






在cmd中进入数据库的操作时mysql -u root -p
选择数据库操作用 USE test_db;
![]()
相关概念
Sql是操作关系型数据库的编程语言
关系型数据库:建立在关系模型基础上,由多张相互连接的二维表组成的数据库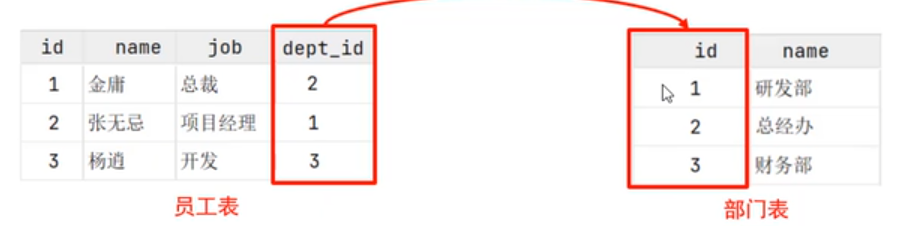
语法
数据类型
整型
| 类型 | 字节 | 范围(有符号) | 描述 |
|---|---|---|---|
TINYINT | 1 | -128 ~ 127 | 小整数 |
SMALLINT | 2 | -32,768 ~ 32,767 | 较小整数 |
INT / INTEGER | 4 | -2,147,483,648 ~ 2,147,483,647 | 常用整数 |
BIGINT | 8 | ±9.22×10¹⁸ | 超大整数 |
浮点型
| 类型 | 描述 |
|---|---|
FLOAT(M, D) | 单精度浮点数(约 7 位精度) |
DOUBLE(M, D) | 双精度浮点数(约 16 位精度) |
DECIMAL(M, D) | 精确小数(用于财务/货币) |
字符串型
| 类型 | 描述 | 最大长度 |
|---|---|---|
CHAR(n) | 固定长度字符串 | 最多 255 字节 |
VARCHAR(n) | 可变长度字符串 | 最多 65,535 字节(受行限制) |
TEXT | 长文本(不支持默认值) | 最多 65,535 字节 |
日期时间类型
| 类型 | 格式 | 描述 |
|---|---|---|
DATE | YYYY-MM-DD | 日期 |
DATETIME | YYYY-MM-DD HH:MM:SS | 日期 + 时间(无时区) |
TIMESTAMP | YYYY-MM-DD HH:MM:SS | 日期 + 时间(自动时区转换) |
TIME | HH:MM:SS | 时间 |
YEAR | YYYY | 年 |

