










相比较《大数据时代的IT架构设计》而言,这本书更具有项目搭建的指导性意见,全篇采用从实际项目中遇到的场景进行一步步的讲述,其中一有个观点特别认同,那就是如果想要学好软件架构,基于场景的学习才是最最有效的。因为在场景中我们可以看到架构能够解决哪些问题,哪些问题的解决来自哪些背后的原理。也就是作者提倡的,先不用管什么是架构,而是去思考它能解决什么样的问题,要处理什么样的场景。作者15年深耕,在字里行间时刻能感受到他的技术功底,值得大家一品。
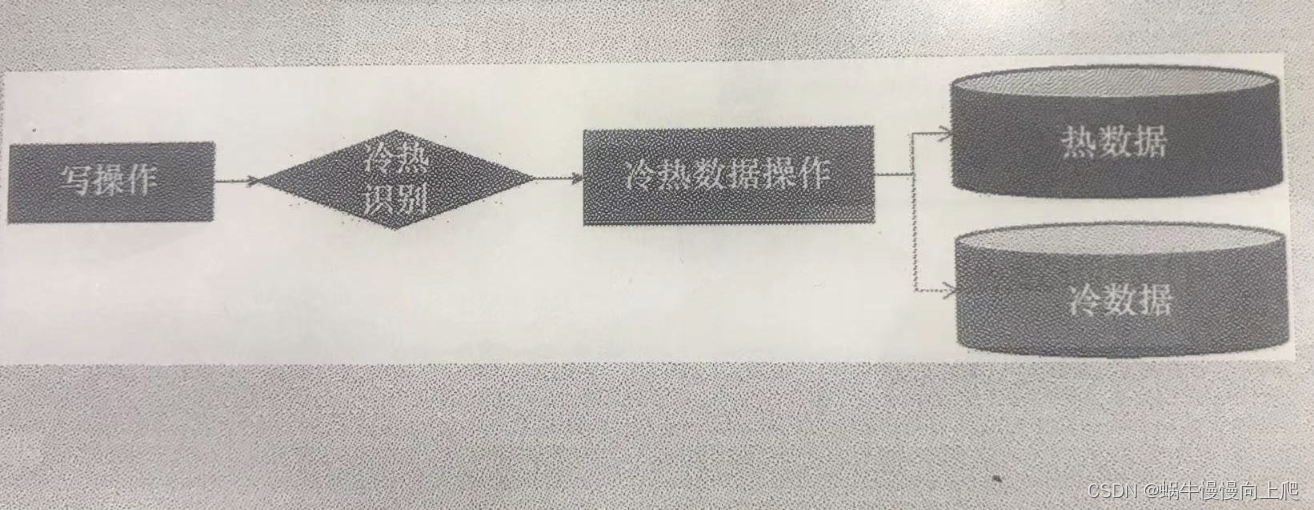
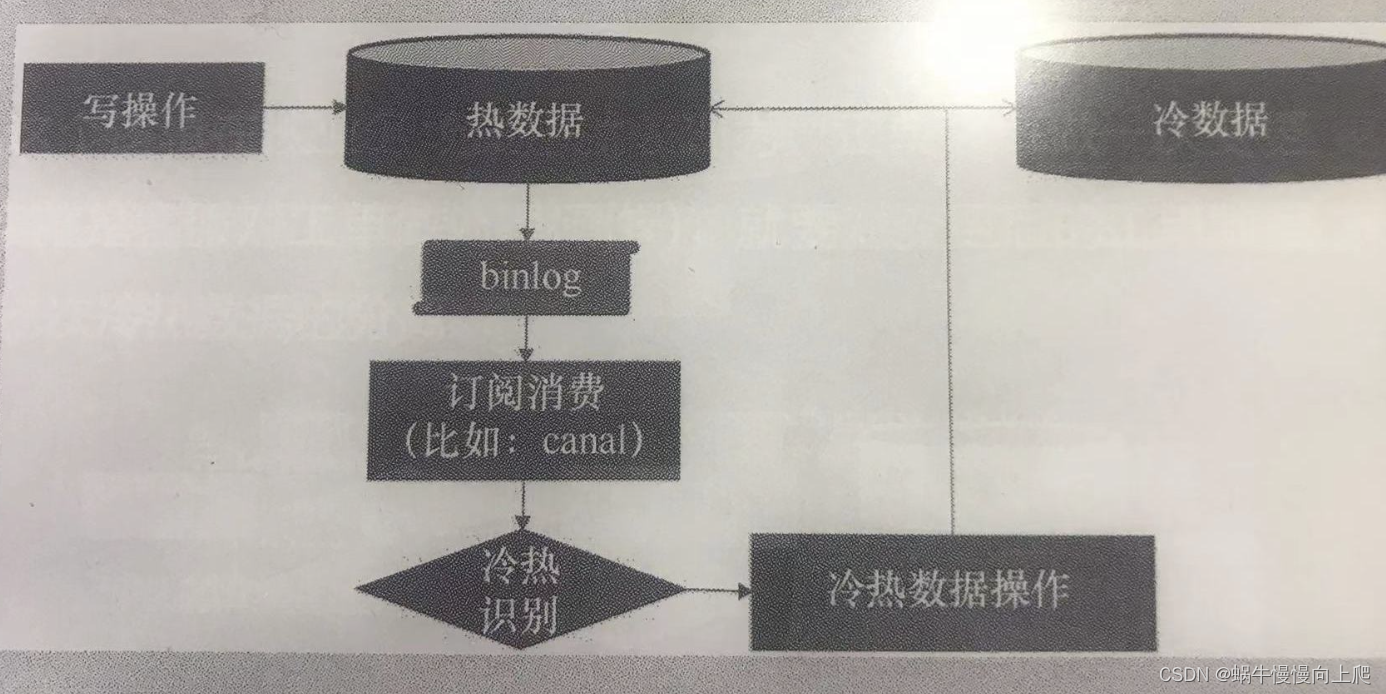
在第1部分主要讲了数据持久化层场景实战,分别从三个方面来说,冷热分离、查询分离、分表分库。业务场景是几千万数据量的工单表如何快速优化。首先想到是的数据库分区,将表的数据均衡分配到不同的硬盘、系统或不同的服务器储存介质中,但是分区有个弊端,必须在where语句里面加上一个包含分区字段的条件,根据实际在用的sql,并不包含相同的字段。因为分区是有限制的,分区字段必须是唯一索引(主键也是唯一索引)的一部分,无论使用什么当分区字段,都必须把它加到主键当中,形成复合主键。由于修改sql需要涉及业务核心sql的更改,且工期1周时间,因为方案放弃。最终使用熟悉的技术,冷热分离来实现。说下作者的思路:新建一个数据库,然后将1个月前已经完结的工单数据都移动到这个新的数据库。这个数据库就叫冷库,之后极少被访问。当前的数据库保留正常处理的较新的工单数据,这个是热库。这样处理后,近期常用的只有300万条,性能就基本没问有问题了。
以下为几种冷热分离的作法思路:

















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











