







1. Container 容器
1.1 容器之间的实现关系与分类
- 容器之间的关系并非继承而是复合,例如,set是内部维护一个rb_tree来实现的

1.2 list
](https://img-blog.csdnimg.cn/1dea103ca14d42099c666de8fd4cc007.png)
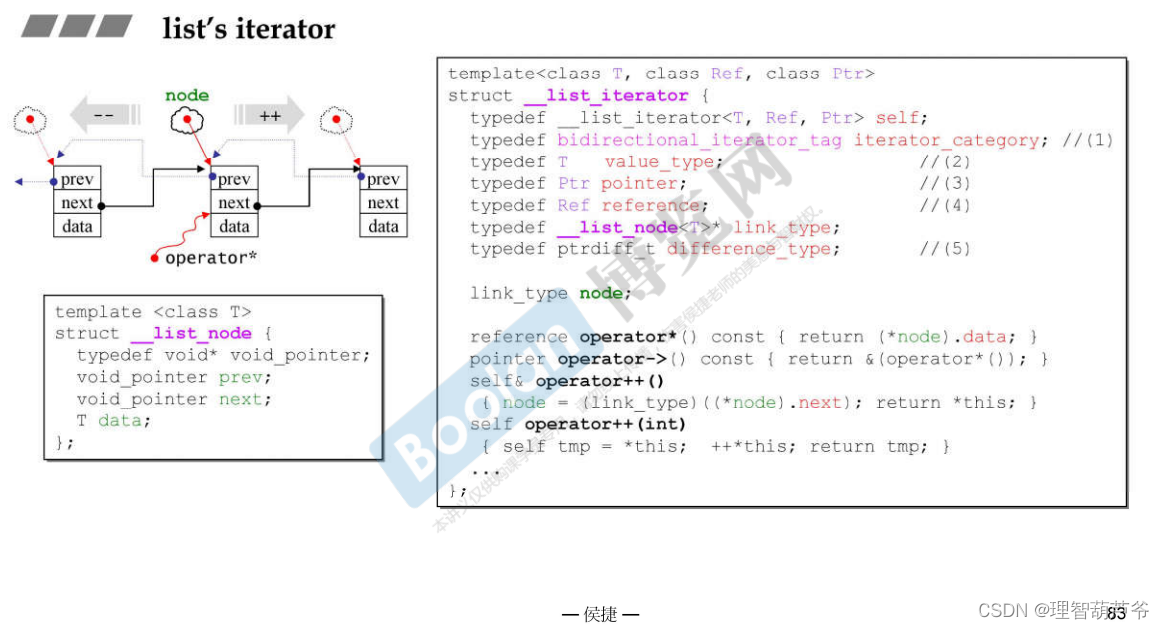
- 如图所示,在GC2.9中list是一个环状链表,其中有一个成员变量,是指向
list_node的指针,所以sizeof(list)=一个指针的大小; list_node中包含两个指针和一个值,指针指向前后节点,所以list申请内存的时候每个节点要耗用两个指针+一个值的内存list中的迭代器__list_iterator, 里面会有大量的操作符重载,要模拟指针,指向node,支持各类操作符。
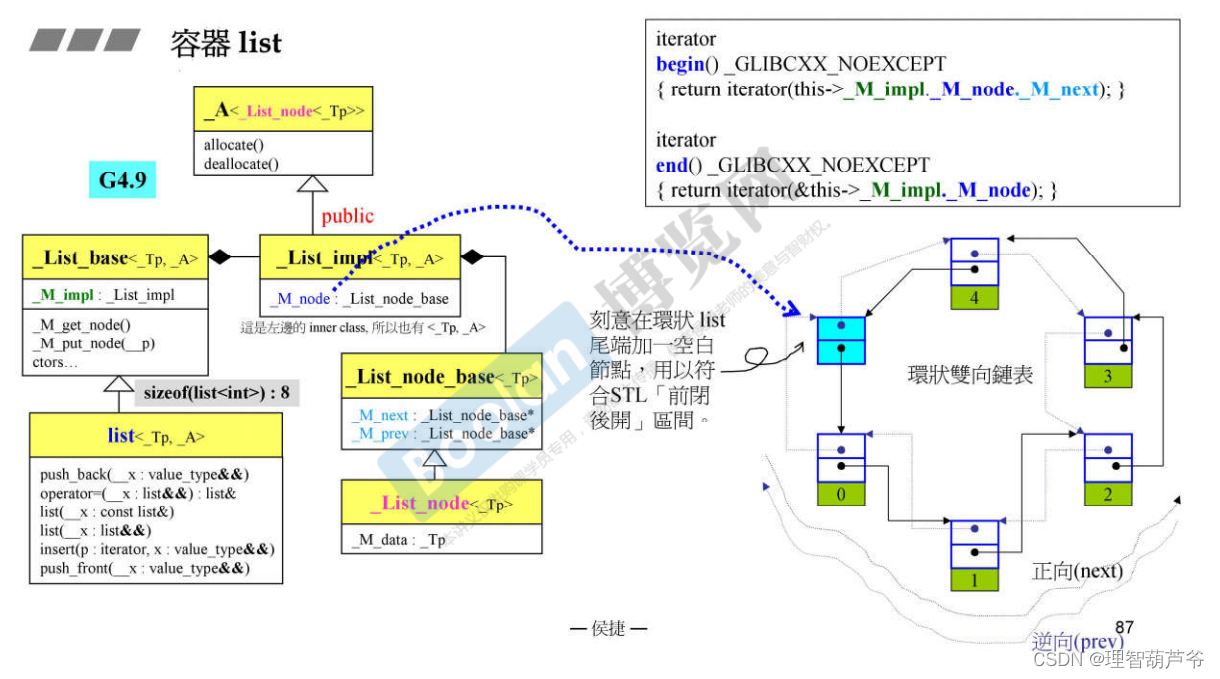
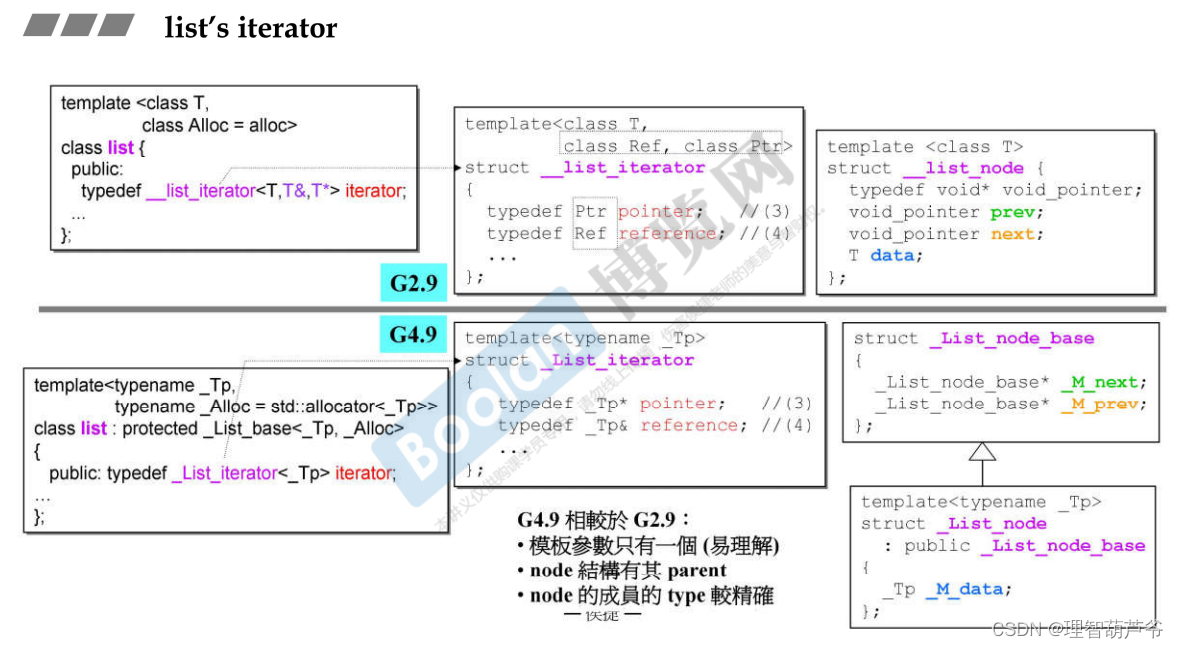
- 如下图所示,在GC4.9中改善了list的实现代码,减少了
_List_iterator的模板参数,以及更改了list_node中前后指针的写法。GC2.9中是一个指针指向头节点,所以sizeof(list)的大小是一个指针的大小,而4.9中,list中有两个指针,分别是_M_next和_M_pre,sizeof(list)是两个指针的大小,不再是一个指针。
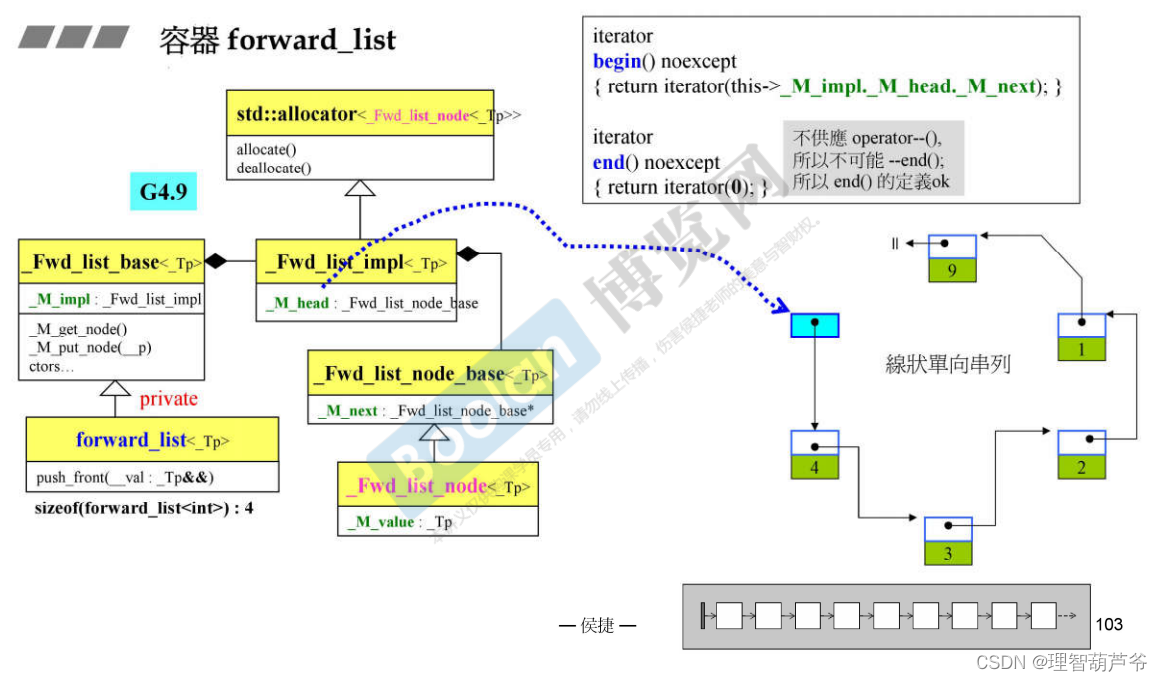
- 单向链表forwward_list实现与list大同小异
1.3 vector
- vector是两倍增长的,GC2.9中vector维护三个指针,start指向开头,finish指向存储的最后一个数据的后一个位置,end_of_storage指向最多存储的位置的下一位。所以sizeof(vector)是三个指针的大小。

- 当vector已满时,push_back操作会使vector两倍增长,push_back调用insert_aux,insert_aux判断vector是否已经没有可用空间,如果没有则开辟一块两倍大小的内存,将vector的原来的数据拷贝到新的内存中,并将要插入的数据放到内存中,然后拷贝安插点后面到finish的内容(最后这一步是insert()函数会用到,push_back不会指向,因为finish和安插点重合)