sql语法分类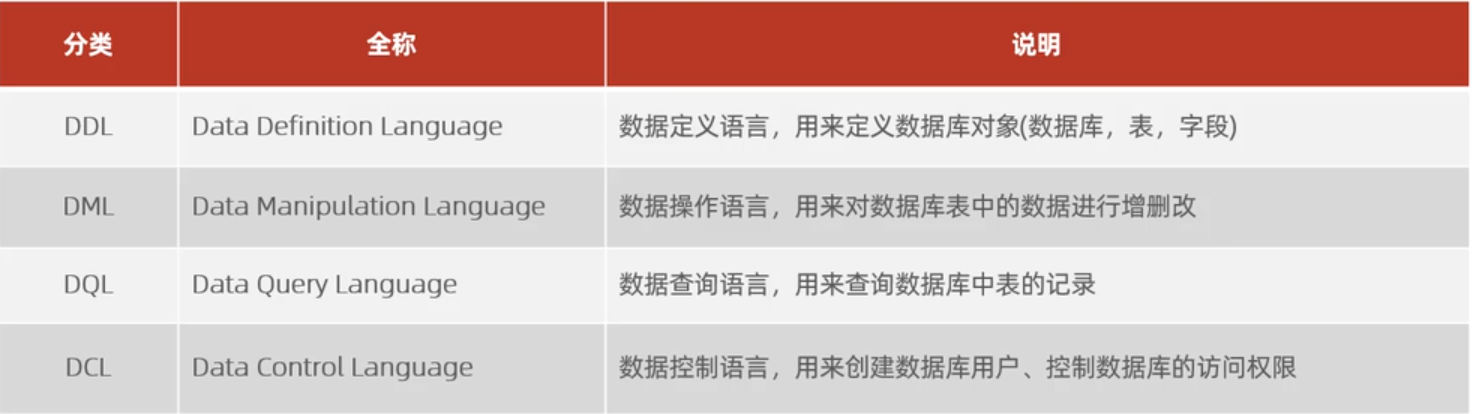
DDL-数据库操作
- 创建:CREATE DATABASE db_name;
- 创建完整的:CREATE
- 删除:DROP DATABASE db_name;
- 查询所有数据库:SHOW DATABASES ;
- 查询一个:SELECT DATABASE db_name;
DDL-数据表操作
- 查询所有表:SHOW TABLES;
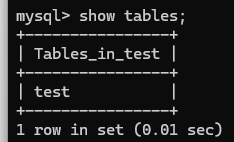
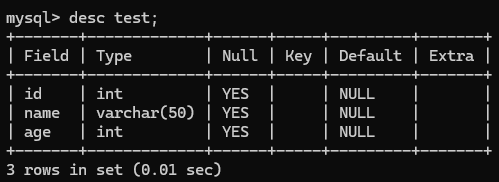
- 查询表结构:DESC table_name;
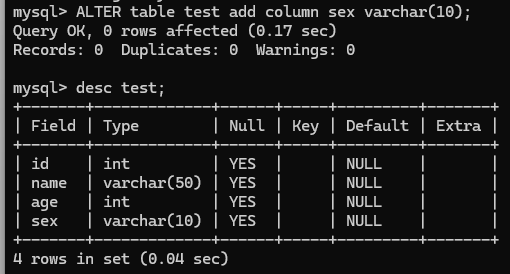
- 修改表:ALTER TABLE table_name ADD column_name datatype;
- 修改列类型或名称
ALTER TABLE table_name MODIFY column_name new_datatype;
ALTER TABLE table_name CHANGE old_column_name new_column_name datatype; - 删除列
ALTER TABLE table_name DROP COLUMN column_name; - 重命名表
RENAME TABLE old_table_name TO new_table_name; - 删除表:DROP TABLE table_name;
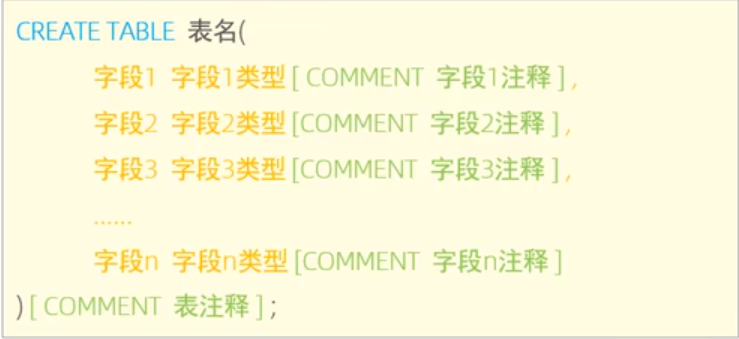
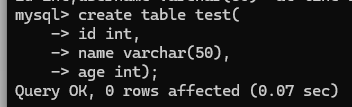
创建表:CREATE TABLE table_name (
column1 datatype [constraints],
column2 datatype [constraints],
);
DML-数据操作(增删改)
- 给指定字段添加数据:INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);

- 给字段插入多行数据:INSERT INTO table_name (col1, col2) VALUES (value1_1, value1_2),(value2_1, value2_2);

