










 Riffusion 是一个用于实时音乐和音频生成且具有稳定扩散的库。让你说的每句话都能成为一段美妙的音乐!不信,你往下看!
Riffusion 是一个用于实时音乐和音频生成且具有稳定扩散的库。让你说的每句话都能成为一段美妙的音乐!不信,你往下看!
// 免费体验地址
https://www.riffusion.com/提示词
1. Baby when you talk like that, you make a woman go mad. So be wise and keep on
宝贝,当你这样说话时,你会让女人发疯。所以要明智并坚持下去
2. When the night has come and the land is dark and that moon is the only
当夜幕降临,大地漆黑,只有月亮
,时长00:11
3. Oh where are you from? You're dressed kinda strange. Well this is very natural in San Francisco
哦,你来自哪里?你穿得有点奇怪。这在旧金山是很自然的事
,时长00:11
这是 Riffusion图像和音频处理代码的核心存储库。
-
结合图像调节执行快速插值的扩散管道
-
频谱图图像和音频剪辑之间的转换
-
用于常见任务的命令行界面
-
使用streamlit的交互式应用程序
-
Flask 服务器通过 API 提供模型推理
-
各种第三方集成
相关存储库:
//网络应用程序:https: //github.com/riffusion/riffusion-app//模型检查点:https://huggingface.co/riffusion/riffusion-model-v1// 源代码https://github.com/riffusion/riffusion

附加:算法简介
频谱图
-
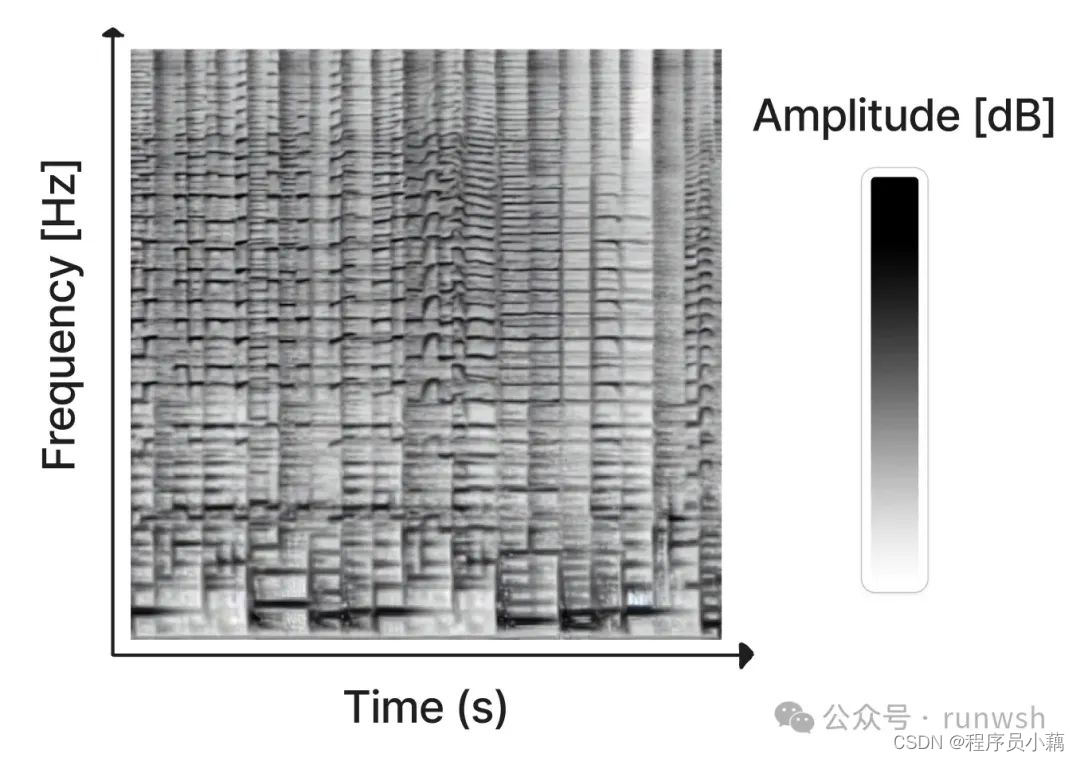
介绍 Riffusion 之前需要先引入一个音频处理领域非常常用的一个工具——频谱图
-
音频频谱图是一种表示声音片段频率内容的视觉方式。x 轴表示时间,y 轴表示频率。每个像素的颜色给出了音频在其行和列给出的频率和时间下的振幅。
-
可以使用短时傅里叶变换 (STFT) 从音频计算频谱图,该变换将音频近似为不同振幅和相位的正弦波的组合。

算法流程
-
STFT 是可逆的,因此可以从频谱图重建原始音频。
-
Riffusion 巧妙的将文本生成音频的任务转换为一个文本生成频谱图像任务,从而可以使用 Stable Diffusion 的预训练模型进行微调
-
具体来讲,使用微调完成的 Stable Diffusion 模型将输入的文本提示转换为频谱图像,然后基于生成的频谱图重建音频就可以实现文本提示生成音频的功能了
-
输入提示词:funk bassline with a jazzy saxophone solo
-
输入 Stable Diffusion 模型,迭代生成频谱图:
-



















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











