






一.大数据
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
在维克托•迈尔-舍恩伯格及肯尼斯•库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
大数据的定义
对于“大数据”(Big data)研究机构Gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
大数据特征
容量(Volume):数据的大小决定所考虑的数据的价值和潜在的信息;
种类(Variety):数据类型的多样性;
速度(Velocity):指获得数据的速度;
可变性(Variability):妨碍了处理和有效地管理数据的过程。
真实性(Veracity):数据的质量
复杂性(Complexity):数据量巨大,来源多渠道
价值(value):合理运用大数据,以低成本创造高价值
大数据结构
大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。
大数据应用
洛杉矶警察局和加利福尼亚大学合作利用大数据预测犯罪的发生。
google流感趋势(Google Flu Trends)利用搜索关键词预测禽流感的散布。
统计学家内特.西尔弗(Nate Silver)利用大数据预测2012美国选举结果。
麻省理工学院利用手机定位数据和交通数据建立城市规划。
梅西百货的实时定价机制。根据需求和库存的情况,该公司基于SAS的系统对多达7300万种货品进行实时调价。
医疗行业早就遇到了海量数据和非结构化数据的挑战,而近年来很多国家都在积极推进医疗信息化发展,这使得很多医疗机构有资金来做大数据分析。
大数据意义
现在的社会是一个高速发展的社会,科技发达,信息流通,人们之间的交流越来越密切,生活也越来越方便,大数据就是这个高科技时代的产物。 阿里巴巴创办人马云来台演讲中就提到,未来的时代将不是IT时代,而是DT的时代,DT就是Data Technology数据科技,显示大数据对于阿里巴巴集团来说举足轻重。
有人把数据比喻为蕴藏能量的煤矿。煤炭按照性质有焦煤、无烟煤、肥煤、贫煤等分类,而露天煤矿、深山煤矿的挖掘成本又不一样。与此类似,大数据并不在“大”,而在于“有用”。价值含量、挖掘成本比数量更为重要。对于很多行业而言,如何利用这些大规模数据是赢得竞争的关键。
二.大数据分析的四种典型工具:
(1)Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
HDFS
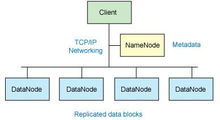
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的(参见图 1),这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
HadoopNameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。注意,这里需要您了解集群架构。
实际的 I/O事务并没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode。
NameNode 在一个称为 FsImage 的文件中存储所有关于文件系统名称空间的信息。这个文件和一个包含所有事务的记录文件(这里是 EditLog)将存储在 NameNode 的本地文件系统上。FsImage 和 EditLog 文件也需要复制副本,以防文件损坏或 NameNode 系统丢失。
NameNode本身不可避免地具有SPOF(Single Point Of Failure)单点失效的风险,主备模式并不能解决这个问题,通过Hadoop Non-stop namenode才能实现100% uptime可用时间。
HadoopDataNode
DataNode 也是一个通常在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。NameNode 依赖来自每个 DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。
(2)SPARK
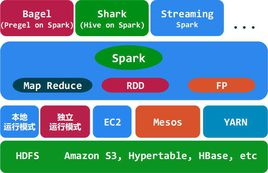
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
(3)Storm
Storm是一种开源软件,一个分布式、容错的实时计算系统。Storm可以非常可靠地处理庞大的数据流,用于处理Hadoop的批量数据。Storm很简单,支持许多种编程语言,使用起来非常有趣。Storm由Twitter开源而来,其他知名的应用企业包括Groupon、淘宝、支付宝、阿里巴巴、乐元素、Admaster等。















 4137
4137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









