的全连接层上
存在的问题:
- ① 需要存储大量特征
- ② 复杂的多阶段训练
- ③ 训练时间长
1.3 Fast RCNN

实现步骤:
- 在图像中确定约1000-2000个候选框 (使用选择性搜索Selective Search)
- 对整张图片输进CNN,得到feature map
- 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
- 对于属于某一类别的候选框,用回归器进一步调整其位置
贡献:
1.损失函数,使得分类和回归同时进行

一个是分类的负对数损失 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cRBK1RKf-1682324797508)(null)] ,顺带一说,负对数损失就是softmax分类器的标配,具体原因详见softmax的知识点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uJtiNqOZ-1682324797914)(null)] 就是定位损失啦,它的损失函数采用的是smooth L1损失,具体地说,对四个坐标分别进行smooth L1,然后加起来,就像下面这样:
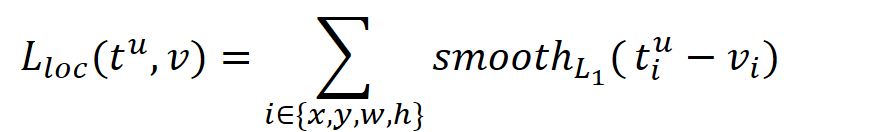
2.ROI pooling,使得不同尺寸的ROI都可以得到固定尺寸的特征图。
缺点:
1.4 Faster RCNN
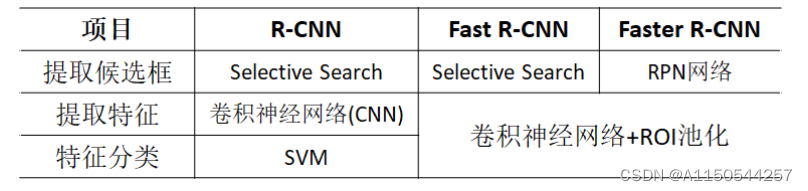
实现步骤:
-
对整张图片输进CNN,得到feature map
-
卷积特征输入到RPN,得到候选框的特征信息
-
对候选框中提取出的特征,使用分类器判别是否属于一个特定类
-
对于属于某一类别的候选框,用回归器进一步调整其位置
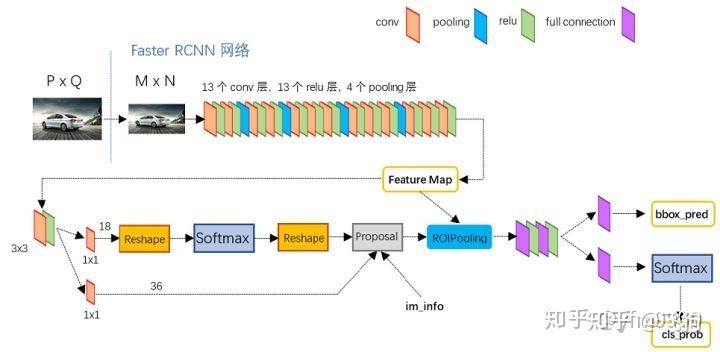
1.RPN网络:
可以清晰的看到该网络对于一副任意大小PxQ的图像:
- 首先缩放至固定大小MxN,然后将MxN图像送入网络;
- 而Conv layers中包含了13个conv层+13个relu层+4个pooling层;
- RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;
- 而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
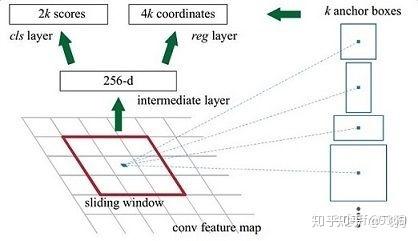
- 在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
- 在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息(猜测这样做也许更鲁棒?反正我没测试),同时256-d不变(如图中的红框)
- 假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4k coordinates
- 补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练(什么是合适的anchors下文5.1有解释)
注意,在本文讲解中使用的VGG conv5 num_output=512,所以是512d,其他类似。
卷积特征图每个像素点都配备这k种anchors作为初始的检测框,进而去判断anchor到底是物体还是背景(就是判断这个anchor到底有没有覆盖目标),以及为属于物体的anchor进行第一次坐标修正。
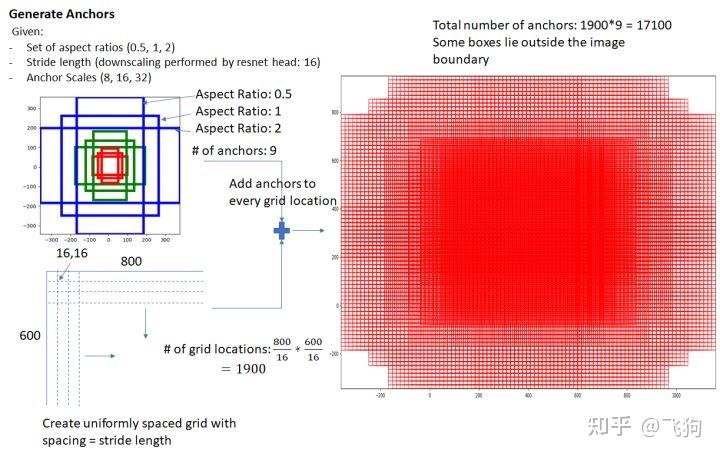
物体背景是二分类,所以cls layer得到2k 个scores;坐标修正是四个值(x,y,w,h),所以reg layer得到4k 个coordinates。RPN依靠在共享特征图上一个滑动的窗口,为每个位置生成9种目标框(anchor)。这9种anchor面积是128×128、256×256、512×512,长宽比是1:1、1:2、2:1,面积和长宽比两两组合形成9种anchor。
那么Anchor一共有多少个?原图800x600,VGG下采样16倍,feature map每个点设置9个Anchor,所以:
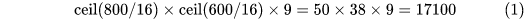
其中ceil()表示向上取整,是因为VGG输出的feature map size= 50*38。
对于训练bouding box regression网络回归分支,输入是cnn feature Φ,监督信号是Anchor与GT的差距[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Y6C5S06-1682324797714)(null)],即训练目标是:输入 Φ的情况下使网络输出与监督信号尽可能接近。那么当bouding box regression工作时,再输入Φ时,回归网络分支的输出就是每个Anchor的平移量和变换尺度[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S7FvOKaM-1682324797663)(null)],显然即可用来修正Anchor位置了。
在得到每一个候选区域anchor的修正参数之后,我们就可以计算出精确的anchor,然后按照物体的区域得分从大到小对得到的anchor排序,然后提出一些宽或者高很小的anchor(获取其它过滤条件),再经过非极大值抑制抑制,取前Top-N的anchors,然后作为proposals(候选框)输出,送入到RoI Pooling层。
VGG输出 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T6VbsLjN-1682324798192)(null)] 的特征,对应设置 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ASONjpoM-1682324797972)(null)] 个anchors,而RPN输出:
- 大小为[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7PC20nug-1682324797632)(null)] 的positive/negative softmax分类特征矩阵
- 大小为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0OUB1m2R-1682324798298)(null)] 的regression坐标回归特征矩阵
恰好满足RPN完成positive/negative分类+bounding box regression坐标回归.
2.proposal layer
Proposal Layer负责综合所有 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r6wuanCN-1682324797749)(null)] 变换量和positive anchors,计算出精准的proposal,送入后续RoI Pooling Layer。还是先来看看Proposal Layer的caffe prototxt定义:
