






Redis(REmote DIctionary Server)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
Redis为什么快
- Redis 基于内存,内存的访问速度比磁盘快很多;
- Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
- Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
- Redis 通信协议实现简单且解析高效。
为什么用Redis
1、访问速度更快
传统数据库数据保存在磁盘,而 Redis 基于内存,内存的访问速度比磁盘快很多。引入 Redis 之后,我们可以把一些高频访问的数据放到 Redis 中,这样下次就可以直接从内存中读取,速度可以提升几十倍甚至上百倍。
2、高并发
一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
QPS(Query Per Second):服务器每秒可以执行的查询次数;
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
3、功能全面
Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
Redis应用
- 分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。
- 限流:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。 - 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
Redis有序集合底层为什么用跳表
- 平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 O(log n)。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
- 红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
- B+树 vs 跳表:B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并。
过期数据的删除策略
常用的过期数据的删除策略就下面这几种
- 惰性删除:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
- 定期删除:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
- 延迟队列:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
- 定时删除:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
缓存穿透
缓存穿透说简单点就是大量请求的 key 是不合理的,根本不存在于缓存中,也不存在于数据库中 。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
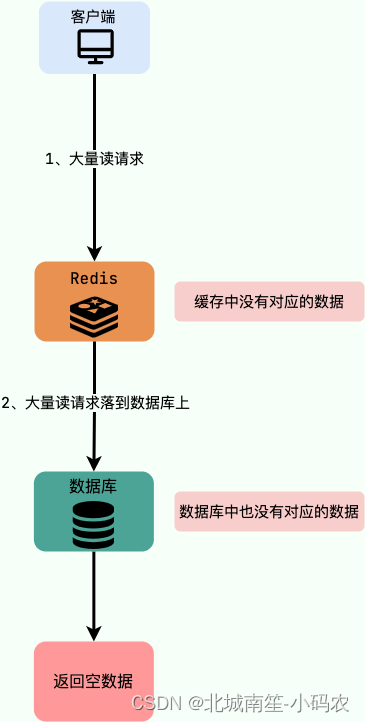
解决办法:
首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
1)缓存无效 key
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间。
2)布隆过滤器
把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
3)接口限流
根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单。
缓存击穿
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
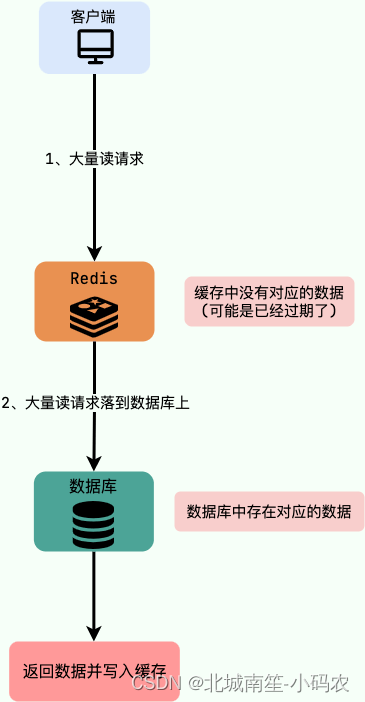
解决办法
- 永不过期(不推荐):设置热点数据永不过期或者过期时间比较长。
- 提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 加锁(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
缓存穿透与缓存击穿区别
缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)
缓存雪崩
缓存雪崩描述的就是这样一个简单的场景:缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
另外,缓存服务宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。
针对大量缓存同时失效的情况:
- 设置随机失效时间(可选):为缓存设置随机的失效时间,例如在固定过期时间的基础上加上一个随机值,这样可以避免大量缓存同时到期,从而减少缓存雪崩的风险。
- 提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 持久缓存策略(看情况):虽然一般不推荐设置缓存永不过期,但对于某些关键性和变化不频繁的数据,可以考虑这种策略。















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









