



大型推理模型(LRMs)过度冗长的思考过程在token消耗和延迟方面带来了巨大的开销,尤其是对于简单查询来说,这种思考过程往往是不必要的。

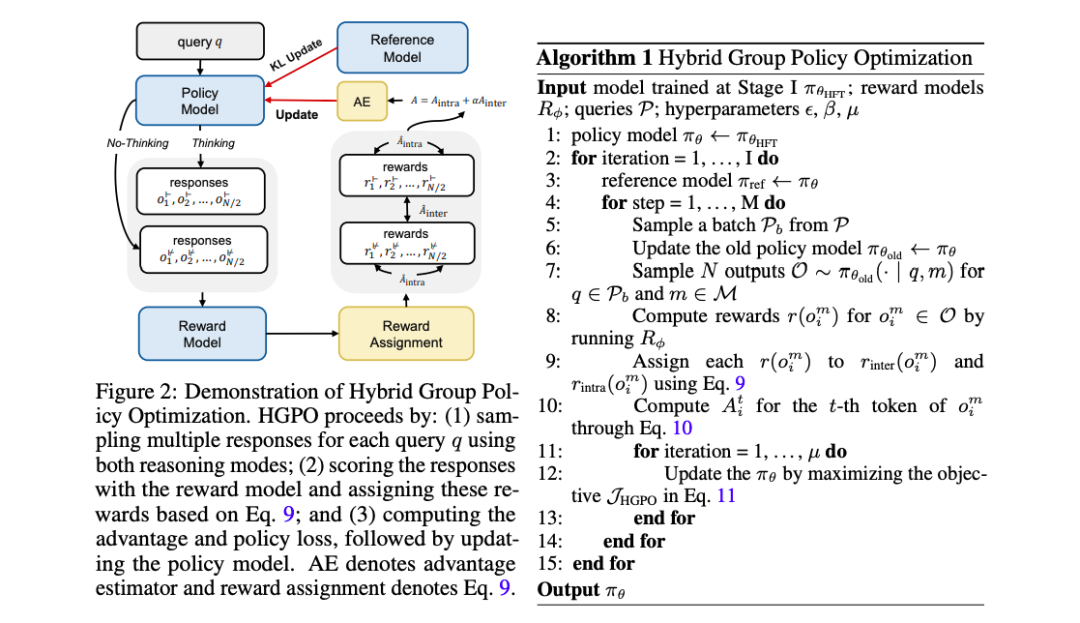
微软研究院&北大提出了大型混合推理模型(LHRMs),这是第一种能够根据用户查询的上下文信息自适应地决定是否进行思考的模型。为了实现这一目标,提出了一种包含两个阶段的训练流程:以混合微调(HFT)作为冷启动,随后通过提出的混合群体策略优化(HGPO)进行在线强化学习,以隐式地学习选择合适的思考模式。
Qwen2.5-7B-Instruct、DeepSeek-R1-Distill-Qwen-7B以及LHRMs-7B在推理相关任务(上)和日常问答任务(下)中的示例回答,LHRMs能够自适应地决定何时进行思考,在保持强大推理能力的同时,实现了更快、更自然的日常交互。

第一阶段:混合微调
-
数据构建:混合微调数据集包含推理密集型(思考模式)和直接回答(无思考模式)的样本。思考模式的数据集包括高质量的数学、代码和科学问题,而无思考模式的数据集则包含简单的查询。
-
优化目标:HFT 的目标是基于上下文预测下一个标记。
第二阶段:混合群体策略优化
-
采样策略:对于每个查询 q,从旧策略中分别使用两种推理模式采样 N 个候选响应奖
-
励评分和分配:使用奖励函数对每个候选输出进行评分,并根据平均奖励值分配二进制奖励,以捕获不同推理模式之间的相对质量和每个推理模式内的答案质量。
-
优势估计:使用 GRPO 作为默认优势估计器,计算每个响应的最终每标记优势。
-
优化目标:HGPO 通过最大化以下目标函数来优化策略模型,该函数结合了奖励和策略更新的约束。
评估混合思考能力
-
混合准确率(Hybrid Accuracy, HAcc):提出一个新的评估指标 HAcc,用于衡量模型在不同任务中正确选择适当推理模式的能力。通过比较模型选择的推理模式与基于奖励模型评分的“真实”推理模式的一致性来计算 HAcc。
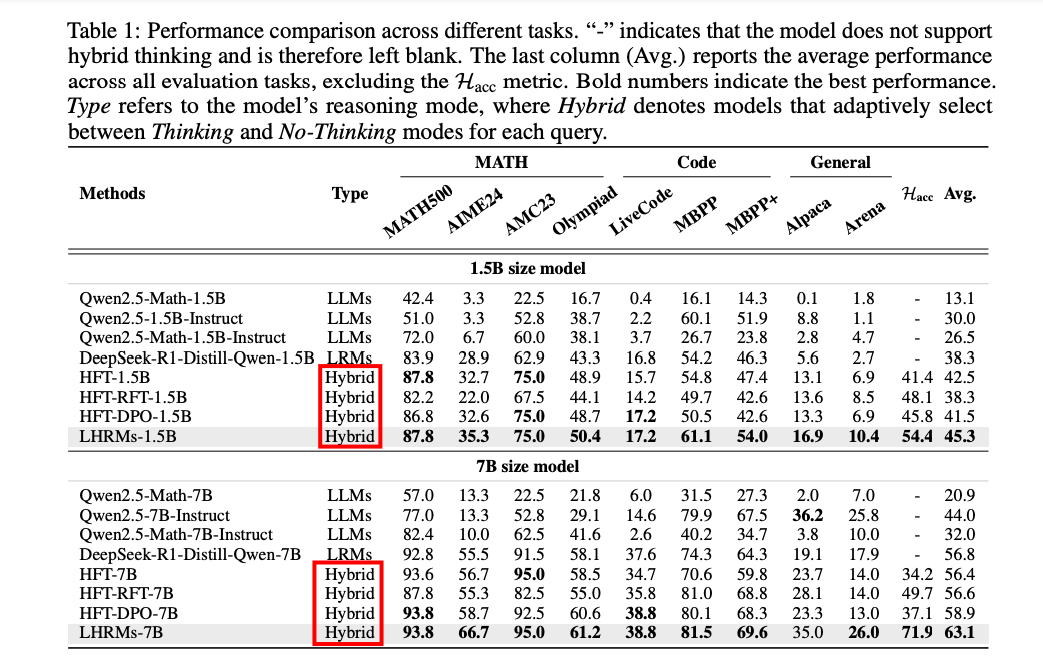
实验结果显示(1.5B 和 7B),LHRMs能够自适应地对不同难度和类型的查询进行混合思考。它在推理和通用能力方面超越了现有的LRMs和LLMs,同时显著提高了效率。

https://arxiv.org/pdf/2505.14631Think Only When You Need with Large Hybrid-Reasoning Models
来源 | PaperAgent


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