layer {
name: 'proposal'
type: 'Python'
bottom: 'rpn_cls_prob_reshape'
bottom: 'rpn_bbox_pred'
bottom: 'im_info'
top: 'rois'
python_param {
module: 'rpn.proposal_layer'
layer: 'ProposalLayer'
param_str: "'feat_stride': 16"
}
}
Proposal Layer有3个输入:positive vs negative anchors分类器结果rpn_cls_prob_reshape,
对应的bbox reg的[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oN71kO6y-1682324798000)(null)]变换量rpn_bbox_pred,
以及im_info;另外还有参数feat_stride=16。
首先解释im_info。
对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息。
然后经过Conv Layers,经过4次pooling变为WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
- **生成anchors,**利用[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4eHdOXTQ-1682324797429)(null)]对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- 按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors
- **限定超出图像边界的positive anchors为图像边界,**防止后续roi pooling时proposal超出图像边界(见文章底部QA部分图21)
- 剔除尺寸非常小的positive anchors
- 对剩余的positive anchors进行NMS(nonmaximum suppression)
- Proposal Layer有3个输入:positive和negative anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的(e.g. 300)结果作为proposal输出
之后输出proposal=[x1, y1, x2, y2],注意,由于在第三步中将anchors映射回原图判断是否超出边界,所以这里输出的proposal是对应MxN输入图像尺度的,这点在后续网络中有用。另外我认为,严格意义上的检测应该到此就结束了,后续部分应该属于识别了。
RPN网络结构就介绍到这里,总结起来就是:
生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals
3.ROI pooling
RoI Pooling层则负责收集proposal,并计算出proposal feature maps,送入后续网络。Rol pooling层有2个输入:
- 原始的feature maps
- RPN输出的proposal boxes(大小各不相同)
步骤
- 由于proposal是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature map尺度;
- 再将每个proposal对应的feature map区域水平分为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fmu5AC11-1682324798055)(null)] 的网格;
- 对网格的每一份都进行max pooling处理。
这样处理后,即使大小不同的proposal输出结果都是 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dUXn1XNx-1682324798135)(null)] 固定大小,实现了固定长度输出。
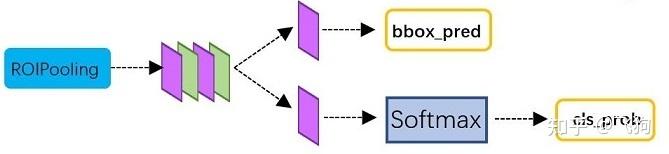
4.分类回归层
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;
同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。
5.训练步骤
Faster R-CNN的训练,是在已经训练好的model(如VGG_CNN_M_1024,VGG,ZF)的基础上继续进行训练。
实际中训练过程分为6个步骤:
- 在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
- 利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
- 第二训练RPN网络,对应stage2_rpn_train.pt
- 再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
1.5 Mask RCNN
1.6 FPN网络
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OisNpAWk-1682324796826)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220713165043029.png)]
单阶段
1.1 SSD
原理:
在不同的特征层上设置默认框,检测不同尺度的目标。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lP8QFKqu-1682324796826)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220713235938768.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-enqiHeAR-1682324796827)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220714000235230.png)]
1.2 RetinaNet
1.原理和贡献:
提出了一个focal loss函数,使网络更容易学习到难分样本,难分样本loss变大,易分样本概率变小。
one-stage精度首次超越two-stage
正负样本分配、损失函数设计。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s3kcj9E9-1682324796827)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220715223516820.png)]
网络结构:
这里回归参数是4A而不是4KA,类别未知,只预测与它最近的那个box,Faster Rcnn是4KA个参数。减少了运算量,重点!!!!!
