






批量找URL厂商简单信息:简易版 由于本平台限制原因,某些文章发送不出去.那就发一个简易版
批量探测域名信息必备.
实现代码:
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor #自行添加代理池
import time
def get_info(domain):
url="https://ip.tool.chinaz.com/ipbatch"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
data={
"ips":domain,
"submore":"查询"
}
response=requests.post(url=url,data=data,headers=header)
response.encoding="utf-8"
content=response.text
return content
def parse_data(content):
parse=etree.HTML(content)
domain=parse.xpath('//*[@id="ipList"]/tr/td[1]/text()')[0].strip()
IP=parse.xpath('//*[@id="ipList"]/tr/td[2]/a/text()')[0].strip()
number=parse.xpath('//*[@id="ipList"]/tr/td[3]/text()')[0].strip()
IP_Address=parse.xpath('//*[@id="ipList"]/tr/td[4]/text()')[0].strip()
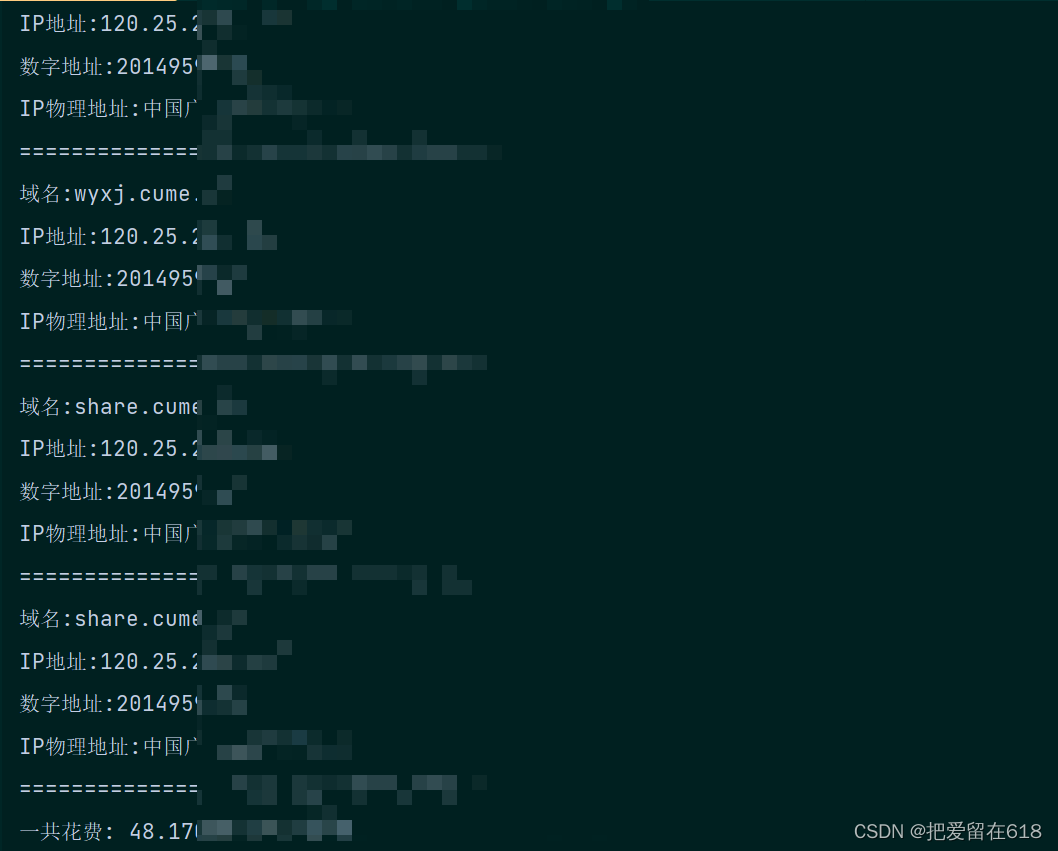
print(f'域名:{domain}')
print(f'IP地址:{IP}')
print(f'数字地址:{number}')
print(f'IP物理地址:{IP_Address}')
print("====================================")
return [domain,IP,number,IP_Address]
def thread():
date = time.time()
f = open("需要跑的URL字典", "r", encoding="utf-8") #需要修改的地方
file = f.readlines()
with open("数据.csv","w",encoding="utf-8") as fp:
fp.write("域名,IP,数字地址,IP物理地址"+"\n")
for domain in file:
content = get_info(domain)
result=parse_data(content)
data=','.join(result)
fp.write(data+"\n")
print("一共花费:", time.time() - date)
if __name__ == '__main__':
thread()运行结果:
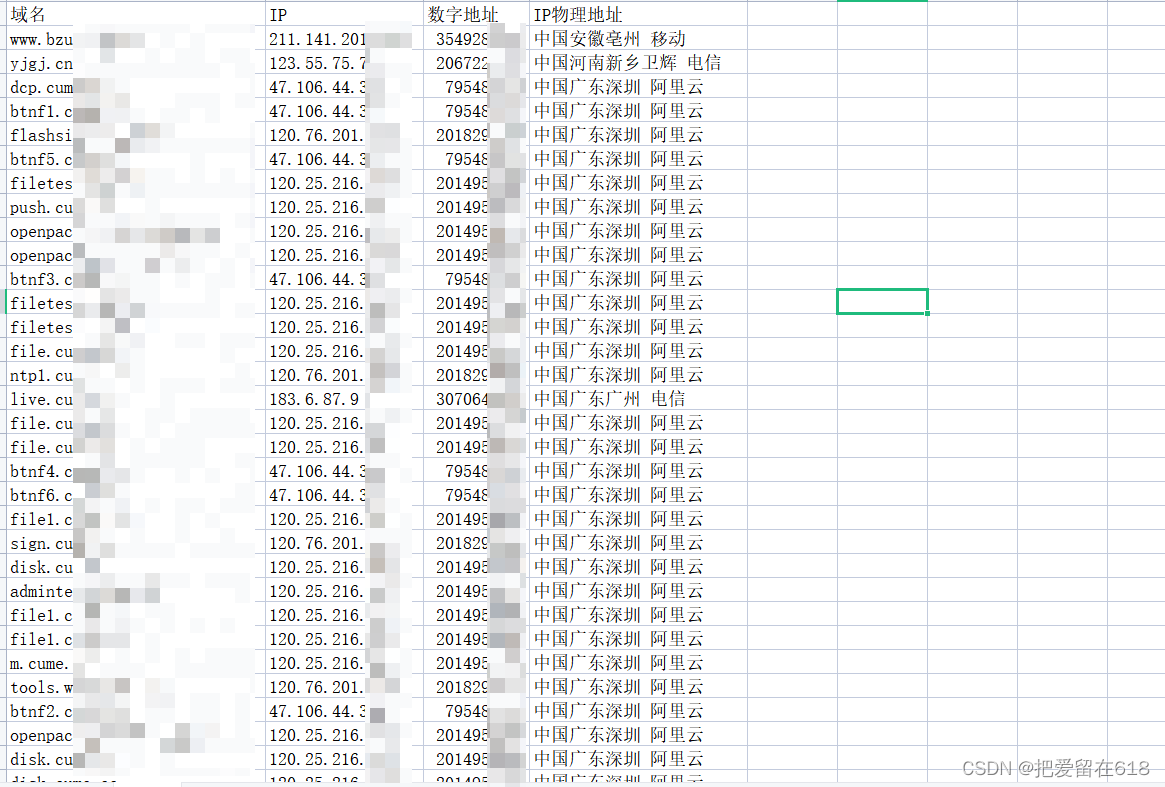
运行完后当前目录下会产生一个 数据.csv文件格式内容,这样看更直观一些 图片如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