- vector的iterator在2.9版中是指针类型,在4.9版中是类,所以在2.9版中走的是iterator_traits的指针偏特化的版本,在4.9版本中,走的是泛化版本,本质是一样的。
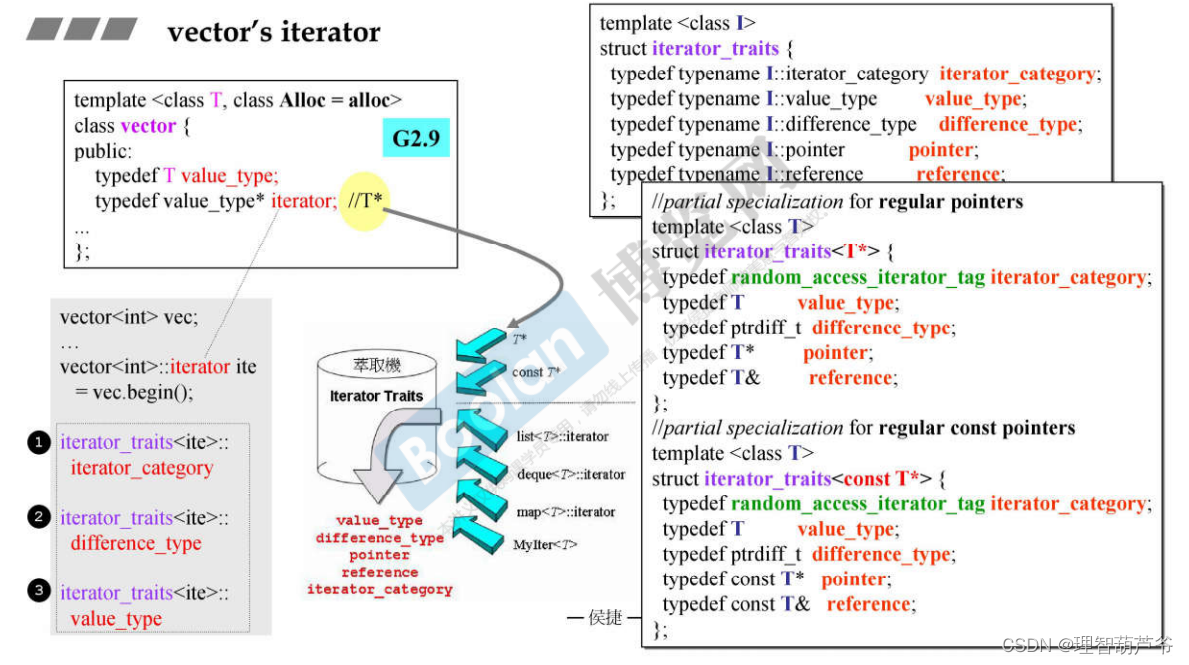

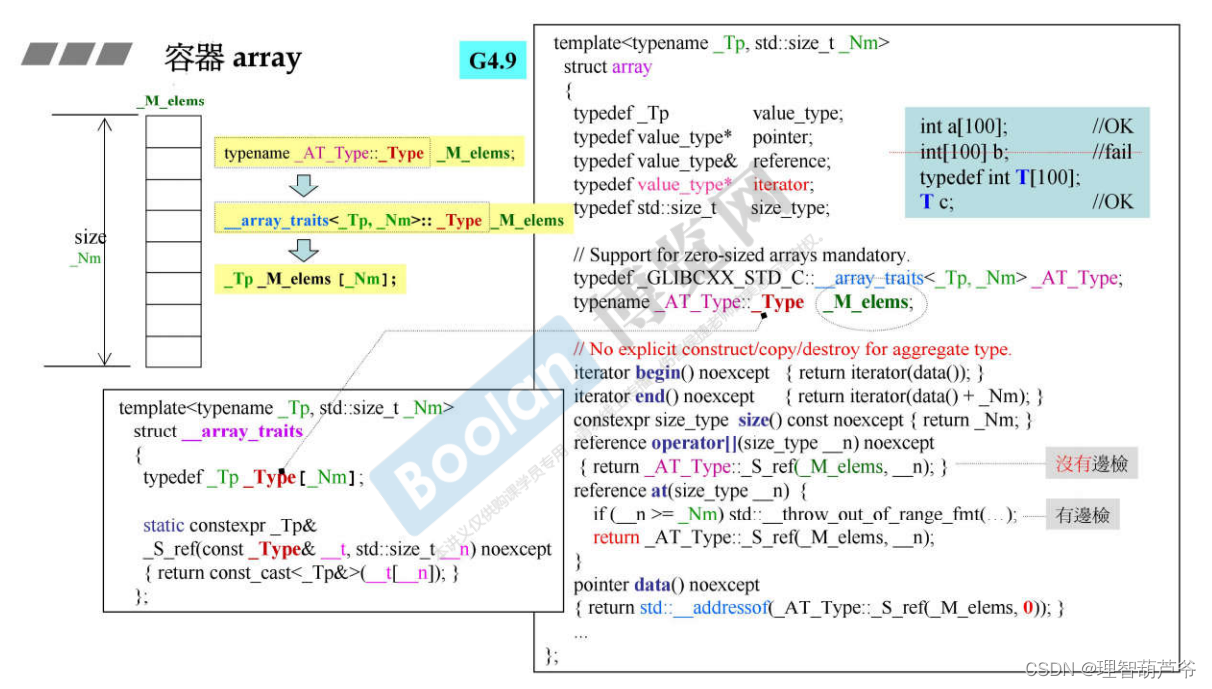
1.4 array
- array允许用户定义一个size为0的数组,当指定的_Nm为0使,返回的valu_type是size为1的数组类型;array没有构造器和析构器。

1.5 deque、queue以及stack
1.5.1 deque
-
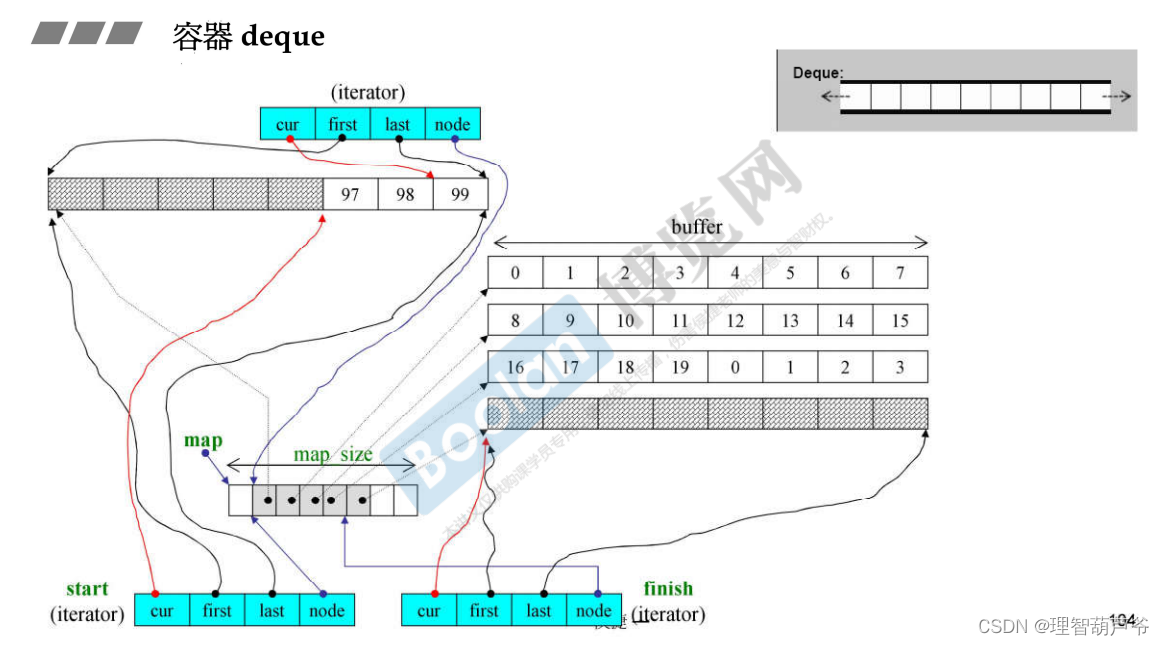
deque逻辑上是连续空间,但实际上是分段连续的,而非完全连续。与vector 相似,deque也采用dynamic array来管理元素,提供随机访问,并有着和 vector 几乎一模一样的接口。不同的是 deque 的 dynamic array 头尾都开放,因此能在头尾两端进行快速安插和删除。
-
deque是由一段一段的定量连续空间构成,一旦有必要在deque的前段或尾端增加新空间,便配置一段定量连续空间,然后串接在整个deque的头端或者尾端。因此,deque最大的任务就是在这些分段的定量连续空间上,维护其整体连续的假象,并提供随机存取的借口,避开了“重新配置,复制,释放”的轮回,代价则是复杂的迭代器架构。
-
deque采用一块所谓的map(不是STL的map容器,反而更像是vector)作为主控,这里所谓的map是一小块连续空间,其中每个元素(此处称为一个节点,node)都是指针,指向一段(较大的)连续空间,称为缓冲区。缓冲区才是deque的储存空间主体,SGI STL允许我们指定缓冲区大小,默认值0表示将使用512bytes缓冲区。
-
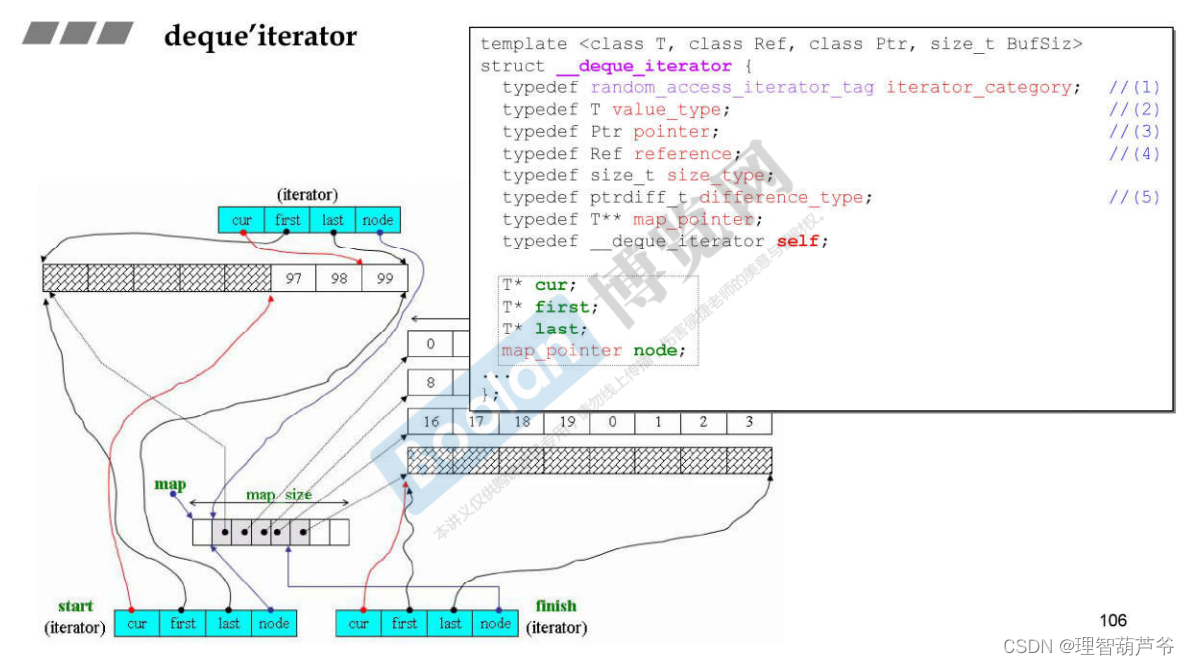
start 指向头的迭代器(M_start),finish 指向尾部的下一个位置的迭代器(_M_finish),迭代器类里有四个成员变量
- cur 指向当前元素
- first 指向当前buffer内的第一个元素
- last 指向当前buffer的最后一个元素
- node 指向当前buffer的指针
-
deque的insert函数:

