







一、基础语法学习
都是最基础的语法, 基于学习文档, 再拓展去学习具体的一些语法
1. hello, world! - print() 函数
print("Hello, Python World!")2. 变量小能手 - type() 和 str()
x = 5
print(type(x)) # 输出 <class 'int'>
y = str(x) # 将整数转为字符串3. 条件判断 - if、elif、else
age = 20
if age >= 18:
print("成年人")4. 循环大法好 - for、while
for i in range(5):
print(i)5. 列表造房子 - [] 和 append(), 创建并添加元素。
fruits = ["apple", "banana"]
fruits.append("orange")6. 字典钥匙和门 - {} 和 keys(), 存储键值对。
person = {"name": "Alice", "age": 25}
print(person.keys())7. 函数是魔法 - def,封装重复代码。
def greet(name):
return f"Hello, {name}!"8. 异常处理 - try、except, 遇到错误不慌张。
try:
num = int("abc")
except ValueError:
print("这不是数字!")9. 模块大援军 - import, 导入外部库增强功能。
import math
pi = math.pi10. 字符串艺术 - split() 和 join(), 分割和组合文本。
words = "hello world".split()
print("-".join(words))11. 文件操作入门 - open() 和 read(), 读写文件内容。
a. open()函数是Python内置的用于打开文件的函数。它提供了许多参数和选项,用于控制文件的打开方式、读写操作和文件对象的属性。下面介绍 open()函数的作用、参数和使用方法。
b. open()函数的基本语法如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)open()函数有多个参数,下面对每个参数进行详细说明:
-
file:要打开的文件路径或文件名。可以是相对路径或绝对路径。 -
mode:打开文件的模式。默认为'r'(只读模式)。支持的模式有:-
'r':只读模式。从文件开头开始读取。 -
'w':只写模式。清空文件内容并从头开始写入,如果文件不存在则创建新文件。 -
'x':独占创建模式。仅在文件不存在时创建新文件,如果文件已存在则抛出FileExistsError异常。 -
'a':追加模式。在文件末尾追加内容,如果文件不存在则创建新文件。 -
'b':二进制模式。以二进制格式打开文件。 -
't':文本模式(默认)。以文本格式打开文件。 -
'+':读写模式。可同时读取和写入文件。
-
-
buffering:缓冲大小。用于控制文件的缓冲行为。默认值为-1,表示使用系统默认缓冲区大小。0表示不缓冲,1表示行缓冲,大于1的整数表示缓冲区大小。 -
encoding:文件编码方式。用于指定读写文件时的字符编码方式,如'utf-8'、'gbk'等。默认为None,表示使用系统默认编码。 -
errors:编码错误处理方式。用于指定在编码/解码过程中遇到错误时的处理方式,如'strict'(默认,抛出UnicodeError异常)、'ignore'(忽略错误)、'replace'(用特定的占位符替代错误字符)等。 -
newline:换行符处理方式。用于指定在文本模式下的换行符处理方式,如None(保持系统默认)、''(不进行换行符转换)、'\n'(转换为LF换行符)等。 -
closefd:文件描述符关闭方式。默认为True,表示在文件关闭时同时关闭底层文件描述符。如果为False,则文件关闭时不关闭底层文件描述符。 -
opener:自定义开启器。用于指定一个自定义的开启器(函数或类),用于在打开文件之前执行一些额外操作。
c. 使用方法
1.打开文件进行读取:
with open('file.txt', 'r') as file:
content = file.read()
# 使用file对象进行读取操作
# 文件会在离开with语句块后自动关闭在上述例子中,通过 open('file.txt', 'r')打开名为 file.txt的文件,并返回一个文件对象。使用 'r'模式表示以只读模式打开文件。在 with语句块中,可以使用文件对象进行读取操作,读取的内容赋给 content变量。
2. 打开文件进行写入:
with open('file.txt', 'w') as file:
file.write('Hello, World!')
