







1、豆瓣简介
豆瓣是一个社交网站,起源于2005年,该网站以书影音起家,提供关于图书、电影、音乐唱片的推荐、评价和价格比较,以及城市独特的文化生活。本篇文章将从数据分析的角度来分析豆瓣网站。分析的维度有书籍,书籍类目,书评,电影,电影类型,影评,音乐,音乐类型,音频,还有豆瓣产品介绍等等.....
本篇文章将以豆瓣电影Top250排行来简要介绍爬虫技术和豆瓣电影

2、爬虫开启
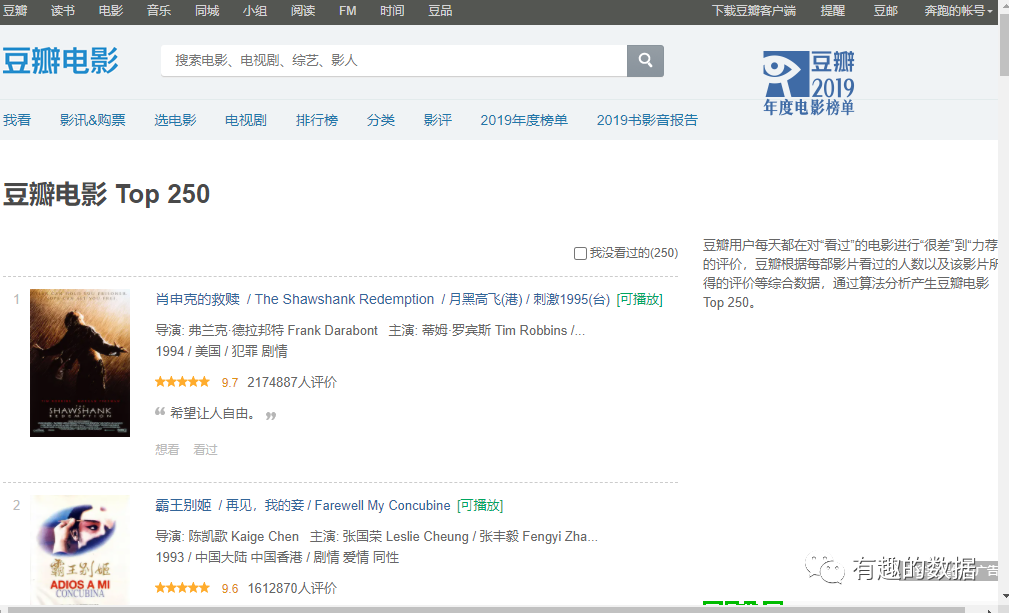
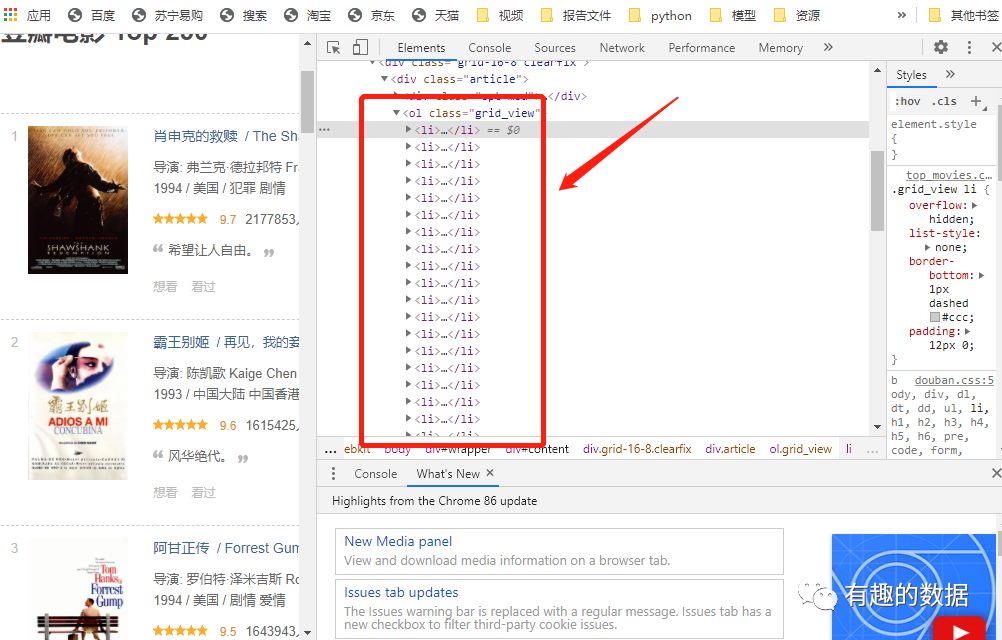
需要爬取的网站页面如下所示,本次爬取的字段包含有排行,海报,电影名,演员,评分,评价人数,电影简介,爬取使用的库为requests,使用的解析方式是bs4,xpath,jquery,re多个模块库来解析页面。
(1)爬虫准备
import requestsfrom fake_useragent import UserAgentfrom lxml import etreefrom bs4 import BeautifulSoupfrom pyquery import PyQuery as pqimport reimport csv
(2)xpath解析
def get_parse(result):res= etree.HTML(result)items=res.xpath('//ol[@class="grid_view"]/li')for item in items:rank=item.xpath('.//div[@class="pic"]/em/text()')[0]haibao=item.xpath('.//div[@class="pic"]/a/img/@src')[0]name=item.xpath('.//div[@class="hd"]/a/span[1]/text()')[0]actor=item.xpath('.//div[@class="bd"]/p/text()')[0]pingfen=item.xpath('.//div[@class="star"]/span[2]/text()')[0]pingjia=item.xpath('.