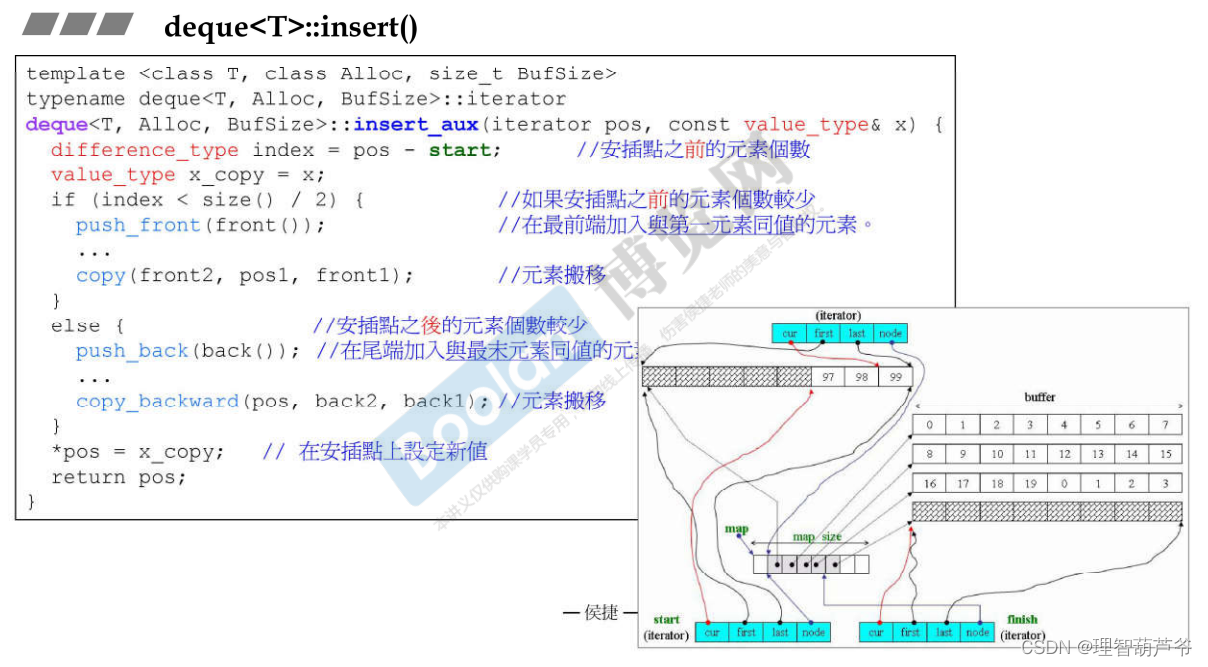
- 如果安插点是start位置,则直接push_front
- 如果安插点是finish位置,则直接push_back
- 如果以上两个条件都不满足,说明不是特殊位置,则要判断pos是考前的位置还是靠后的位置
- pos < size() / 2,位置靠前,让前面的元素前移再插入到对应位置
- pos > size() / 2,位置靠后,让后面的元素后移再插入到对应位置
-
deque如何模拟连续空间?
-
重载operator[],operator+=,operator-=,operator++,operator++(int),operator–,operator–(int)
-
reference operator[](size_type _n) { return *(this + _n); //这里的+是重载后的 } -
reference front() { return *start; //这里的+是重载后的 } -
reference back() { iterator tmp = finsh; //注意,finish指向的是下一个可以存放数据的点,所以要先-- --tmp; return *tmp; //这里的+是重载后的 } -
size_type size()const { return finsh - start;//重载后的- } -
difference_type operator-(const self& x)const { return difference_type(buffer_size()) * (node - x.node - 1) + (cur - first) + (x.last - x.cur); //算start和finish之间的buffer个数再乘长度,然后加上start和finish中占用的存储; } -
reference operator--() { //判断当前是否已到当前buffer的first,如果到了就先将node-1,移动到上一个buffer; if(cur == first) { set_node(node-1); } --cur; return *this } -
reference operator++() { ++cur; 2.判断是否已到当前buffer的last,如果到了就将node+1,移动到下一个buffer; if(cur == last) { set_node(node + 1); cur = first; } return *this; } -