# 使用file对象进行写入操作
# 文件会在离开with语句块后自动关闭 在上述例子中,通过 open('file.txt', 'w')以只写模式打开文件。在 with语句块中,使用文件对象的 write()方法将字符串 'Hello, World!'写入文件。
3.使用其他打开模式:
with open('file.txt', 'a+') as file:
file.write('Hello, World!')
file.seek(0)
content = file.read()
# 使用file对象进行写入和读取操作
# 文件会在离开with语句块后自动关闭 在上述例子中,使用 'a+'模式以追加模式打开文件,并允许读写操作。使用 file.write()方法追加字符串到文件末尾,然后使用 file.seek(0)将文件指针移到文件开头,最后使用 file.read()读取文件内容。
4. 综合示例
# 写入文件
with open('file.txt', 'w') as file:
file.write('Hello, World!')
# 读取文件
with open('file.txt', 'r') as file:
content = file.read()
print(content) # 输出:Hello, World!
# 追加内容
with open('file.txt', 'a') as file:
file.write('\nWelcome to Python!')
# 读取更新后的文件
with open('file.txt', 'r') as file:
content = file.read()
print(content)
# 输出:
# Hello, World!
# Welcome to Python 在上述示例中,首先以只写模式打开文件,并使用 write()方法写入内容。然后以只读模式打开文件,使用 read()方法读取文件内容并打印。接下来以追加模式打开文件,并使用 write()方法在文件末尾追加内容。最后再次以只读模式打开文件,验证文件内容是否更新。
4. 复合打开模式
除了常见的单一打开模式,open()函数还支持一些常用的复合打开模式,它们是通过组合多个模式字符来实现的。下面介绍几种常见的复合打开模式:
-
'r+':读写模式。以读写方式打开文件。可以读取和写入文件内容,文件指针位于文件开头。如果文件不存在,则会抛出FileNotFoundError异常。 -
'w+':读写模式。清空文件内容并以读写方式打开文件。可以读取和写入文件内容,文件指针位于文件开头。如果文件不存在,则创建新文件。 -
'a+':读写模式。以追加和读取方式打开文件。可以读取和写入文件内容,文件指针位于文件末尾。如果文件不存在,则创建新文件。
这些复合模式允许同时进行读取和写入操作,可以在打开文件后根据需要随时进行读写操作。以下是示例代码:
# 读写模式
with open('file.txt', 'r+') as file:
content = file.read()
print(content) # 输出文件内容
file.write('Hello, World!')
file.seek(0) # 将文件指针移到文件开头
updated_content = file.read()
print(updated_content) # 输出更新后的文件内容
# 清空并读写模式
with open('file.txt', 'w+') as file:
file.write('Hello, World!')
file.seek(0)
content = file.read()
print(content) # 输出文件内容
# 追加并读写模式
with open('file.txt', 'a+') as file:
file.write('\nWelcome to Python!')
file.seek(0)
content = file.read()
print(content) # 输出文件内容 在上述示例中,使用了 'r+'、'w+'和 'a+'这三种复合打开模式。首先以读写模式打开文件,读取文件内容并打印,然后在文件末尾追加内容,再次将文件指针移到文件开头,读取更新后的文件内容。接下来以清空并读写模式打开文件,写入内容后读取文件内容并打印。最后以追加并读写模式打开文件,追加内容后再次读取文件内容并打印。
使用复合打开模式可以方便地在同一个文件对象上进行读写操作,非常实用。根据具体需求选择适合的复合打开模式,以便灵活地处理文件操作。
12. 列表推导式 - 列表生成器,简洁高效。
列表推导式是Python中一种创建列表的简洁语法,它允许在一行代码中生成列表。基本语法为 [expression for item in iterable],其中 expression 是对每个 item 进行的操作,iterable 是可迭代对象,如列表、元组、字符串等。12
列表推导式的使用方式如下:
- 基础用法。假设有一个包含数字1到9的列表,想要创建一个新列表,包含这些数字的平方。可以使用列表推导式轻松实现:
squares = [x2 for x in numbers]。这将输出 `[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]`,即原列表中每个数字的平方。 - 使用条件语句。可以在列表推导式中加入条件语句,过滤掉不需要的元素。例如,只想要平方小于50的数字,可以写作:
squares_less_than_50 = [x2 for x in numbers if x2 < 50]。 - 嵌套的列表推导式。列表推导式可以嵌套使用,处理更复杂的数据结构。例如,展平一个嵌套列表:
flattened_list = [x for sublist in nested_list for x in sublist]。 - 与函数一起使用。列表推导式可以与函数一起使用,生成新的列表。例如,将字符串中的每个字符转换为其ASCII码:
new_list = [ord(x) for x in 'hello']。
列表推导式的执行顺序遵循嵌套关系,最外层的语句在左,依次往右进一层,最后一层的语句在右。这种语法不仅使代码更加简洁和清晰,而且提高了编程效率。
# 基础用法
numbers = range(10)
squares = [x ** 2 for x in numbers]
print(squares)
# 控制台输出 [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 使用条件语句
squares_less_than_50 = [x**2 for x in numbers if x**2 < 50]
print(squares_less_than_50)
# 嵌套的列表推导式
flattened_list = [(x * y) for y in numbers_b for x in numbers]
print(flattened_list)
# 与函数一起使用
new_list = [ord(x) for x in 'hello']
print(new_list)13. 元组不可变 - () 和 tuple(), 安全存储不可变数据。
coordinates = (1, 2, 3)
print(coordinates[0]) # 输出 114. 集合的独特性 - {} 和 set(), 去重神器。
fruits = {"apple", "banana", "apple"}
unique_fruits = set(fruits)
print(unique_fruits)15. 类与对象 - class, 创建自定义数据结构。
class Dog:
def __init__(self, name):
self.name = name
dog = Dog("Rex")16. 装饰器魔法棒 - @decorator, 动态修改函数行为。
a. 什么是装饰器
装饰器放在一个函数开始定义的地方,它就像一顶帽子一样戴在这个函数的头上。和这个函数绑定在一起。在我们调用这个函数的时候,第一件事并不是执行这个函数,而是将这个函数做为参数传入它头顶上这顶帽子,这顶帽子我们称之为装饰器 。
b. 装饰器的使用方法
@ 符号是装饰器的语法糖,一般情况下我们使用@函数名或者@类名来使用装饰器。
c. 函数装饰器
函数装饰器 = 高阶函数 + 嵌套函数 + 闭包
• 高阶函数:外层函数可以接收内层函数作为参数
• 函数嵌套 :内函数作为外函数的参数使用
• 闭包 :外部函数返回内部函数的函数名,内部函数能够使用外部函数的自由变量
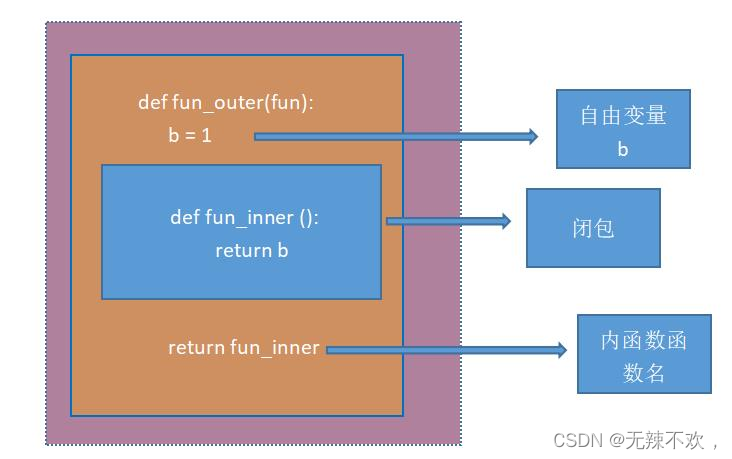
(1)不带参数的函数装饰器(日志打印器)
实现的功能是:在函数执行前,先打印一行日志“Before”,在函数执行完,再打印一行日志“After”。
代码如下:
#coding=utf-8
# -*- coding=utf-8 -*-
#不带参数装饰器
def dec1_outer(func):
def dec1_inner():
print("Before")
#函数真正执行的地方
func()
print("After")
return dec1_inner
@dec1_outer
def func():
print('func')
func()以上代码定义了一个装饰器函数dec1_outer,当我们在func函数前加上@dec1_outer时,就等于给func函数使用了dec1_outer这个装饰器。所以func()在运行前会先将函数名func作为参数传给装饰器函数,这个语句等价于func = dec1_outer(func)。装饰器函数在接收到参数后执行,先返回内函数的函数名dec1_inner,此时18行的func()相当于调用了dec1_inner(),即进行了dec1_inner函数的操作。func函数真正执行的地方则是第9行的那段代码。
以上对装饰器的使用相当于:
func = dec1_outer(func)
func()(2)带参数的函数装饰器
带参数的函数装饰器常用于定时发送邮件等场景,但是代码过于复杂,不利于讲解。以下代码实现的是在装饰器里传入一个参数,指明国籍,并在函数执行前,用自己国家的母语打一个招呼。
代码如下:
#coding=utf-8