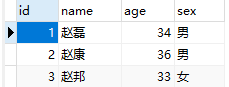
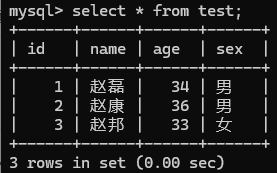
- 省略字段名添加(字段顺序必须匹配):INSERT INTO table_name VALUES (value1, value2, ...);
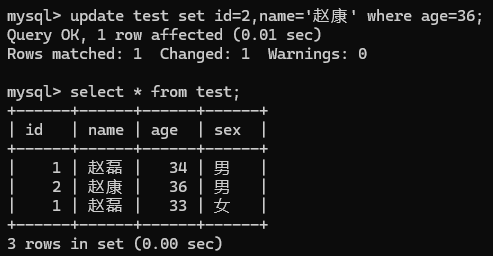
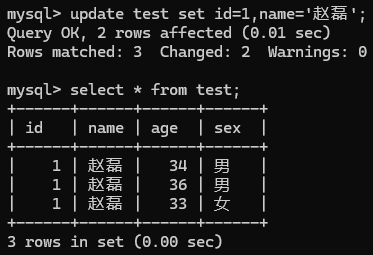
- 更新数据:UPDATE table_name SET column1 = value1, column2 = value2 [WHERE condition];
- 不加where限制条件就会修改全部行, 加了限制年龄为36的修改为赵康
- 删除数据:DELETE FROM table_name WHERE condition;不加where是指删了整张表的数据
DQL-数据查询语言
SELECT [DISTINCT] column1, column2, ...
FROM table_name
[WHERE condition]
[GROUP BY column]
[HAVING condition]
[ORDER BY column [ASC|DESC]]
[LIMIT offset, count];
- 基本查询:查询相关列SELECT column1, column2, ...FROM table_name;
查询全部:SELECT * FROM table_name;
设置别名查询:SELECT column1 AS 别名1, column2 AS 别名2...FROM table_name;
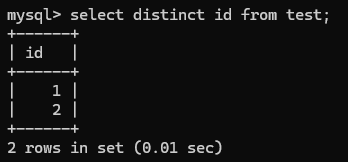
去掉重复记录查询:SELECT DISTINCT column1FROM table_name;
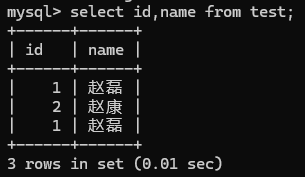
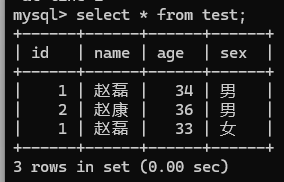
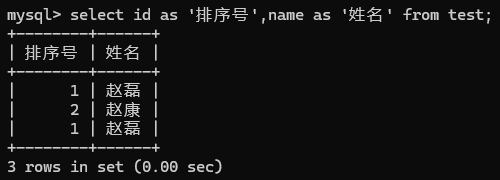
- 条件查询(WHERE):条件包括
操作符 / 关键字 含义 =等于 !=或<>不等于 >/<大于 / 小于 >=/<=大于等于 / 小于等于 BETWEEN a AND b在区间内(含边界) IN (a, b, ...)值在集合中,满足其一即可 NOT IN (...)值不在集合中 LIKE模糊匹配 NOT LIKE不匹配 IS NULL是空值 IS NOT NULL不是空值 AND/OR逻辑与 / 或 NOT逻辑非 EXISTS/NOT EXISTS子查询结果存在 / 不存在 REGEXP正则匹配(大小写敏感) LIKE BINARY严格区分大小写的模糊匹配 通配符 含义 示例说明 %匹配任意数量的任意字符(包括0个) 'a%':以 a 开头的任意字符串_匹配任意一个字符 'a_':a 开头且后面跟一个任意字符[]匹配指定范围内的任一字符(仅某些版本支持) '[a-c]%':以 a、b 或 c 开头的[^]排除某些字符(仅某些版本支持) '[^a]%':不以 a 开头的