reference operator+=(difference_type n) { //1.判断+n之后是否还在本buffer中,如果在则直接加 difference_type offset = n + (cur - first); if(offset >= 0 && offset < difference_type(buffer_size())) { cur += n; }esle { //2.如果+n之后不在本buffer,先找到对应的缓存区,然后移动剩余的位置 difference_type node_offset = offset > 0 ? offset / difference_type(buffer_size()) : -difference_type((-offset-1)/buffer_size()); //切换至正确的缓冲区 set_node(node + node_offset); cur = first + (offset - node_offset * difference_type(buffer_size())); } return *this; } -
reference operator-=(difference_type n) { return *this += -n; }
-
1.5.2 queue
-
queue可以由deque构造而来,queue先入先出,不允许遍历,没有迭代器

-
queue也可以由deque、list作为底层来实现,不可以由vector、set、map作为底层实现
1.5.3 stack
-
stack可以由deque构造而来,stack先入后出,不允许遍历,没有迭代器

-
stack也可以由deque、list、vector作为底层来实现,但不可以由set、map作为底层实现
1.6 RB_Tree
-
红黑树是一种平衡二叉查找树的变体,它的左右子树高差有可能大于 1,所以红黑树不是严格意义上的平衡二叉树(AVL),但 对之进行平衡的代价较低, 其平均统计性能要强于 AVL 。
-
红黑树的遍历规则是中序遍历,由于红黑数有排序规则,所以不应该使用itreator来改变元素值(编程上没有禁止这种操作,因为要为map和set提供底层支持,map允许改变data,key不能被改变,按key排序)
-
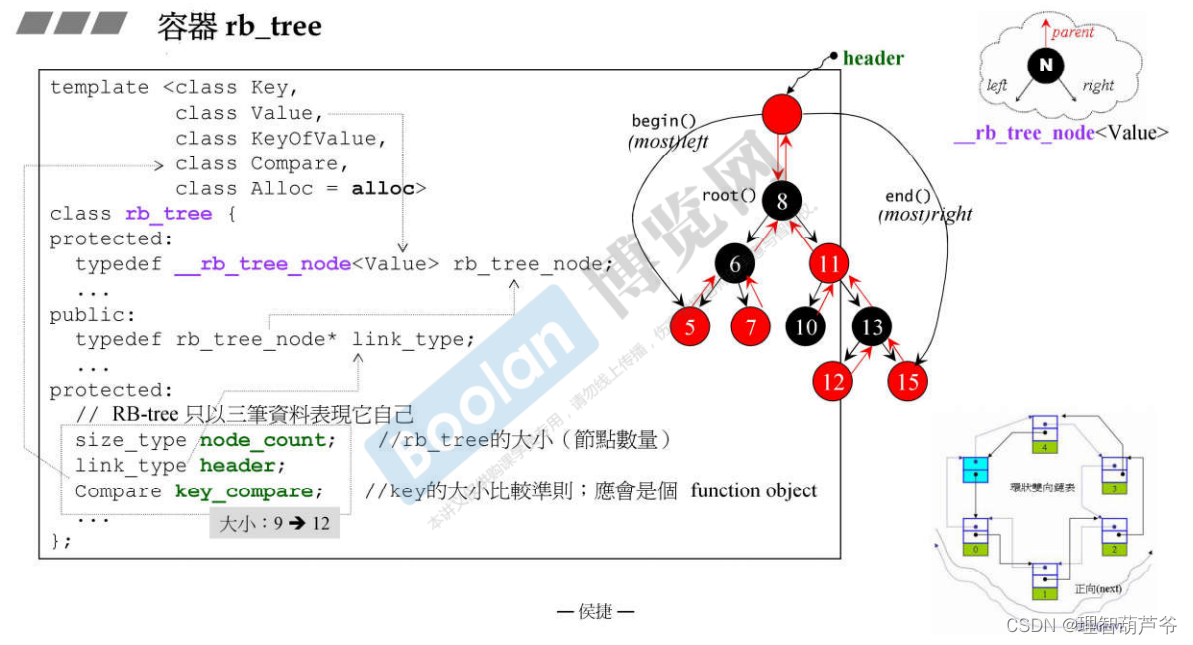