# -*- coding=utf-8 -*-
#带参数的装饰器
def dec2_para(country):
def dec2_outer(func):
def dec2_inner(*args, **kwargs):
if country == "中国":
print("你好!")
elif country == 'America':
print("Hello!")
else:
print("Where are you from?")
#函数真正执行的地方
func(*args, **kwargs)
return dec2_inner
return dec2_outer
@dec2_para('中国')
def Chinese():
print("中国")
@dec2_para('America')
def American():
print("America")
Chinese()
print('----------------------')
American()运行结果:
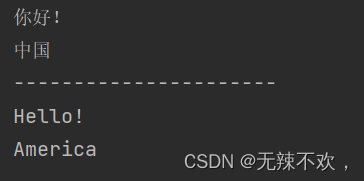
以上代码的装饰器dec2_para采用了两层嵌套,所以Chinese()在运行前会先将‘中国’作为参数传值给dec2_para,装饰器函数在接收到参数后返回dec2_outer函数名。接下来Chinese函数的函数名Chinese会作为参数传给装饰器函数,dec2_outer接收到参数后返回dec2_inner函数名。26行的Chinese()此时相当于调用了dec2_inner(),即进行了dec2_inner函数的操作,dec2_inner会先判断传入的country参数值输出相应的消息。Chinese函数真正执行的地方则是第14行的那段代码。
以上对装饰器的使用相当于:
Chinese = dec2_para('中国')(Chinese)
Chinese()d. 类装饰器
在我们的代码中如果有出现不同装饰器需要部分功能重叠时,使用类装饰器能使代码更加简洁。比方说有时你只想打印日志到一个文件。而有时你想把引起你注意的问题发送到一个email,同时也保留日志,留个记录。这是一个使用继承的场景,我们可以用类来构建装饰器。
类作为装饰器,需要重写__call__方法。
(1)不带参数的类装饰器:
代码如下:
#coding=utf-8
from functools import wraps
class logit(object):
def __init__(self, logfile='out.log'):
self.logfile = logfile
def __call__(self, func):
@wraps(func)
def wrapped_function(*args, **kwargs):
log_string = func.__name__ + " was called"
print(log_string)
# 打开logfile并写入
try:
with open(self.logfile, 'a') as opened_file:
# 现在将日志打到指定的文件
opened_file.write(log_string + '\n')
except IOError as e:
print(e)
# 现在,发送一个通知
self.notify()
return func(*args, **kwargs)
return wrapped_function
def notify(self):
# logit只打日志,不做别的
pass
class email_logit(logit):
'''
一个logit的实现版本,可以在函数调用时发送email给管理员
'''
def __init__(self, email='admin@myproject.com', *args, **kwargs):
self.email = email
super(email_logit, self).__init__(*args, **kwargs)
def notify(self):
# 发送一封email到self.email
# 这里就不做实现了
print('send')
@email_logit()
def myfunc1():
print("func1")
@logit()
def myfunc2():
print("func2")
myfunc1()
print("-----------------------")
myfunc2()运行结果 :
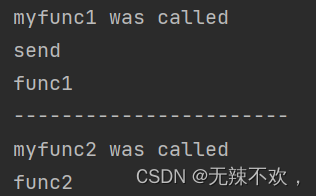
以上代码,logit是一个类装饰器,它的功能是将函数运行情况记录在out.log文件中。email_logit同样是一个类装饰器,他继承了logit类,并增加了新的功能,即发送email的功能(这部分功能用print('send')代替)。@email_logit相当于 myfun1 = email_logit(myfun1)即,myfun1指向了 email_logit(myfun1)这个对象,func指向了函数myfunc1的函数名。