//div[@class="star"]/span[4]/text()')[0]jianjie=item.xpath('.//p[@class="quote"]/span/text()')[0]print(rank,haibao,name,actor,pingfen,pingjia,jianjie)
(3)bs4解析
# bs4解析def get_parse1(result):soup = BeautifulSoup(result,'lxml')items=soup.select('ol>li')for item in items:rank=item.select('.pic em')[0].stringhaibao=item.select('.pic>a>img')[0]['src']name=item.select('.hd>a>span')[0].stringactor=item.select('.bd>p')[0].textpingfen=item.select('.star>span')[1].stringpingjia=item.select('.star>span')[3].stringjianjie=item.select('.quote span')[0].stringprint(rank,haibao,name,actor,pingfen,pingjia,jianjie)
(4)jQuery解析
# jquery解析def get_parse3(result):doc=pq(result)# 遍历操作,使用item()方法,会得到一个生成器items=doc('ol>li').items()for item in items:rank=item.find('.pic em').text()haibao=item.find('.pic>a>img').attr('src')name=item.find('.hd>a>span').text()actor=item.find('.bd>p').text()pingfen=item.find('.star>span').eq(1).text()pingjia=item.find('.star>span').eq(3).text()jianjie=item.find('.quote span').text()print(rank,haibao,name,actor,pingfen,pingjia,jianjie)
(5)re解析