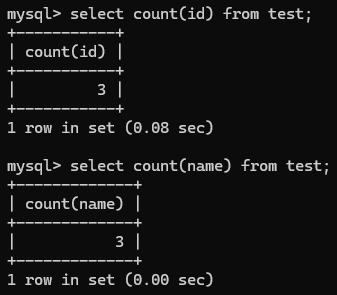
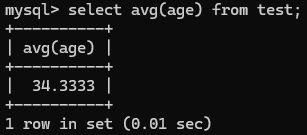
- 聚合参数(count,max,min,avg,sum):SELECT 函数(column1) FROM table_name;
- 分组查询(GROUP BY):
SELECT column1, column2, ...FROM table_name [WHERE condition] GROUP BY 分组字段名 [HAVING 过滤条件];
比如根据性别分组,统计男性和女性的数量,以及平均年龄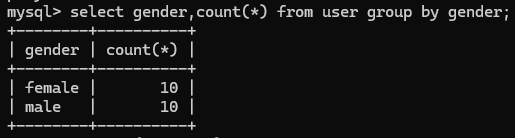
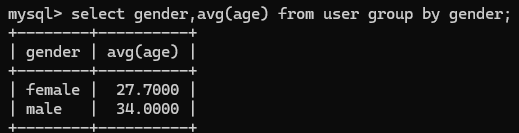
!!一般的分组查询select后面跟的都是分组字段和聚合函数 - 排序查询(ORDER BY):SELECT 字段列表 FROM 表明 ORDER BY 字段1 排序方式1,字段2 排序方式2;支持多字段排序,ASC升序(默认),DESC降序
!!如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
eg. 根据年龄进行排序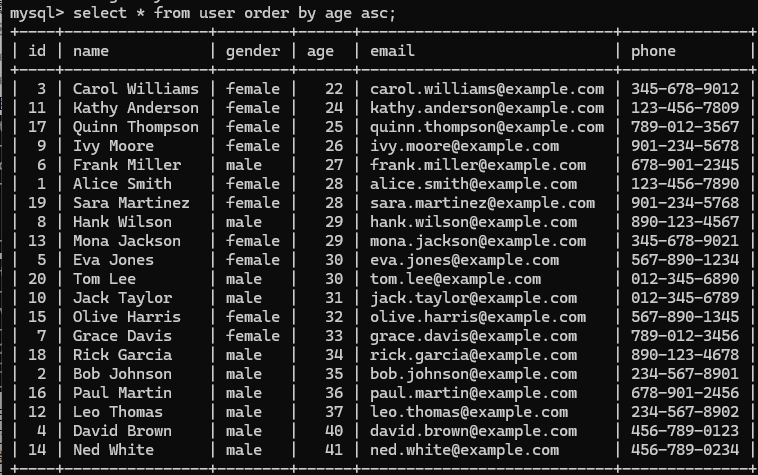
- 分页查询(LIMIT):SELECT 字段列表 FROM 表名 LIMIT 初始索引,查询记录数;

查询第一页的10条记录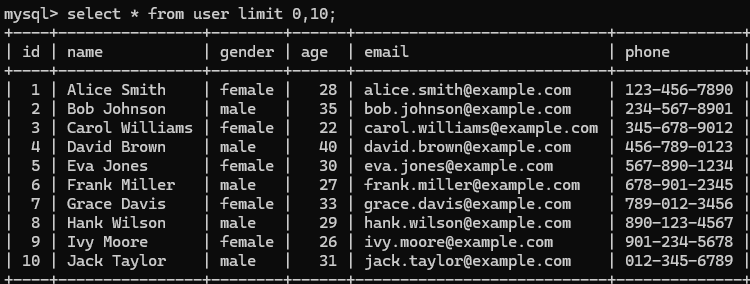
查询第一页的5条记录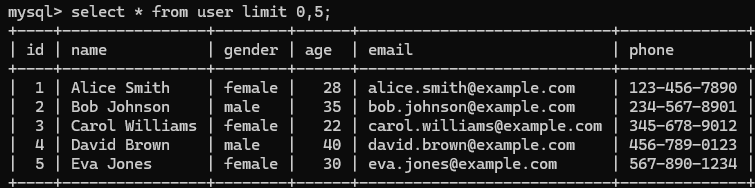
执行循序


DCL-数据控制语言
用来控制数据库的访问权限
约束
约束是作用域表中字段上的规则,限制表中的数据

外键约束:外键是建立两张表的数据之间联系的,保证数据的一致性和完整性

多表查询
- 一对多(多对一):员工和部分的关系,需要建立外键联系
- 一对一:用户与用户详情的关系,多用于单表拆分,在任意一方加入外键,关联另外一方即可
- 多对多:学生和课程的关系,需要建立中间表,中间表至少两个外键,关联两方主键
语法:SELECT 表名1,表明2 WHERE 表名1.xx = 表名2.xx;
分类:
- 内连接:查询两表交集部分的数据