调用myfun1对象的时候相当于调用类email_logit的__call__方法,调用__call__方法的时候,先执行将函数运行日志写到out.log文件,然后再执行22行的func(*args, **kwargs) ,因为func函数指向的是myfunc1函数,所以func(*args, **kwargs)相当于执行myfun1()。
以上对类装饰器的使用相当于:
myfun1 = email_logit(myfun1)
myfun1()
(2)带参数的类装饰器
#coding=utf-8
# -*- coding=utf-8 -*-
#带参数的类装饰器
class dec4_monitor(object):
def __init__(self, level = 'INFO'):
print(level)
self.level = level
def __call__(self, func):#接收函数
def call_inner(*args, **kwargs):
print("[%s]:%s is running"%(self.level, func.__name__))
func(*args, **kwargs)
return call_inner #返回函数
@dec4_monitor(level = 'WARNING')
def func_warm(warn):
print(warn)
func_warm("WARNING Message!")运行结果:
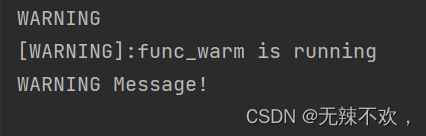
类装饰器和函数装饰器一样也可以实现参数传递,上面的代码给装饰器传递了一个level值"WARNING"。@dec4_monitor(level = 'WARNING')相当于 func_warm = dec4_monitor(level = "WARNING")(func_warm)即,func_warm指向了 dec4_monitor(level = "WARNING")(func_warm)这个对象,func指向了函数func_warm的函数名。
调用myfun1对象的时候相当于调用类dec4_monitor的__call__方法,调用__call__方法的时候,输出相关信息[WARNING]:func_warm is running,然后再执行12行的func(*args, **kwargs) ,因为func函数指向的是func_warm函数,所以func(*args, **kwargs)相当于执行func_warm()。
以上对类装饰器的使用相当于:
func_warm = dec4_monitor(level = "WARNING")(func_warm)
func_warm("WARMING Message")e. 以下就不写了, 我也看不懂了, 如果有兴趣的话可以搜索一下Python——装饰器(Decorator)
17. 异常链追踪 - raise 和 try-except, 显示异常详情。
try:
raise ValueError("Custom error")
except ValueError as e:
print(e)18. 迭代器解密 - iter() 和 next(), 遍历序列更轻量级。
详情学习请跳转: Python迭代器iter使用及python iter( )函数介绍
numbers = [1, 2, 3]
iterator = iter(numbers)
print(next(iterator)) # 输出 119. lambda表达式 - 快速创建小型匿名函数。
double = lambda x: x * 2
print(double(5)) # 输出 1020. 函数式编程 - map()、filter(), 高阶函数处理数据。
a. 在Python中,filter()是一个非常有用的内置函数,它能够根据指定的函数来筛选出可迭代对象中满足条件的元素,返回一个迭代器。filter()函数的使用能够简化代码,并提高程序的可读性。本文将从入门到精通,全面介绍filter()函数的用法和相关知识点。
b. filter()函数的基本用法
filter()函数的基本语法如下:
filter(function, iterable)其中,function是一个用于判断的函数,iterable是一个可迭代对象,可以是列表、元组、集合或字符串等。filter()会将iterable中的每个元素依次传给function进行判断,返回满足条件的元素组成的迭代器。 让我们来看一个简单的例子,使用filter()函数过滤出列表中的偶数:
# 定义一个函数,判断是否为偶数
def is_even(num):
return num % 2 == 0
# 待筛选的列表
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 使用filter函数过滤出偶数
filtered_numbers = filter(is_even, numbers)
# 将filter的结果转换为列表
result = list(filtered_numbers)
print(result) # 输出: [2, 4, 6, 8, 10]c. 使用Lambda表达式进一步简化代码