def get_parse2(result):
regex = '<em class="">(\d+)</em>.*?<span class="title">(.*?)</span>.*?<p class="">(.*?)</p>.*?<span class="rating_num" property="v:average">(.*?)</span>.*?<span>(.*?)</span>.*?<span class="inq">(.*?)</span>'
pattern=re.compile(regex,re.S)
items=re.findall(pattern,result)
# print(items)
for item in items:
content=""
# 通过空格进行切片处理
for i in item[2].split():
content=content+"".join(i)
# 去除字符串中的 和换行符
content = re.sub(' ', ' ', content)
content = re.sub('<br>', ' ', content)
print(item[0],item[1],content,item[3],item[4],item[5])
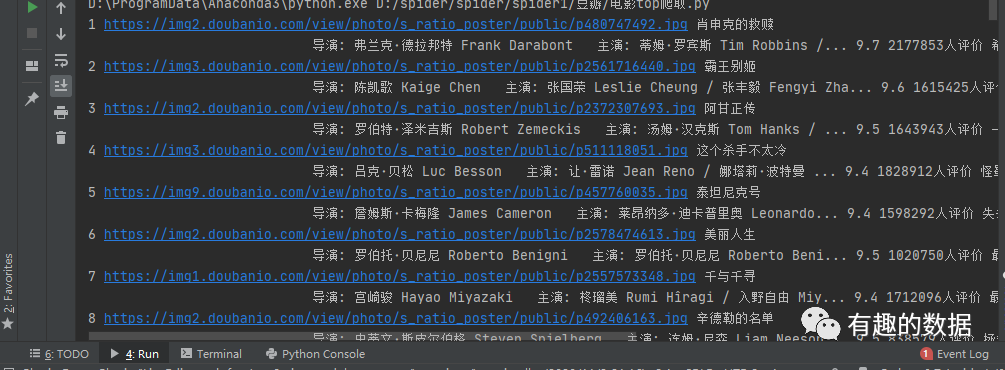
(6)结果展示
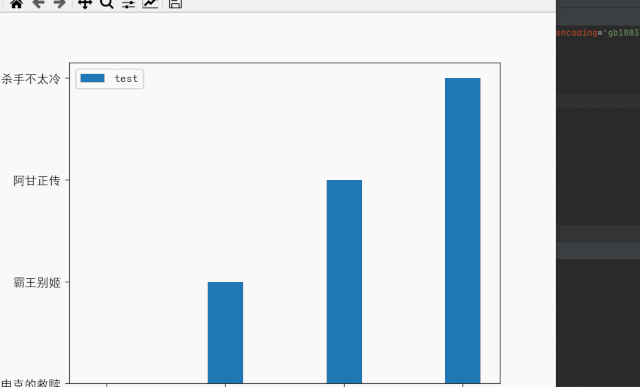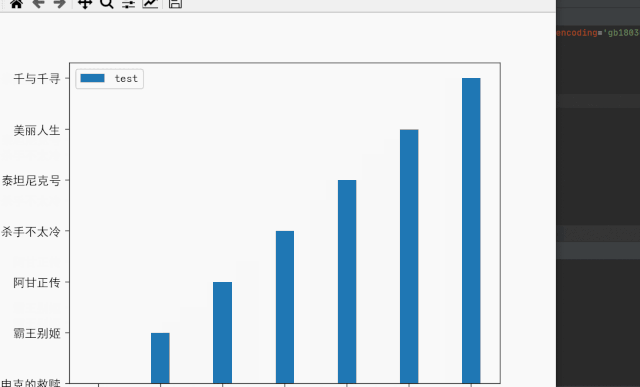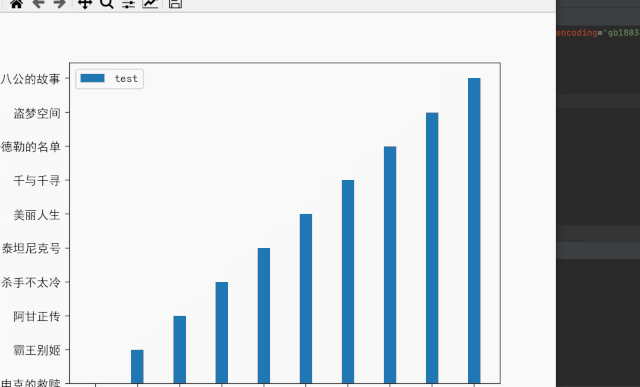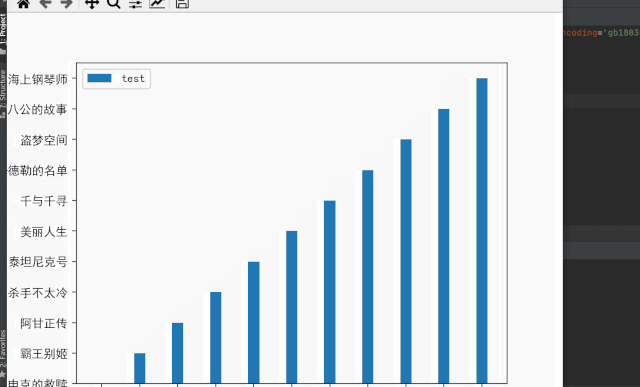
更多精彩内容:关注公众号【有趣的数据】















 3136
3136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









