






边缘设备(如手机)因内存和计算能力有限,运行RAG面临巨大挑战;
例如:一个存储了523万条记录的向量数据库的索引大小为18.5 GB,而手机通常只有4-12 GB的主内存。
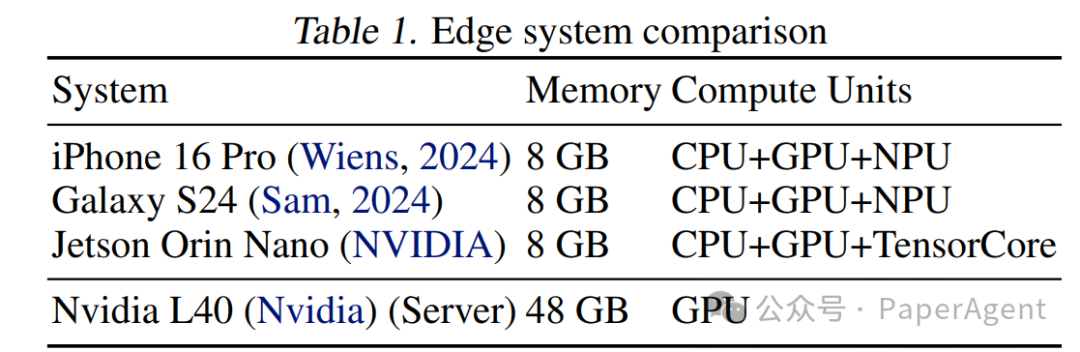
RAG的Pipeline
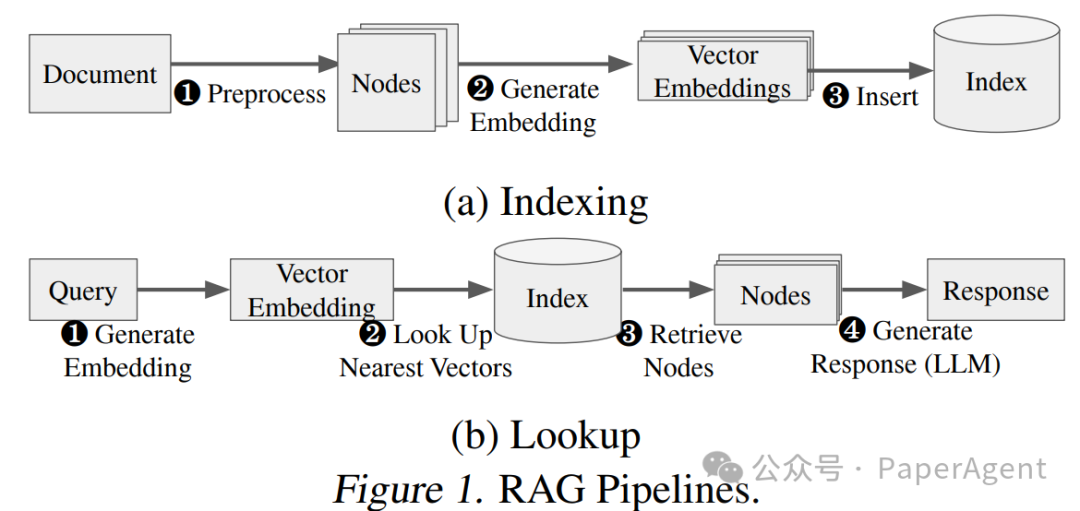
因此,谷歌等提出一种EdgeRAG系统:通过选择性存储,不是所有向量都存储,只有在检索过程中真正需要的嵌入向量才会被生成和存储,此外,还采用自适应缓存策略,以减少冗余计算并进一步优化延迟。
EdgeRAG索引过程
-
数据预处理与聚类:文本语料库被分割成较小的数据块,为每个数据块生成嵌入向量,然后进行聚类。聚类中心被存储在第一级索引中.