1.3 YOLO V1
总结:
把目标检测视为一个回归问题,只用一个卷积神经网络实现分类和定位,不需要进行候选区域选择,而是把图像分成了7 × 7 的网格,每个网格负责预测两个 bbox,一个对象概率。每个bbox包含5个参数,(x,y,w,h,置信度概率),也就是一个网格对应一个30维的向量,最后输出向量是 7 * 7* 30。
背景:
YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。
对于YOLO v1而言,它在PascalVOC 2007测试数据集上达到的mAP是63.4%,在输入图像大小为448×448像素的图像上处理速度能够达到每秒45帧,该网络的一个小版本FastYOLO每秒处理速度也达到了惊人的155帧。
贡献和方法:
整体流程:
YOLO将目标检测问题作为回归问题。会将输入图像分成S × S 的网格(cell),如果一个物体的中心点落入到一个cell中,那么该cell就要负责预测该物体,一个格子只能预测一个物体,会生成两个预测框。
1.缩放图像 2.将图像通过卷积神经网络 3.利用非极大值抑制(NMS)进行筛选


1号图中显示图片被分为 7 × 7 = 49个grid cell
2号图中显示每个grid cell生成2个bounding box(预测框),一共98个bounding box,框的粗细代表置信度大小,框越粗代表框住的是一个完整物体的概率越大
3号图中用不同颜色表示每个grid cell所预测的物体最可能属于分类,如蓝色的grid cell生成的最可能bounding box最可能框住的是狗、黄色的grid cell最可能预测自行车…
4号图为最终输出的显示效果
结果张量剖面图


也就是说,每个gird cell只能有一个类别,它会从这20个类别概率中选取概率最高的那一个,进而也说明了每个gird cell只能预测一个物体,那么7×7=49个gird cell最多只能预测49个物体,这也是YOLO v1对小密集物体识别差的原因,后面会谈到这一点。
损失函数:

综合来说,一个bounding box的置信度Confidence意味着它 是否包含对象且位置准确的程度。置信度高表示这里存在一个对象且位置比较准确,置信度低表示可能没有对象 或者 即便有对象也存在较大的位置偏差。
更具体一点说,就是在设置训练样本的时候,样本中的每个Object归属到且仅归属到一个grid,即便有时Object跨越了几个grid,也仅指定其中一个。具体就是计算出该Object的bounding box的中心位置,这个中心位置落在哪个grid,该grid对应的输出向量中该对象的类别概率是1(该gird负责预测该对象),所有其它grid对该Object的预测概率设为0(不负责预测该对象)。

对于输入图像中的每个对象,先找到其中心点。比如图8中的自行车,其中心点在黄色圆点位置,中心点落在黄色网格内,所以这个黄色网格对应的30维向量中,自行车的概率是1,其它对象的概率是0。所有其它48个网格的30维向量中,该自行车的概率都是0。这就是所谓的"中心点所在的网格对预测该对象负责"。狗和汽车的分类概率也是同样的方法填写。
NMS原理:
NMS(非极大值抑制)
NMS方法并不复杂,其核心思想是:选择得分最高的作为输出,与该输出重叠的去掉,不断重复这一过程直到所有备选处理完。
YOLO的NMS计算方法如下。
网络输出的7730的张量,在每一个网格中,对象[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XFq2sLth-1682324796827)(https://math.jianshu.com/math?formula=C_i)]位于第j个bounding box的得分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lurUIFkC-1682324796827)(https://math.jianshu.com/math?formula=Score_%7Bij%7D%20%3D%20P(C_i%7CObject)]%20*%20Confidence_j)
它代表着某个对象[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TU1p0okc-1682324796828)(https://math.jianshu.com/math?formula=C_i)]存在于第j个bounding box的可能性。
每个网格有:20个对象的概率*2个bounding box的置信度,共40个得分(候选对象)。49个网格共1960个得分。Andrew Ng建议每种对象分别进行NMS,那么每种对象有 1960/20=98 个得分。
也就是说给每个框都编个号,并且每个编号的框都有一个score属性
NMS步骤如下:
1)设置一个Score的阈值,低于该阈值的候选对象排除掉(将该Score设为0)
2)遍历每一个对象类别
2.1)遍历该对象的98个得分
2.1.1)找到Score最大的那个对象及其bounding box,添加到输出列表
2.1.2)对每个Score不为0的候选对象,计算其与上面2.1.1输出对象的bounding box的IOU
2.1.3)根据预先设置的IOU阈值,所有高于该阈值(重叠度较高)的候选对象排除掉(将Score 设为0)(避免同一对象的重复检测,一个对象只允许存在一个bounding box中)
2.1.4)如果所有bounding box要么在输出列表中,要么Score=0,则该对象类别的NMS完成, 返回步骤2处理下一种对象
3)输出列表即为预测的对象
代码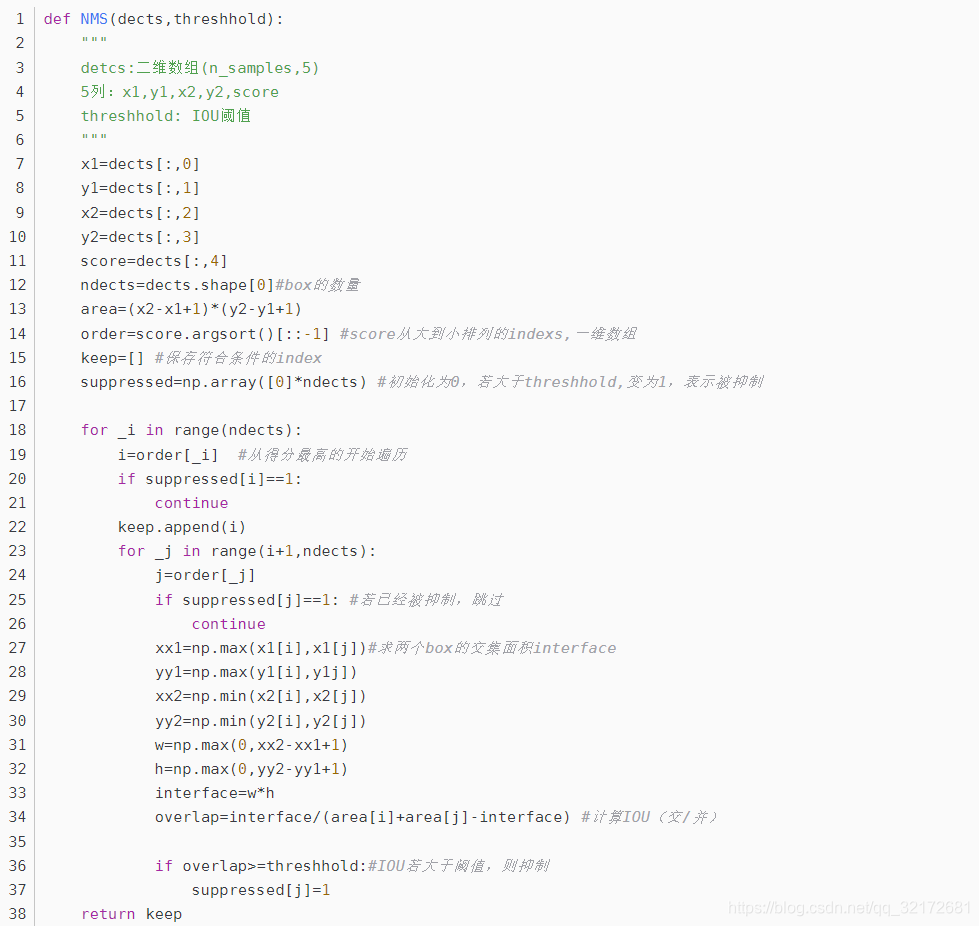
概括的讲就是:
训练过程:首先将图像分成 S × S 网格(gird cell)、然后将图像送入网络,生成S × S × (B ∗ 5 + C)个结果,根据结果求Loss并反向传播梯度下降。
预测过程:首先将图像分成 S × S网格(gird cell)、然后将图像送入网络,生成S × S × (B ∗ 5 + C)个结果,用NMS选出合适的预选框。
缺点:
每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差。
原始图片只划分为7x7的网格,当两个物体靠的很近时,效果比较差。
最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
对于图片中比较小的物体,效果比较差。这其实是所有目标检测算法的通病。
1.4 YOLO v2
原理与贡献:
1.BN层
2.聚类产生框的尺度,可以实现对不同数据集的更好地适应
3.anchor机制,sogmoid限制框中心在grid cell里面
4.多尺度融合,FPN
5.多尺度训练,采用不同的输入图像分辨率
网络结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JHAucAzb-1682324796828)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220715230619149.png)]
1.5 YOLO v3
原理与贡献
整合多个技术
1.修改backbone,为Darknet-53,没有最大池化下采样层,而是用卷积层进行下采样,残差网络。
2.继续特征融合,利用三个特征层,三个尺度的anchor,不同的宽高比。
3.正样本分配新方案,多产生正样本
网络结构

目标边界框的预测,针对左上角的偏移量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uVt34gSa-1682324796828)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220715225329432.png)]
损失函数:
1.6 YOLO v4
原理与贡献:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-33iNrv0A-1682324796829)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20220715230934794.png)]
1.7 YOLO v5
原理与贡献:
不同点有:激活函数上,YOLO V5变成了SiLu和Sigmoid函数,不再使用V4的Mish激活函数;损失函数上,YOLO 系列的损失计算是基于置信度分数,类别概率,和 bbox分数得到的。YOLO V5使用 GIOU Loss作为bounding box的损失,使用二分类交叉熵和 Logits 损失函数计算类概率和目标得分的损失。同时也可以通过fl _ gamma参数来激活Focal loss计算损失函数。而YOLO V4使用 CIOU Loss作为bounding box的损失。
1.8 YOLO vx
2.基于transformer的目标检测
3.弱监督目标检测
目前弱监督目标检测存在的问题:1.只关注最具区分的区域 2.同一类别多实例挨得近被一个框包裹问题
- 同一类别多目标漏检测问题 4.候选框生成速度慢,冗余问题,比如SS算法。
基于伪标签生成机制的弱监督多实例检测模型
伪标签生成机制不同方法:OICR(有代码)、PCL(有代码)、W2F(无代码)、WSOD2(无代码)、TPE(无代码)、SLV(无代码)、CASD(有代码)、OIM(有代码)、MIST(ICMWSD)(有代码)、DKR-MIDN(有代码)、ODCL(有代码)
基于自知识蒸馏机制的弱监督多实例检测模型
3.1 WSDDN
方法和贡献:
WSDDN最大的贡献是提出了一个分别进行分类和定位的双分支的端到端的弱监督深度检测网络。WSDDN首先利用预训练好的卷积神经网络提取候选区域特征,之后连接SPP层使候选框特征图重塑为相同大小的特征向量。接下来,将特征向量输入分类分支和定位分支。具体来说,分类分支负责计算每个区域的类得分,定位分支被设计用来计算每个类存在在每个区域的现有概率。然后,将每个区域的类得分与每个类的现有概率的矩阵乘积作为最终的预测得分。然而,由于在训练阶段只访问图像级标签,因此在训练中,对象中最具区别性的部分将比整个对象实例得到更多的关注。由于上述限制,WSDDN存在鉴别区域问题。
整体示意图:
特征提取阶段:
分类分支阶段:
定位分支阶段:
训练阶段:
存在的问题:
1.用一个检测框包裹了多个目标。
2.只关注最具区分的区域,无法定位目标整体。
3.2 OICR
为了缓解鉴别区域问题,OICR [31]使用WSDDN为基线,并在基线后添加了三个实例分类器细化过程。每个实例分类器细化过程,由两个完全连接的层组成,被设计用来进一步预测每个建议的类分数。由于每个实例分类器细化过程的输出是对其后一个细化过程的监督,OICR可以继续学习,以便更大的区域可以比WSDDN有更高的分数。虽然WSDDN的预测可能只关注对象的判别部分,但它将经过多个实例分类器细化过程后进行细化。
方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0enlgdIY-1682324796829)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20221119105402524.png)]
类别c得分最高框的选择:
损失函数:
3.3 PCL
仅使用图像级注释来训练对象检测器的弱监督对象检测(WSOD)在对象识别中越来越重要。在本文中,我们为WSOD提出了一个新颖的深网。与以前的网络使用多个实例学习(MIL)将对象检测问题转移到图像分类问题的网络不同,利用聚类算法对区域框聚类,进而得到细粒度监督信息并通过迭代过程学习更精致的实例分类器。
同一集群中的区域框在空间相邻,并与同一对象相关联。这样可以防止网络过多地集中在对象的一部分上,进而能够检测对象的全部区域。我们证明对于区域框集群的生成,可以直接分配实例对象或背景标签,例如分类器的细化,然后证明将每个集群视为小型的新包效果比直接分配标签方法更好。迭代实例分类器的细化是使用卷积神经网络中的多个流在线实施的,其中第一个是MIL网络,而其他流则是由前面的分类器进行的,例如分类器细化。实验是对WSOD的Pascal VOC,ImageNet检测和MS-Coco基准进行的。结果表明,我们的方法的表现大大优于先前的艺术状态。
方法:
这个PCL是上一个OICR论文的延伸,主要区别是该方法在细化过程的监督信息生成过程中利用到了聚类算法,生成了伪标签,使效果更好。注意最终测试时是取所有细化过程区域框分数的均值,并利用NMS进行框的生成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SPMLFU5H-1682324796829)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20221119110306623.png)]
主要有三个步骤:
1.寻找聚类中心
两个方法
最高分方法和,基于图的方法
聚类中心包含框位置信息,类别信息,置信度也就是分数信息。
2.生成聚类
对每个框,求它和每个聚类中心的IOU,取最大的IOU,大于阈值就把它分配给这个聚类。不然就分配给背景类别。
3.为细化过程生成监督信息并生成损失函数训练
两种方法:直接分配标签和把聚类看成新的包
(1)直接分配标签法
监督信息H是一个(C+1)R的向量,表示每个框的类别概率。保存了框的索引信息和类别信息。
加入权重系数进行优化:
(2)把每个聚类看成一个新的包进行优化:
3.4 W2F
论文题目:W2F: A Weakly-Supervised to Fully-Supervised Framework for Object Detection
概述:
在本文中,我们提出了一种新的弱监督到全监督框架(W2F)用于目标检测。与以前的工作不同,我们的框架结合了完全监督学习和弱监督学习的优势。我们首先使用WSDNN和OICR来训练一个端到端的弱监督检测器(WSD)。然后利用伪标签挖掘模块(PGE)和伪标签自适应模块(PGA)来从WSD中提炼出高质量的伪标签。最后,将这些伪标签信息输入一个完全监督的检测器,以产生最终的检测结果。对PASCAL VOC 2007和2012年的大量实验表明,与之前的弱监督检测器相比,我们的方法有了显著的改进(mAP分别提升了5.4%和5.3%)。
方法:
就是在OICR基础上提出了PGE模块和PGA模块,PGE生成粗粒度的伪标签,PGA细化伪标签,最后得到最终可以用于完全监督目标检测的伪标签。
总体架构:
PGE算法:
1.先选出分数大于阈值的框 2.用IOU删除被最大框包裹的 3.合并IOU大于阈值的得到粗粒度的伪标签。
PGA算法:
用一个PRN网络来对粗粒度标签改进,主要利用生成的候选框和IOU阈值迭代选择。
3.5 TS2C
3.6 C-MIL
3.7 SDCN
论文题目:Weakly Supervised Object Detection With Segmentation Collaboration
概述:
SDCN 引入了一种分割-检测协作机制。它由一个检测分支和分割分支组成,分别负责检测边界框和生成分割掩模。在SDCN中,通过对每个建议框中的所有像素设置一个分类分数,作为分割分支的监督掩码,将检测结果转换为一个热图。同时,选择分割掩模中与连接区域重叠最大的区域框作为检测分支的伪标签。对检测分支和分割分支交替进行优化和提升,使SDCN比OICR具有更好的检测性能。
方法:
就是用分割和检测相互作用,用分割得到检测的伪标签,用检测得到分割的热图,因为分割能捕捉到目标的整体区域但不能很好地表示物体类别,而检测可以很好地得到物体类别但聚焦于物体最易区分的部分(也就是一个召回率高,一个精确度高)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4R1uVbui-1682324796830)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20221122220309096.png)]
损失函数:
用一个总的损失函数实现端到端训练
数据集是PASCAL VOC 2007和2012,评估指标是AP、mAP和CorLoc。
3.8 C-MIDN
论文题目:
概述:
在本文中,我们提出了一种耦合多实例检测网络。C-MIDN使用两个midn,通过提案删除以互补的方式工作。进一步提出了一种新的分割引导建议去除算法来保证建议去除后的MIL约束。最后,我们将MIDN的输出进行了耦合以获得更紧密的对象边界框,并召回更多的对象。
方法:
就是两个多实例检测网络互补擦除,以实现对目标整体的检测。主要就是C-MIDN和OICR的细化过程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-utJpeG3A-1682324796830)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20221122221323660.png)]
3.9 ICMWSD(重点)
论文题目:Instance-aware, context-focused, and memory-effificient weakly supervised object detection
概述:
ICMWSD提出了弱监督目标检测的三大挑战,分别是==(1)目标实例检测不完整==,即检测数目不够或者一个框包裹了多个同类目标==(2)局部聚焦问题==,只关注目标最易区分的部位而没有检测出目标整体区域==(3)内存消耗过大问题。==因为没有框级真实标签,需要生成很多候选框,造成内存开销过大。
针对上述问题,ICMWSD分别提出了多实例自训练方法选择伪标签提高实例选择精度,利用掩模去除最具区分的区域解决局部聚焦问题,利用分批反向传播解决内存消耗大问题。
方法:
方法总体概述
多实例自训练算法,生成高质量伪标签进行接下来训练
得到后续学生网络的训练函数,分为回归损失和分类损失。
丢弃策略,移除最具区分的区域,迫使模型关注其他上下文信息,达到全局检测目的。
批反向传播,保存部分梯度,减小内存开销。
3.10 SLV(重点)
论文题目:SLV: Spatial Likelihood Voting for Weakly Supervised Object Detection
概述:
在本文中,我们提出了一个空间似然投票(SLV)方法用于弱监督目标检测。我们利用空间似然来生成精度更高的伪标签,同时提出了一种多任务损失函数,缩短弱监督和完全监督目标检测之间的差距。所提出的SLV模块在没有任何边界框注释的情况下收敛了建议的定位过程,并提出了一个端到端训练框架。该框架通过端到端多任务学习获得了更好的分类和定位性能。在VOC 2007年和2012年的数据集上进行的大量实验表明,与之前的WSOD方法相比,我们的方法有了实质性的改进。
方法:
主要就是利用空间似然来对PCL生成的伪标签改进得到精度更高的伪标签,然后利用分类和回归多任务损失对得到的伪标签监督信息做训练,类似全监督学习,最后得到精确的框。
贡献:
主要就是提出了一个伪标签生成机制,改进了WSDDN和PCL生成伪标签不足的问题。
总体框架:
细化过程的分数矩阵被送入SLV模块并形成伪监督信息,就是说它多了一步,没有直接利用细化过程的伪监督信息,而是在后面加了个SLV模块得到最终的伪监督信息
生成伪标签过程:
整体训练过程:
SLV模块示意图
多任务损失:
3.11 OIM(重点看看)
论文题目:Object Instance Mining for Weakly Supervised Object Detection
概述:
本文提出了一种端到端对象实例挖掘框架,以解决现有WSOD方法的局限性。提出了利用空间图和外观图进行对象实例挖掘,使网络能够更好地学习非显著区域特征,在此基础上可以检测到属于同一个类的更多可能的对象。同时提出了对象实例重加权损失,通过学习每个图像中更大部分的目标对象实例来进一步帮助OIM。在两个公开数据集上的实验结果表明,该方法比最先进的WSOD方法具有竞争力或优越的性能。
方法:
解决问题:属于同一个类别的不同实例不能分别检测出来。
解决方法:利用空间图来更好的定位每个实例,利用外观图更好地挖掘同一类别下其他的对象实例。
针对空间图和外观图提出了一个实例重加权的损失函数:
3.12 IM-CFB
论文题目:Instance Mining with Class Feature Banks for Weakly Supervised Object Detection
概述:
在本文中,我们提出了一个具有类特征库(IM-CFB)的实例挖掘框架,该框架能够存储和利用类级信息进行弱监督目标检测。考虑到类内的多样性,类特征银行(CFB)模块被设计用于在线记录和更新边框级信息,为每个类别带来更广泛的视角。利用CFB中记录的特征,引入了特征引导实例挖掘(FGIM)算法来改善MIL分支的区域建议选择。在两个基准数据集,即PASCAL VOC 2007和2012上进行了大量的实验,证明了该方法的有效性。
主要就是利用CFB模块和FGIM算法来对MIL基本框架得到的区域分数作改进,得到更好的伪标签信息、
方法:
最终损失:
把MIL和FGIM和OIR以及最后RCNN的回归损失都加上。
3.13 SLV-SD
论文题目:Spatial likelihood voting with self-knowledge distillation for weakly supervised object detection
概述:
本文提出了一种有效的WSOD框架,称为SLV-SD网络。我们提出将大多数基于mil的模型中的实例分类问题重新定义为多任务问题,以缩小弱监督和完全监督目标检测之间的差距。SLV模块使用区域建议分数来生成准确的实例提升注释,从而收敛模型中的区域建议本地化。利用SLV模块,SD模块细化了图像的特征表示,从而提高了检测性能。在PASCAL VOC 2007/2012和MS-COCO数据集上进行的大量实验结果表明,SLV-SD Net显著提高了性能,优于其他最先进的模型。
方法:
主要是在SLV基础上提出了自适应选择算法以应对单个类别多个实例的情况,同时利用自知识蒸馏的方法来细化图像特征分布,达到全局激活地目的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pc7rkGmV-1682324796830)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20221126222754945.png)]
自适应搜索算法:
效果:
自知识蒸馏算法:
效果:
贡献:
1.解决了单类别多实例问题
2.解决局部聚焦的问题
3.14 DKR-MIDN(重点)
论文题目:Distilling Knowledge from Refifinement in Multiple Instance Detection Networks
概述:
在本文中,我们提出了两个改进来提高OICR方法。首先,我们提出了一种知识蒸馏方法,对细化过程进行加强,来提取额外的知识。其次,我们提出了一个自适应监督聚合函数,它改进了每个细化过程,可以更好的识别同类别下不同的实例。这两种贡献都是使用OICR作为基线方法构建的,并且所提出的贡献能够提供比OICR基线方法高出7.4 mAP的提升。
方法:
主要就是用知识蒸馏对OICR的k个细化过程作加权,同时提出了一个新的损失函数来解决同类别不同实例检测不完整的问题。
知识蒸馏:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2sfnv6RO-1682324796831)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20221126233058428.png)]
自适应聚合函数
贡献:
1.同类别不同实例检测不完整。
3.15 WSOD2
论文题目:WSOD2 : Learning Bottom-up and Top-down Objectness Distillation for Weakly-supervised Object Detection
概述:
在本文中,我们提出了一种新的弱监督目标检测与自下而上和自顶向下的目标蒸馏来提高CNN的深度目标性表示。利用自底而上的对象证据来测量边界框包含一个完整目标的概率,并以自适应训练的方式在CNN中提取边界特征。我们还提出了一种以端到端方式集成了边界框回归和渐进式实例分类器的训练策略。我们用我们的方法对WSOD任务的一些标准数据集和设置进行了实验。
方法:
主要就是对伪标签生成进行了改进,同时在OICR上加入了回归分支。
3.16 HQP
论文题目:High-Quality Proposals for Weakly Supervised Object Detection
概述:
本文提出了一种有效的弱监督目标检测方法,该方法是通过在最先进的OICR系统[2]中添加两个重要的模块来实现的。一种是提案生成,它侧重于用更高的欠条生成更多的对象提案。另一个是提案选择,目的是选择尽可能多的积极提案,挖掘歧视性的硬否定,使培训更有效。在PASCAL VOC 2007和2012数据集和MS COCO数据集上的实验结果表明,与现有的WSOD方法相比,我们的方法显著提高了基线方法OICR [2],并取得了最先进的结果。
方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XjD4hn8P-1682324796831)(C:\Users\Louis\AppData\Roaming\Typora\typora-user-images\image-20221129233201605.png)]
就是提出了候选框生成和候选框选择两个模块。
具体来说,提案生成模块的目的是获得更多高质量的提案框,与真实标签有更高的IOU,从而可以更好地适合整个对象。提案选择是一种迭代操作,目的是自适应地选择正实例的提案框,同时挖掘负实例以细化目标检测器。
3.17 TPE
论文题目:Towards Precise End-to-end Weakly Supervised Object Detection Network
概述:
大多数现有的WSOD方法倾向于使用多阶段的学习方法,即首先使用多实例学习检测器生成伪标签,然后使用带有边界盒回归的完全监督学习检测器。根据我们的观察,这个过程可能会导致某些对象类别的局部极小值。在本文中,我们建议以端到端的方式联合训练这两个阶段来解决这个问题。具体来说,我们设计了一个单一的网络,其中的多个实例学习和边界盒回归分支共享相同的主干。同时,在主干中添加一个基于分类损失的引导注意模块,以有效地提取特征中的隐式位置信息。在公共数据集上的实验结果表明,该方法取得了最先进的性能
方法:
就是多加了个回归分支,代替了两阶段的全监督模型,融合成一个端到端的模型。
并且提出了一个注意力模块来加强特征的提取。
3.18 ODCL
论文题目:Object Discovery via Contrastive Learning for Weakly Supervised Object Detection
概述:
我们提出了一种新的多实例标记方法来取代传统的基于目标的伪标签标记方法。为此,我们为WSOD设置引入了一个对比损失,该设置为同一类中的区域框学习一致的嵌入特征,而对不同类中的区域框学习区别特征。有了这些特性,就可以挖掘大量可靠的伪标签,从而为WSOD任务提供更丰富的监督。
方法:
就是利用了对比学习获得类别的嵌入特征,进而得到更精确的伪标签。
提出了一个采样策略来生成类别的嵌入特征,进而对其实例进行挖掘。
第一步是IOU采样,获得与最高分IOU大于阈值的区域框。第二步是随机掩模。第三步是加入高斯噪声。最终可以获得对应地嵌入特征。
然后根据对比学习方法,获取到其他的同一类别的实例,得到其伪标签。
并提出了一个损失函数:
伪标签生成机制不同方法:OICR、PCL、W2F、OAIL、WSOD2、SLV、CASD、OIM、MIST(ICMWSD)、TPE。
e Learning for Weakly Supervised Object Detection**
概述:
我们提出了一种新的多实例标记方法来取代传统的基于目标的伪标签标记方法。为此,我们为WSOD设置引入了一个对比损失,该设置为同一类中的区域框学习一致的嵌入特征,而对不同类中的区域框学习区别特征。有了这些特性,就可以挖掘大量可靠的伪标签,从而为WSOD任务提供更丰富的监督。
方法:
就是利用了对比学习获得类别的嵌入特征,进而得到更精确的伪标签。
提出了一个采样策略来生成类别的嵌入特征,进而对其实例进行挖掘。
第一步是IOU采样,获得与最高分IOU大于阈值的区域框。第二步是随机掩模。第三步是加入高斯噪声。最终可以获得对应地嵌入特征。
然后根据对比学习方法,获取到其他的同一类别的实例,得到其伪标签。
并提出了一个损失函数:
伪标签生成机制不同方法:OICR、PCL、W2F、OAIL、WSOD2、SLV、CASD、OIM、MIST(ICMWSD)、TPE。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









