







深度解析DeepSeek R1大模型推理流程
首先理解大模型的全生命周期包含了五个阶段:数据获取、数据预处理、模型训练、模型微调和模型推理。
大模型在训练之前首先需要收集海量的多模态数据,这些数据多达数百亿个小文件,存储可能需要几TB、甚至几十TB;这些数据杂乱无章,可能包含重复数据或者广告内容,需要对这些数据进行预处理,使数据格式统一;然后将所有数据喂给大模型,经过海量算力进行模型训练形成基础大模型;为了让这个基础大模型能够应用到特定场景中,需要用特定场景的数据对模型进行二次训练,也就是模型微调;最后用户向训练好的大模型输入prompt,大模型经过一系列运算输出对应的结果,也就是模型推理。
一、模型推理
1.1 自回归大模型推理
自回归大模型采用序列生成范式,当前输出的每个元素都依赖于已生成的前序内容。基于Transformer解码器结构,采用自注意力机制,确保模型只能关注已生成的序列位置。例如GPT系列、LlaMA系列、DeepSeek系列等。自回归大模型推理包括Prefill和Decode两个阶段:
1.1.1 Prefill阶段
根据输入的token生成第一个输出NewToken,缓存KV Cache(Key和Value矩阵)。
Prefill阶段同时处理输入Token的能力通常是计算密集型,计算量随输入长度的增加呈超线性增长。
1.1.2 Decode阶段
从生成第一个Token后,采用自回归一次生成一个Token,更新token序列和KV Cache,直到生成"停止"Token结束。
Decode阶段每批次只能处理一个Token(串行执行),效率很低,使得它受内存的限制(考虑显存带宽瓶颈),且计算量随着批次大小的增加呈次线性增长。
1.2 DeepSeek R1大模型推理流程
主要关注 DeepSeek R1大模型的推理阶段,DeepSeek R1采用稀疏MoE-Transformer架构,结合监督微调和强化学习,逻辑思维和数学推理能力强,支持上下文处理128k Token。DeepSeeK推理的Prefill和Decode两个阶段可以细分为输入预处理、Transformer逐层处理和输出自回归解码三个部分:
1.2.1 输入预处理
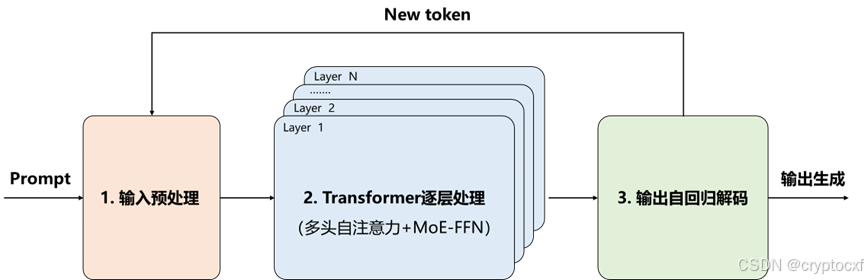
图 1 DeepSeek R1模型推理流程
(1) Prompt:用户输入一个 prompt,例如"请计算 2 + 3 2+3 2+3 等于多少?";
(2) Tokenization:将输入的 prompt分割为模型可识别的 Token序列,例如[“请”,“计算”,“2”,“+”,“3”,“等于”,“多少”,“?”],这个 Token序列长度为 n = 8 n=8 n=8;在首尾添加控制标记(例如<BOS>开始,<EOS>表示结束)
(3) Embedding:embedding是一个可学习的矩阵 W e m b e d ∈ R V × d W_{embed}\in R^{V\times d} Wembed∈RV×d,其中V是词汇表大小(如DeepSeek R1的词元嵌入矩阵大小为129280),d是嵌入维度(如DeepSeek R1版本 d = 4096 d=4096 d=4096)。每个 Token ID i通过 embedding层映射为一个d维向量:
x i = W embed [ i , : ] ∈ R 1 × d x_i=W_{\text{embed}}[i,:]\in R^{1\times d} xi=Wembed[i,:]∈R1×d
得到输入序列的矩阵 X = [ x 1 , x 2 , … , x 8 ] ∈ R n × d X=\left[x_1, x_2,\ldots, x_8\right]\in R^{n\times d} X=[x1,x2,…,x8]∈Rn×d;
1.2.2 Transformer逐层处理
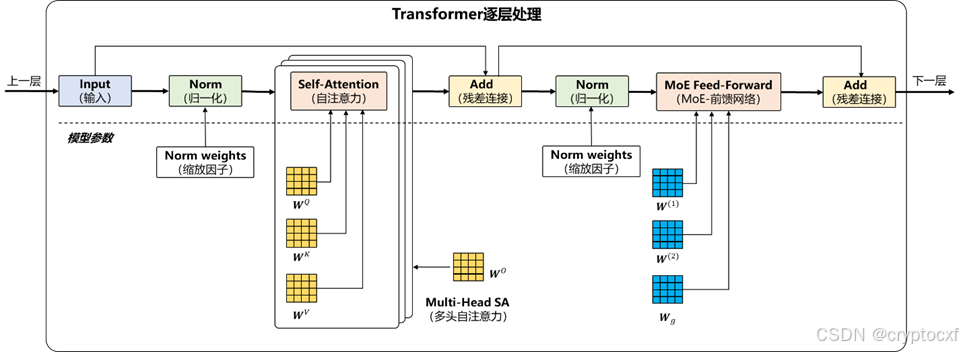