-
嵌入向量的存储决策:对于每个聚类中的数据块,计算生成嵌入向量的成本。如果成本超过预定义的服务级别目标(SLO),则存储整个数据块的嵌入向量;否则,丢弃嵌入向量以优化存储.
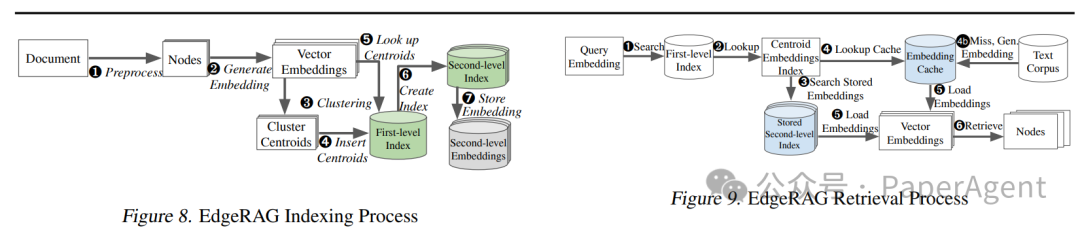
EdgeRAG检索过程
-
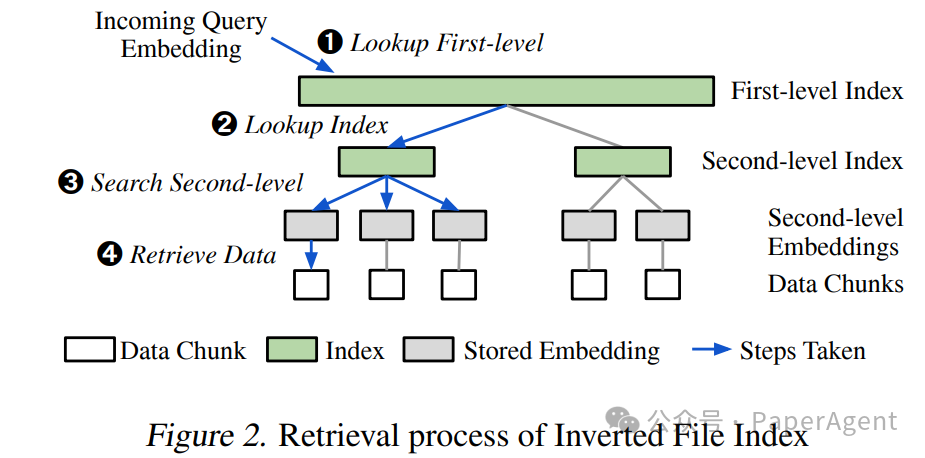
查找最相似的聚类中心:首先识别与查询嵌入向量最相似的聚类中心.
-
嵌入向量的获取:检查是否已预计算并存储了该聚类的嵌入向量。如果存在,则加载这些嵌入向量;如果不存在,则查找嵌入缓存。如果缓存命中,则加载缓存中的嵌入向量;如果缓存未命中,则重新生成嵌入向量并更新缓存.
-
数据块的检索:查找最接近的匹配嵌入向量,并检索相关的数据块.
EdgeRAG插入与删除
-
插入过程:新添加的数据块会被分配到最近的聚类中心,并更新相应的索引。如果更新后的聚类嵌入向量的生成成本超过SLO,则重新生成并存储嵌入向量.
-
删除过程:首先定位相应的聚类,然后移除相关嵌入向量,并更新聚类索引。如果生成嵌入向量的成本低于SLO,则可以删除整个聚类的嵌入向量.
平台与数据集:在Nvidia Jetson Orin Nano平台上进行评估,使用了来自BEIR基准测试套件的六个数据集.
