







 该博客介绍了如何使用Python的requests和re库从豆瓣电影Top250排行榜中抓取电影名称、年份、评分和评价人数,并将这些信息保存到CSV文件中。通过示例代码展示了网页源代码的请求、正则表达式解析以及数据写入CSV文件的过程。
该博客介绍了如何使用Python的requests和re库从豆瓣电影Top250排行榜中抓取电影名称、年份、评分和评价人数,并将这些信息保存到CSV文件中。通过示例代码展示了网页源代码的请求、正则表达式解析以及数据写入CSV文件的过程。
直接上手刃豆瓣Top250电影排行榜
# 拿到页面源代码 request
# 通过re来提取想要的有效信息 re
import requests
import re
import csv
url = "https://movie.douban.com/top250"
'''
输入此网址可以爬取前25电影:https://movie.douban.com/top250
输入此网址可以爬取26-50电影:https://movie.douban.com/top250?start=25&filter=
输入此网址可以爬取51-75电影: https://movie.douban.com/top250?start=50&filter=
想获取更多自己试试
'''
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?)'
r' .*?<span class="rating_num" property="v:average">(?P<evaluate>.*?)'
r'</span>.*?<span>(?P<numbers>.*?)人评价</span>', re.S)
# 开始匹配
result = obj.finditer(page_content)
f = open("data.csv", mode="w", encoding='utf-8') # 创建要保存的csv文件
csvwriter = csv.writer(f)
for it in result:
# print(it.group("name"))
# print(it.group("year").strip())
# print(it.group("evaluate"))
# print(it.group("numbers"))
dic = it.groupdict()
dic['year'] = dic['year'].strip() # 因为year采取的时候有需要的空格所以需要进行strip处理
csvwriter.writerow(dic.values())
f.close() # 养成好习惯,使用完文件之后要关闭文件
print("over!")
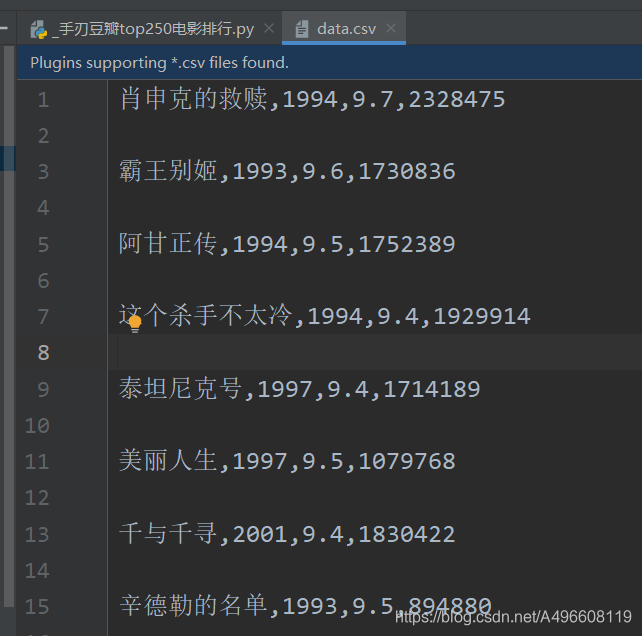
csv的实验结果如下图所示

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