图 2 Transformer逐层处理流程图
假设模型总层数为N=64,每层包含多头自注意力(Multi-Head Self-Attention,MHSA)机制和 MoE前馈网络(MoE-FFN)模块。每层的结构是一样的,但参数独立。我们以第一层计算为例:
(1) Norm:对每个输入向量 x i x_{i} xi 进行归一化处理,计算均方根,并将每个数值除以该均方根值。然后,对每个维度数值乘以一个训练得到的"缩放因子"(norm weights),共d个缩放因子,得到归一化后的输入矩阵
X n × d = [ x 1 x 2 . . . x n ] = [ x 1 , 1 x 1 , 1 . . . x 1 , d x 2 , 1 x 2 , 2 . . . x 2 , d ⋮ ⋮ ⋱ ⋮ x n , 1 x n , 2 . . . x n , d ] X_{n\times d}=\begin{bmatrix}x_{1}\\ x_{2}\\ ...\\ x_{n}\end{bmatrix}=\begin{bmatrix}x_{1,1}&x_{1,1}&...&x_{1,d}\\ x_{2,1}&x_{2,2}&...&x_{2,d}\\ \vdots&\vdots&\ddots&\vdots\\ x_{n,1}&x_{n,2}&...&x_{n,d}\end{bmatrix} Xn×d= x1x2...xn = x1,1x2,1⋮xn,1x1,1x2,2⋮xn,2......⋱...x1,dx2,d⋮xn,d
(2) Self-Attention:自注意力表示一个prompt中的Token序列对自己内部的Token的注意力,目的是建立Token之间的关系,数值越大表示联系越紧密。
- 计算输入矩阵的Query、Key、Value矩阵,用于计算它们之间的注意力权重和上下文表示:
Q = X W Q ∈ R n × d k , K = X W K ∈ R n × d k , V = X W V ∈ R n × d k Q=X W^Q\in R^{n\times d_k}\text{,}K=X W^K\in R^{n\times d_k}\text{,}V=X W^V\in R^{n\times d_k} Q=XWQ∈Rn×dk,K=XWK∈Rn×dk,V=XWV∈Rn×dk
其中 W Q , W K , W V ∈ R d × d k W^{Q},W^{K},W^{V}\in R^{d\times d_{k}} WQ,WK,WV∈Rd×dk 为模型训练学习到的权重矩阵, d k = d / h d_{k}=d/h dk=d/h,h为注意力头。
为什么是缓存K和V的值而不是Q的值?(KV Cache)
回答:因为每次生成新token时,Q是基于当前token重新计算的,而K和V表示历史token的信息,不随新token改变,因此只缓存Key、Value值。
- 计算Query和Key点积,并通过Softmax归一化,得到注意力权重矩阵
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V ∈ R n × d k \text{ Attention}(Q, K, V)=\operatorname{Softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V\in R^{n\times d_k} Attention(Q,K,V)=Softmax(dkQKT)V∈Rn×dk
- Q K T Q K^{T} QKT:表示 Query和 Key的相似度,直观理每个 Token和所有其他的 Token用一个数值建立联系,数值越高表示 Token之间的联系越紧密。
- d k \sqrt{d_k} dk:缩放因子,防止点积值过大导致梯度不稳定;
- Softmax:将相似度转换为概率分布。