查询每一个顾客的信息及关联的订单
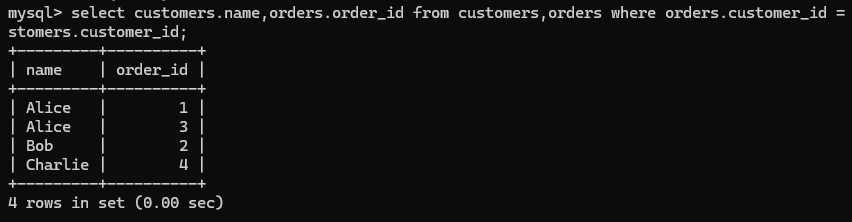
- 外连接:
左外连接:查询左表的所有数据,及两表交集部分
查询顾客的所有信息,及对应订单id信息
右外连接:查询右表的所有数据,及两表交集部分
- 自连接:查询当前表与自身的连接查询
查询员工本身的名字及其直系领导的名字
嵌套查询(子查询)
SQL语句中嵌套SELECT语句
- 标量子查询:查到的数据是一个值
查询入职日期在房东白之后的员工信息
- 列子查询:是一列
- 行子查询:子查询返回的结果是一行
- 表子查询:返回的结果是多行多列
事务
事务是一组操作的集合,是一个不可分割的工作单位,这些操作要么全部成功,要么全部失败
比如,银行转账1000分三个步骤,当这个方法调用时,事务就自动开启了,中间出现任何问题都不会影响事务的自动提交。若李四金额+1000操作前出现了异常,就会导致前两个操作执行,第三个操作没执行,所以可以通过手动设置开启和提交模式
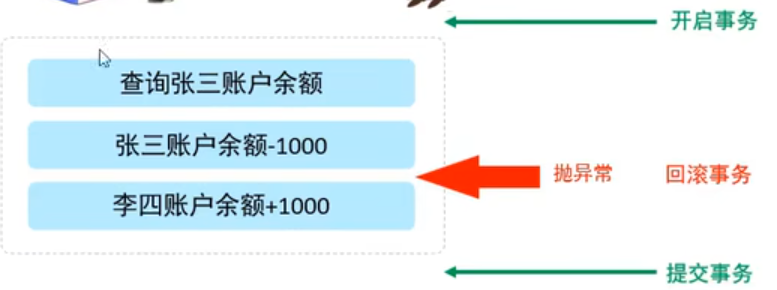
SET AUTOCOMMIT = 0; -- 关闭自动提交
SET AUTOCOMMIT = 1; -- 开启自动提交事务执行逻辑单元。。。。
如果在事务执行过程中发生错误或需要撤销操作,可以使用
ROLLBACK语句回滚事务,撤销所有未提交的更改。COMMIT; --事务手动提交
四大特性 ACID

并发事务问题
- 脏读:一个事务读到另外一个事务还未提交的更新数据。
- 不可重复读:一个事务前后读取同一条记录,两次数据不同
- 幻读:一个事务查询数据时,无该数据,但在插入数据时,又发现这行数据已经存在,出现了幻影
事务隔离级别 :用于解决事务并发问题
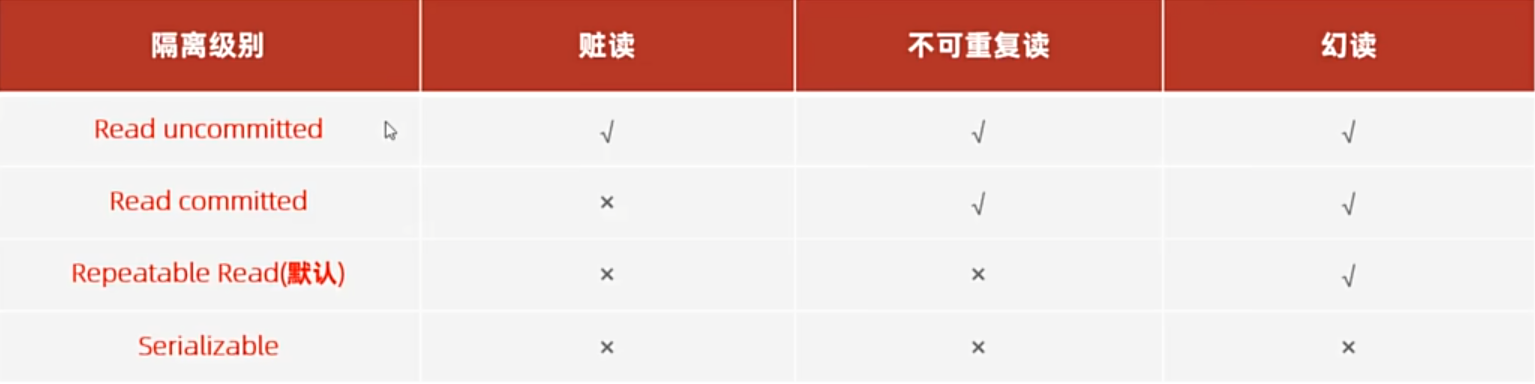 越往下隔离级别越高,同时性能也越差
越往下隔离级别越高,同时性能也越差


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