有时候,我们只需要使用一次性的简单函数进行筛选,此时可以使用Lambda表达式,从而省略单独定义函数的步骤,使代码更加简洁。以上面的例子为例,我们可以改写为:
# 待筛选的列表
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 使用Lambda表达式过滤出偶数
filtered_numbers = filter(lambda x: x % 2 == 0, numbers)
# 将filter的结果转换为列表
result = list(filtered_numbers)
print(result) # 输出: [2, 4, 6, 8, 10]d. filter()函数的返回值是迭代器
需要注意的是,filter()函数的返回值是一个迭代器(Iterator),而不是列表。这意味着在进行一次迭代之后,迭代器中的元素就会被耗尽。如果需要多次访问结果,可以将它转换为列表或使用循环来逐个访问。
# 待筛选的列表
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 使用Lambda表达式过滤出偶数
filtered_numbers = filter(lambda x: x % 2 == 0, numbers)
# 转换为列表
result_list = list(filtered_numbers)
print(result_list) # 输出: [2, 4, 6, 8, 10]
# 再次尝试访问迭代器中的元素将为空
for num in filtered_numbers:
print(num) # 不会输出任何内容e.过滤多个可迭代对象
filter()函数还可以同时过滤多个可迭代对象,此时传入的函数应该接受相应数量的参数。filter()会将多个可迭代对象中的元素按位置一一传入函数进行判断。
# 定义一个函数,判断两个数之和是否为偶数
def sum_is_even(a, b):
return (a + b) % 2 == 0
# 待筛选的列表
numbers1 = [1, 2, 3, 4, 5]
numbers2 = [10, 20, 30, 40, 50]
# 使用filter函数过滤出两个数之和为偶数
filtered_numbers = filter(sum_is_even, numbers1, numbers2)
# 将filter的结果转换为列表
result = list(filtered_numbers)
print(result) # 输出: [3, 5]f. 使用None作为判断函数
在某些情况下,我们可能希望直接使用filter()函数来过滤掉可迭代对象中的一些"假值",例如空字符串、零等。此时,可以将filter()的函数参数设置为None,filter()函数会自动过滤掉那些判断为假的元素。
# 待筛选的列表,包含一些空字符串和非空字符串
words = ["hello", "", "world", " ", "python", ""]
# 使用filter函数过滤掉空字符串
filtered_words = filter(None, words)
# 将filter的结果转换为列表
result = list(filtered_words)
print(result) # 输出: ["hello", "world", " ", "python"]g.综合示例:筛选出年龄大于等于18岁的成年人
# 待筛选的字典列表,每个字典包含姓名和年龄信息
people = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 17},
{"name": "Charlie", "age": 19},
{"name": "David", "age": 15},
{"name": "Eva", "age": 22},
]
# 定义一个函数,判断是否为成年人(年龄大于等于18岁)
def is_adult(person):
return person["age"] >= 18
# 使用filter函数过滤出成年人
adults = filter(is_adult, people)
# 将filter的结果转换为列表
adults_list = list(adults)
print(adults_list) # 输出: [{'name': 'Alice', 'age': 25}, {'name': 'Charlie', 'age': 19}, {'name': 'Eva', 'age': 22}]h. 总结
本文详细介绍了filter()函数在Python中的用法,从基本的使用方法到进阶的应用,包括使用Lambda表达式、过滤多个可迭代对象、使用None作为判断函数等。filter()函数是Python中一个强大且灵活的工具,能够简化代码并提高开发效率。通过掌握filter()函数的各种用法,你可以更加高效地处理可迭代对象,实现自己的业务逻辑。希望本文能够帮助你深入理解和应用filter()函数。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