(3) Multi-Head Self-Attention:高水平的大模型通过多头注意力机制的多个视角(注意力头)捕捉不同的上下文信息。如有的注意头重视逻辑关联,有的重视语法关联等。DeepSeek R1使用 128个注意力头。
- 假如有 h注意力头,每个头独立计算注意力
head i = Attention ( Q i , K i , V i ) ∈ R n × d k \text{ head}_{i}=\text{ Attention}\left(Q_{i}, K_{i}, V_{i}\right)\in R^{n\times d_{k}} headi= Attention(Qi,Ki,Vi)∈Rn×dk
- 将所有头的输出拼接,并通过线性变换合并:
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , … , head 128 ) W O ∈ R n × d \text{ MultiHead}(Q, K, V)=\text{ Concat}\left(\text{ head}_1,\text{ head}_2,\ldots,\text{ head}_{128}\right) W^O\in R^{n\times d} MultiHead(Q,K,V)= Concat( head1, head2,…, head128)WO∈Rn×d
其中 W 0 ∈ R h ⋅ d k × d W^0\in R^{h\cdot d_{k}\times d} W0∈Rh⋅dk×d 是帮助 KQV矩阵进行线性变换,映射回原始的权重矩阵。
(4) Add:也称"残差连接",即将输入矩阵,与多头注意力的输出矩阵相加。在训练神经网络过程中,为了知道每个参数下一步向什么方向、改变多少,需要计算"梯度"。残差连接目的是避免了梯度在传播过程中的消失或爆炸,加强了训练的稳定性。
x i ′ = x i + MultiHead i ( Q , K , V ) x_i^{\prime}=x_i+\text{ MultiHead}_i(Q, K, V) xi′=xi+ MultiHeadi(Q,K,V)
(5) Norm:与之前 Norm一样操作,对残差连接的结果 x i ′ x_i^{\prime} xi′ 进行归一化处理
(6) MoE Feed-Forward:混合专家模型-前馈网络(MoE-FFN)是一种稀疏激活的前馈网络,共E个专家组成。
- 专家计算:每个专家 E j E_j Ej 是一个独立的前馈神经网络(FFN),负责处理特定的输入模式。对于选中的专家 E j E_j Ej,计算 E j ( x i ′ ) E_j\left(x_i^{\prime}\right) Ej(xi′)
E j ( x i ′ ) = G e L U ( x i ′ W j ( 1 ) ) W j ( 2 ) , j = 1 , 2 , … , E E_j\left(x_i^{\prime}\right)= G e L U\left(x_i^{\prime} W_j^{(1)}\right) W_j^{(2)}, j=1,2,\ldots, E Ej(xi′)=GeLU(xi′Wj(1))Wj(2),j=1,2,…,E
其中, W j ( 1 ) ∈ R d × d f , W j ( 2 ) ∈ R d f × d W_j^{(1)}\in R^{d\times d_f}, W_j^{(2)}\in R^{d_f\times d} Wj(1)∈Rd×df,Wj(2)∈Rdf×d 是专家 E j E_j Ej 的权重矩阵, d f d_f df 是前馈网络隐藏层维度(DeepSeek V3中的 d f = 18432 d_f=18432 df=18432)。
- 门控网络:选择少量专家来处理每个输入 Token(如 DeepSeek R1 671B中处理 Token时,仅有 37B参数激活)。对每个 Token的隐藏状态 x i ′ x_{i}^{\prime} xi′,计算专家权重