红黑树需要五个模板参数,其中key+data=Value。模板类里有三个元素:node_count、header、key_compare。
-
红黑树里有一个虚header节点,其父节点指向根节点,左子节点指向最小节点,右子节点指向最大节点。
-
int main() { _Rb_tree<int, int, _Identity<int>, less<int>> itree; itree._M_insert_unique(1); itree._M_insert_unique(2); itree._M_insert_unique(3); itree._M_insert_unique(4); itree._M_insert_unique(2); itree._M_insert_unique(6); cout << itree.size() << endl; cout << itree.count(2) << endl; itree._M_insert_equal(2); cout << itree.size() << endl; cout << itree.count(2) << endl; }输出:
5 1 6 2
1.7 set、multiset
- set/multiset以rb_tree作为底层结构来实现,因此有元素自动排序的特性,排序的依据是key,而set/multiset的value和key合一,即:value就是key
- **无法使用set/multiset的iterator来改变元素值。**从set中取 iterator时,取到的是const_itreator,从而禁止了使用者通过itreator改变元素值
- set调用insert_unique(),multiset调用insert_equal(),所以set的不重复,multiset可重复
- set的所有操作都是转调用
ret_type t进行操作,也就是rb_tree进行操作。

1.8 map、multimap
- map/multimap以rb_tree作为底层结构来实现,因此有元素自动排序的特性,排序的依据是key,
- 无法使用map/multimap的iterator来改变元素的key值,但可以改变data的值。
- map调用insert_unique(),multimap调用insert_equal(),所以map的不重复,multimap可重复