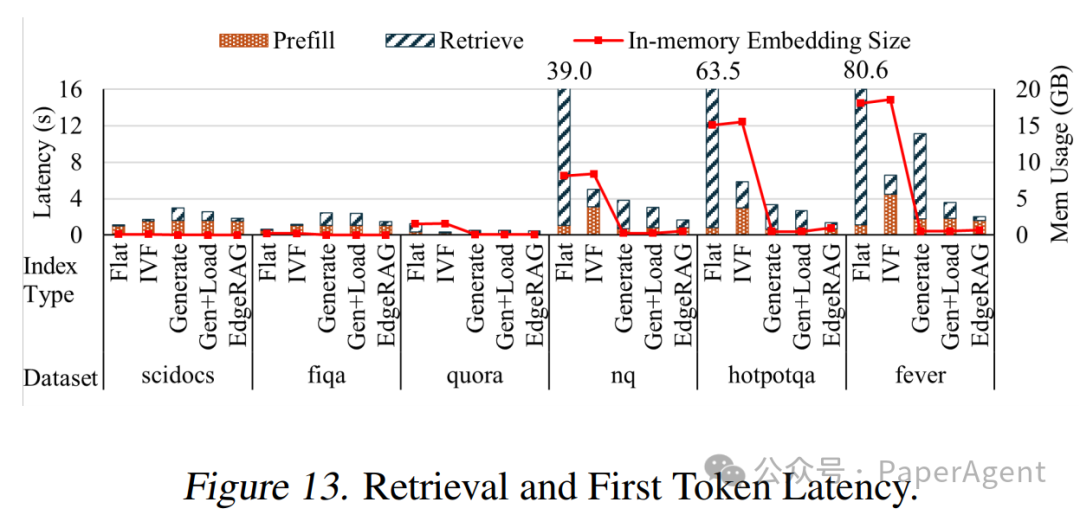
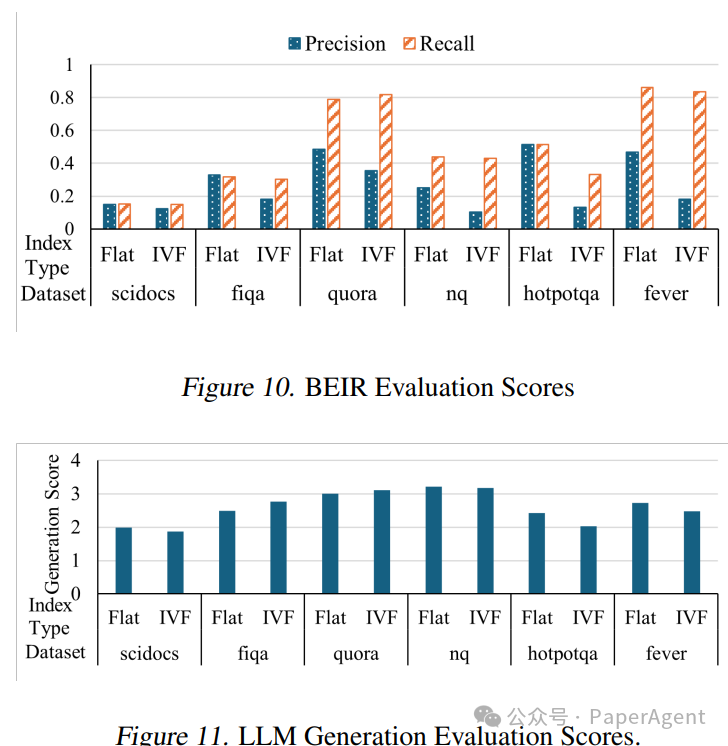
EdgeRAG在时间到第一个标记(TTFT)延迟方面比基线IVF索引平均快1.8倍,对于大型数据集则快3.82倍。同时,EdgeRAG在保持与平面索引基线相似的生成质量的同时(仅有 5% 以内的差异),允许所有评估的数据集适应内存并避免内存抖动.
https://arxiv.org/pdf/2412.21023EdgeRAG: Online-Indexed RAG for Edge Devices
来源 | PaperAgent


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