g j = Softmax ( x i ′ ⋅ W g + ϵ ) ∈ R E g_j=\operatorname{Softmax}\left(x_i^{\prime}\cdot W_g+\epsilon\right)\in R^E gj=Softmax(xi′⋅Wg+ϵ)∈RE
其中, W g ∈ R d × E W_g\in R^{d\times E} Wg∈Rd×E 是门控网络的权重矩阵, ϵ \epsilon ϵ 是训练时添加的噪声(推理时关闭)。然后,从 g j g_j gj 中选择权重最高的 k个专家(Top-k),如 k = 2 k=2 k=2,其余专家权重置零。
- 加权聚合:对选中的专家输出进行加权求和
y i = ∑ j = 1 E g j ( x i ′ ) ⋅ E j ( x i ′ ) y_i=\sum_{j=1}^E g_j\left(x_i^{\prime}\right)\cdot E_j\left(x_i^{\prime}\right) yi=j=1∑Egj(xi′)⋅Ej(xi′)
(7) Add:与前 Add类似操作,进行残差连接与归一化,即 x i ′ ′ = Norm ( x i ′ + y i ) x_i^{\prime\prime}=\operatorname{Norm}\left(x_i^{\prime}+y_i\right) xi′′=Norm(xi′+yi)。
至此,第一层计算结束,将输出结果输入下一层,直到经过总层数 N=64处理后,输出最后一个 Token"?"的最终隐藏状态 x n ∈ R 1 × d x_n\in R^{1\times d} xn∈R1×d,用于预测下一个 Token。
1.2.3 输出自回归解码
自回归解码指模型逐个生成输出 Token,每个新生成的 Token都依赖于之前生成的 Token。
(1) LM Head:即线性投影,将最后一个 Token的隐藏状态 x n x_n xn 映射到词汇表空间
logits = x n ⋅ W logits , W logist ∈ R d × V \text{ logits}=x_{n}\cdot W_{\text{logits}}, W_{\text{logist}}\in R^{d\times V} logits=xn⋅Wlogits,Wlogist∈Rd×V
其中, W logits W_{\text{logits}} Wlogits 为 LM Head的权重矩阵,V为上面提到的词汇表大小(如 129280)。
然后,通过Softmax生成概率分布
p = Softmax ( logits ) ∈ R 1 × V p=\text{ Softmax}(\text{ logits})\in R^{1\times V} p= Softmax( logits)∈R1×V
(2) Sampling:DeepSeek R1默认使用 Top-p采样,即从累积概率超过 p的 Token中随机采样。其他采样方法包括:贪心搜索采样(根据词汇表概率分布 p,选择概率最高的Token)、Top-k采样(根据p选择概率最高的k个Token重新归一化概率,再从中随机采样)。
最后,将输出的新Token组合成新Token序列,将其作为输入重复上述所有操作,并更新KV Cache,直到预测到(序列结束符)为止。
例如,原Token序列为[“请”,“计算”,“2”,“+”,“3”,“等于”,“多少”,“?”],预测下一个Token为"5",则更新Token序列为[“请”,“计算”,“2”,“+”,“3”,“等少”,“?”],于",“多少”,“?”,“5”],并继续生成,直至预测下一个Token为,则生成结束(即达到的概率阈值,判定生成结束)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