- 从下图中可以看出,map使用key和data生成pair时(pair作为value),将const key作为first的值,从而禁止了使用者改变key。另外,rb_tree中所需要的KeyOfValue的类型使用select1st获取pair的first类型。(与identity一样,select1st也并不是标准库提供的,所以当不提供时,需要手动实现)
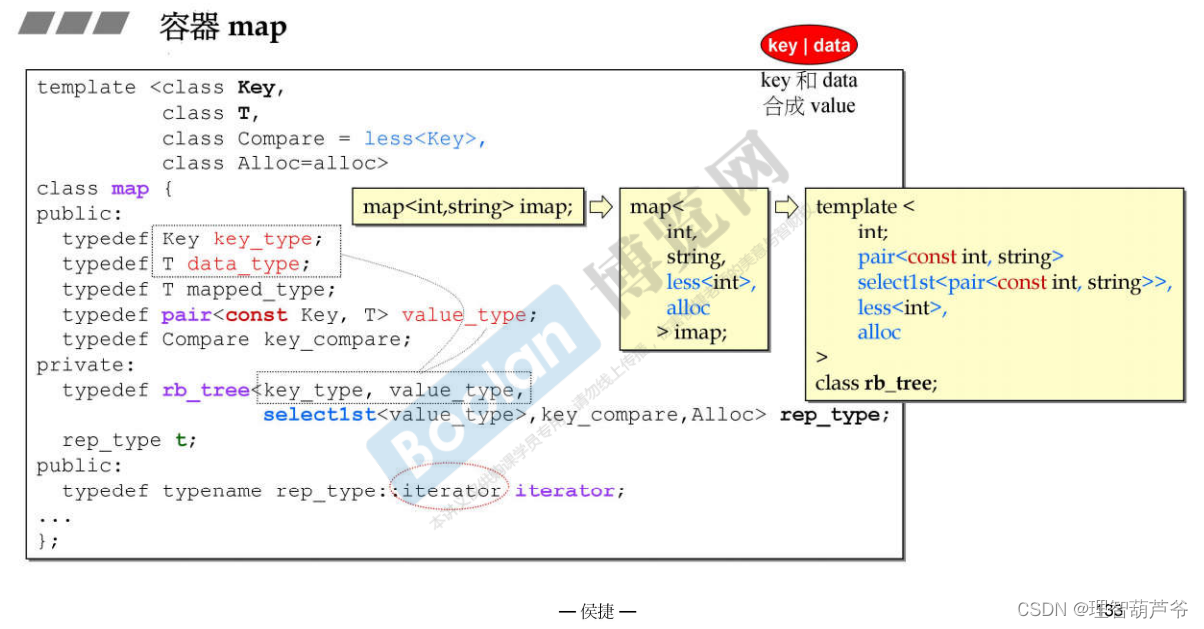
- map容器独有的operator[],检查是否存在key,不存在的话创建一个值为默认参数的key-data对并返回data,存在就返回data。
1.9 hashtable深度探索
1.9.1 原理
-
编号为1~N的M(M < N)个元素,放到大小为M的容器中,编号id(hashcode)%M为该元素应放的位置。当两个元素计算出来的位置相同时,称为hash碰撞。
-
GC处理hash碰撞的方式:拉链法
- 拉链法
- 当发生碰撞时,在碰撞位置放置一个链表,碰撞的元素存储到链表中
- 当元素个数大于散列表篮子(bucket)个数时,散列表进行二倍扩容,然后所有元素重新计算放置的篮子位置
- 根据经验值,篮子初始值可以为53,扩容到53倍数附近的质数

- 拉链法
-
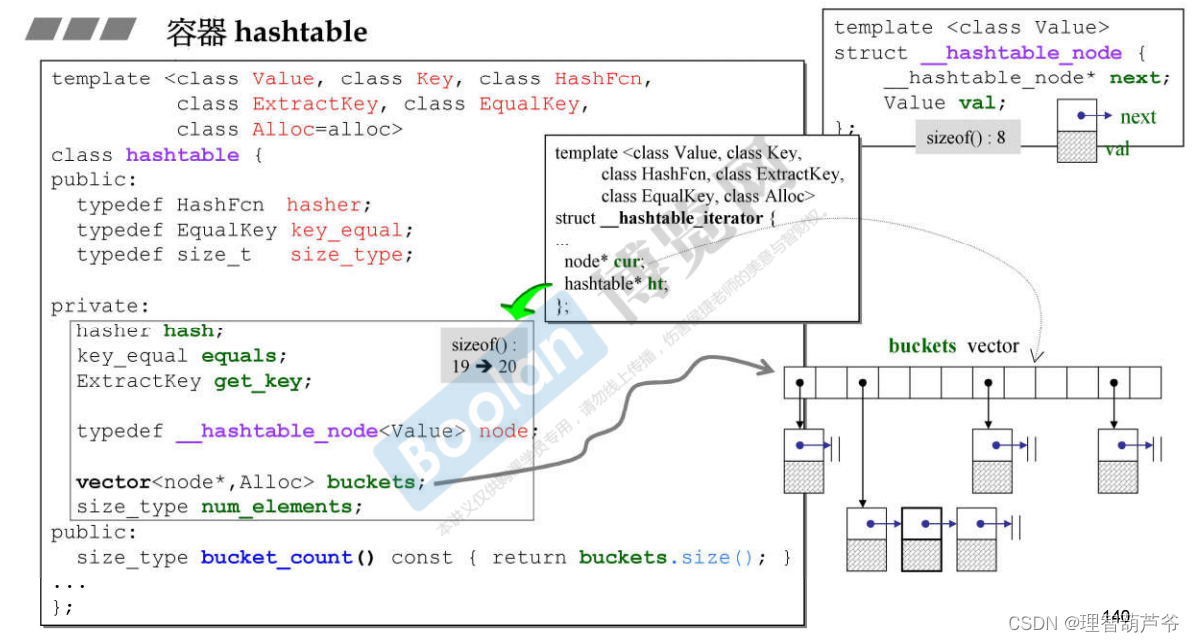
hashtable有六个模板参数:Value,Key,HashFcn,ExtractKey(KeyOfValue),EqualKey,Alloc;五个成员变量:hasher,equals,get_key,buckets,num_elements
-
从上图可以看出,hashtable的迭代器有两个指针:cur和ht,其中ht指向篮子,cur指向篮子中的节点。即:hashtable的迭代器必须有能力在一个篮子的最后一个元素跳到下一个元素(类似deque)
-
采用hash来生成hashcode,对于数值直接返回该值作为hashcode,对于字符串采用__stl_hash_string(根据每个字符计算出一个够乱的值)生成hashcode


-
hashtable的操作:hashtable 的插入 跟 RB-tree 的插入类似,有两种插入方法 insert_unique 和 insert_equal ,意思也是一样的,insert_unique 不允许有重复值,而 insert_equal 允许有重复值。
-
现在来看一下 insert_unique 函数,需要注意的是插入时,新节点直接插入到链表的头节点,代码如下:
pair<iterator, bool> insert_unique(const value_type& obj) { resize(num_elements + 1);//resize()函数判断需不需要进行扩容操作 return insert_unique_noresize(obj); } pair<iterator, bool> insert_unique_noresize(const value_type& obj) { const size_type n = bkt_num(obj); //决定 obj 应位于 buckets 的那一个链表中 node* first = buckets[n]; //遍历当前链表,如果发现有相同的键值,就不插入,立刻返回 for( node* cur = first; cur; cur = cur->next) { if( equals(get_key(cur->val), get_key(obj)) ) return pair<iterator, bool>(iterator(cur, this), false); } //离开以上循环(或根本未进入循环)时,first指向 bucket 所指链表的头节点 node* tmp = new_node(obj); //产生新节点 tmp->next = first; buckets[n] = tmp; //令新节点为链表的第一个节点 ++num_elements; //节点个数累加1 return pair<iterator, bool>( iterator(tmp,this), true); } -
允许重复插入的 insert_equal,需要注意的是插入时,重复节点插入到相同节点的后面,新节点还是插入到链表的头节点,代码如下:
iterator insert_equal(const value_type& obj) { resize( num_elements + 1 ); //判断是否 需要重建表格,如需要就扩充 return insert_equal_noresize(obj); } iterator insert_equalnoresize(const value_type& obj) { const size_type n = bkt_num(obj); //决定 obj 应位于 buckets 的那一个链表中 node* first = buckets[n]; //遍历当前链表,如果发现有相同的键值,就马上插入,立刻返回 for( node* cur = first; cur; cur = cur->next) { if( equals(get_key(cur->val), get_key(obj)) ) { node* tmp = new_node(obj); tmp->next = cur->next; //新节点插入当前节点位置之后 cur->next = tmp; ++num_elements; return iterator(tmp, this); } } //运行到这里,表示没有发现重复的键值 node* tmp = new_node(obj); //产生新节点 tmp->next = first; buckets[n] = tmp; //令新节点为链表的第一个节点 ++num_elements; //节点个数累加1 return iterator(tmp, this); }
-
1.9.2 一个万用的Hash Function
-
为一个类构建一个Hash Function。有三个办法,一是设计为类的成员函数,需要重载operator();二是设计成普通函数。第二种方法中,<>中第二个模板参数是函数类型,创建时还要将真正的函数地址放进来。第三个是写一个hash的特化版本
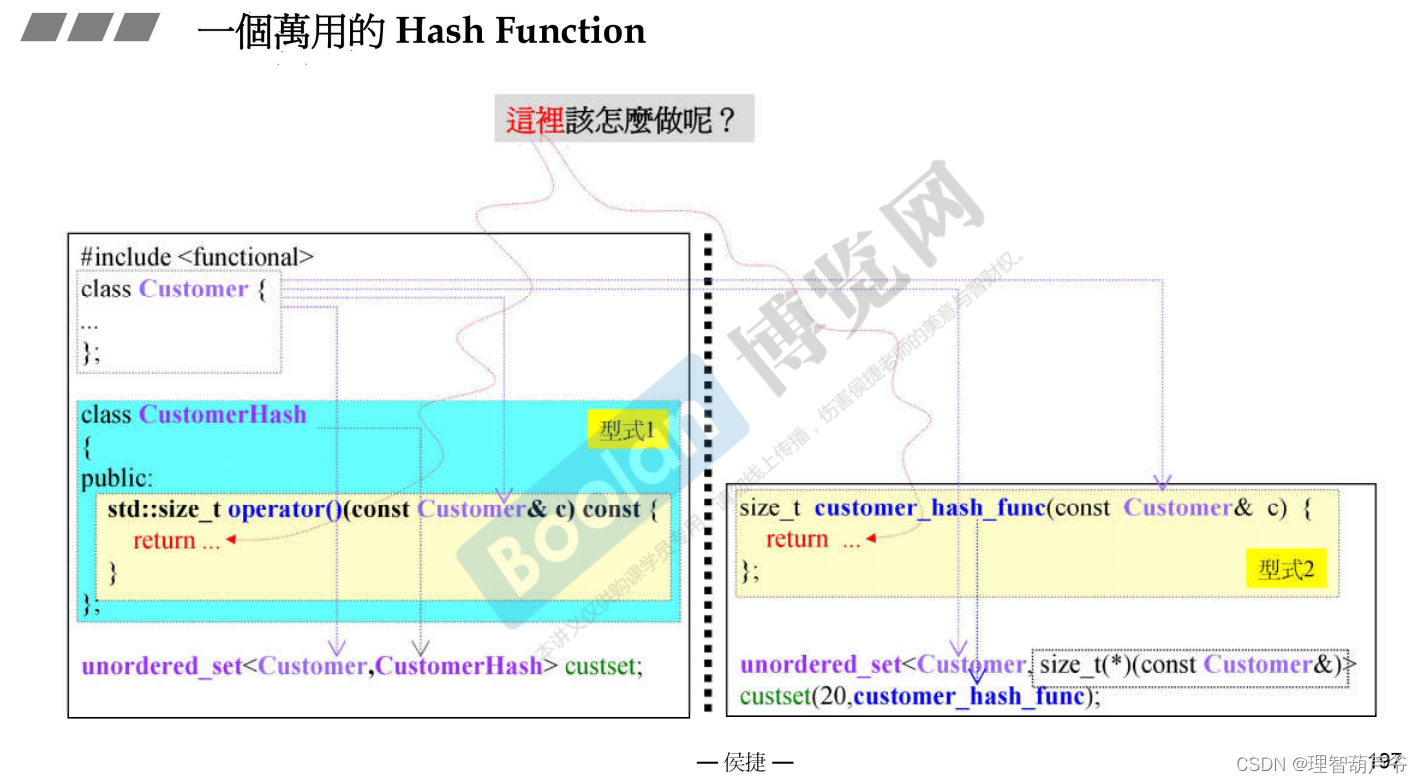
-
如何为一个含有多种类型的数据成员的类构建一个Hash Function?
一个可行的方法是对每个数据成员按类型进行hash再相加,但是这个方法太天真。
通用的方法是采用hash_val(),如图所示,这个函数有三个版本。typename… Types任意多的模板参数,可变参数模板。函数1和函数2,函数3的区别是第一个模板参数的类型不一样,虽然同名函数。从参数来看,先调用的是函数1,假设原来参数有8 个,产生一个种子(seed),即一个种子加8个参数。然后调用函数2,函数2将8个参数变成1+7,将这1个参数去变化种子,这时候就是种子+7个参数,然后递归调用,直到只剩最后一个值时,hash_val调用的是函数3,函数三再调用hash_combine,生成最后一个种子,即hash_code。hash_combine中0x9e3779b9这个数值是根据黄金比例得来的。
















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









